Today, I installed Openstack with CentOS7 RDO, and the documentation says that I have to disable NetworkManager and use the network service to do so.
But when I start with the service network start command, I get the following error.
[root@localhost network-scripts]# service network start
Starting network (via systemctl): Job for network.service failed. See ‘systemctl status network.service’ and ‘journalctl -xn’ for details.[FAILED][root@localhost network-scripts]# systemctl status network.servicenetwork.service – LSB: Bring up/down networking Loaded: loaded (/etc/rc.d/init.d/network) Active: failed (Result: exit-code) since Sat 2015-03-07 02:53:12 EST; 6s ago Process: 8596 ExecStart=/etc/rc.d/init.d/network start (code=exited, status=1/FAILURE)Mar 07 02:53:12 localhost.localdomain network[8596]: RTNETLINK answers: File …Mar 07 02:53:12 localhost.localdomain network[8596]: RTNETLINK answers: File …Mar 07 02:53:12 localhost.localdomain network[8596]: RTNETLINK answers: File …Mar 07 02:53:12 localhost.localdomain network[8596]: RTNETLINK answers: File …Mar 07 02:53:12 localhost.localdomain network[8596]: RTNETLINK answers: File …Mar 07 02:53:12 localhost.localdomain network[8596]: RTNETLINK answers: File …Mar 07 02:53:12 localhost.localdomain systemd-sysctl[8913]: Overwriting earli…Mar 07 02:53:12 localhost.localdomain systemd[1]: network.service: control pr…Mar 07 02:53:12 localhost.localdomain systemd[1]: Failed to start LSB: Bring …Mar 07 02:53:12 localhost.localdomain systemd[1]: Unit network.service entere…Hint: Some lines were ellipsized, use -l to show in full.
Then search online because it did not add HWADDR …. I did delete this one ….
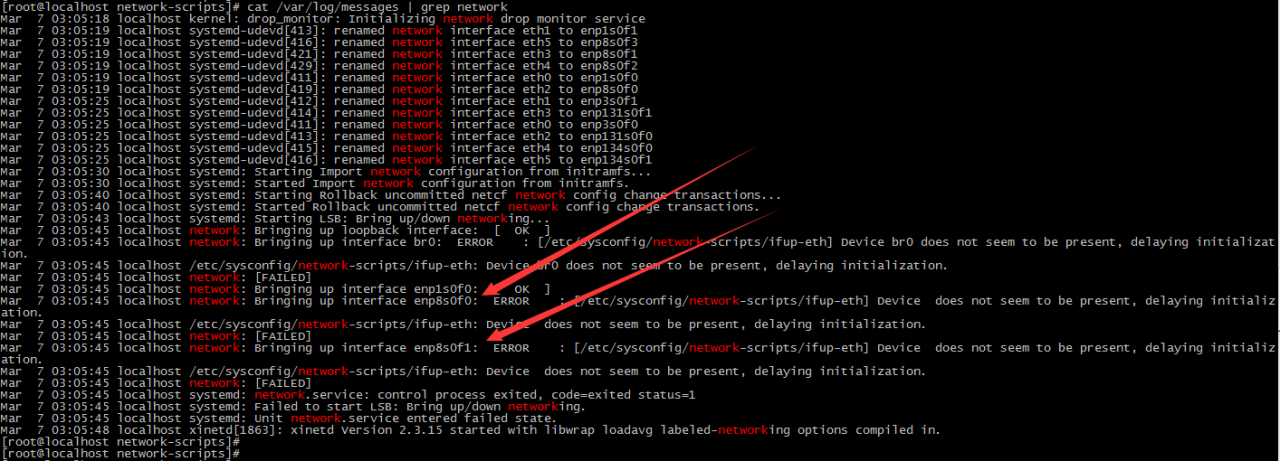
First, look at the log that says which NIC is not UP.
[root@localhost network-scripts]# cat /var/log/messages | grep network
Mar 7 03:05:18 localhost kernel: drop_monitor: Initializing network drop monitor serviceMar 7 03:05:19 localhost systemd-udevd[413]: renamed network interface eth1 to enp1s0f1Mar 7 03:05:19 localhost systemd-udevd[416]: renamed network interface eth5 to enp8s0f3Mar 7 03:05:19 localhost systemd-udevd[421]: renamed network interface eth3 to enp8s0f1Mar 7 03:05:19 localhost systemd-udevd[429]: renamed network interface eth4 to enp8s0f2Mar 7 03:05:19 localhost systemd-udevd[411]: renamed network interface eth0 to enp1s0f0Mar 7 03:05:19 localhost systemd-udevd[419]: renamed network interface eth2 to enp8s0f0Mar 7 03:05:25 localhost systemd-udevd[412]: renamed network interface eth1 to enp3s0f1Mar 7 03:05:25 localhost systemd-udevd[414]: renamed network interface eth3 to enp131s0f1Mar 7 03:05:25 localhost systemd-udevd[411]: renamed network interface eth0 to enp3s0f0Mar 7 03:05:25 localhost systemd-udevd[413]: renamed network interface eth2 to enp131s0f0Mar 7 03:05:25 localhost systemd-udevd[415]: renamed network interface eth4 to enp134s0f0Mar 7 03:05:25 localhost systemd-udevd[416]: renamed network interface eth5 to enp134s0f1Mar 7 03:05:30 localhost systemd: Starting Import network configuration from initramfs…Mar 7 03:05:30 localhost systemd: Started Import network configuration from initramfs.Mar 7 03:05:40 localhost systemd: Starting Rollback uncommitted netcf network config change transactions…Mar 7 03:05:40 localhost systemd: Started Rollback uncommitted netcf network config change transactions.Mar 7 03:05:43 localhost systemd: Starting LSB: Bring up/down networking…Mar 7 03:05:45 localhost network: Bringing up loopback interface: [ OK ]Mar 7 03:05:45 localhost network: Bringing up interface br0: ERROR : [/etc/sysconfig/network-scripts/ifup-eth] Device br0 does not seem to be present, delaying initialization.Mar 7 03:05:45 localhost /etc/sysconfig/network-scripts/ifup-eth: Device br0 does not seem to be present, delaying initialization.Mar 7 03:05:45 localhost network: [FAILED]Mar 7 03:05:45 localhost network: Bringing up interface enp1s0f0: [ OK ]Mar 7 03:05:45 localhost network: Bringing up interface enp8s0f0: ERROR : [/etc/sysconfig/network-scripts/ifup-eth] Device does not seem to be present, delaying initialization.Mar 7 03:05:45 localhost /etc/sysconfig/network-scripts/ifup-eth: Device does not seem to be present, delaying initialization.Mar 7 03:05:45 localhost network: [FAILED]Mar 7 03:05:45 localhost network: Bringing up interface enp8s0f1: ERROR : [/etc/sysconfig/network-scripts/ifup-eth] Device does not seem to be present, delaying initialization.Mar 7 03:05:45 localhost /etc/sysconfig/network-scripts/ifup-eth: Device does not seem to be present, delaying initialization.Mar 7 03:05:45 localhost network: [FAILED]Mar 7 03:05:45 localhost systemd: network.service: control process exited, code=exited status=1Mar 7 03:05:45 localhost systemd: Failed to start LSB: Bring up/down networking.Mar 7 03:05:45 localhost systemd: Unit network.service entered failed state.Mar 7 03:05:48 localhost xinetd[1863]: xinetd Version 2.3.15 started with libwrap loadavg labeled-networking options compiled in.
ip addr to view the MACs of these two NICs.
[root@localhost network-scripts]# ip addr
1: lo: mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever2: enp1s0f0: mtu 1500 qdisc mq master br0 state UP qlen 1000 link/ether 00:25:90:64:a9:30 brd ff:ff:ff:ff:ff:ff inet6 fe80::225:90ff:fe64:a930/64 scope link valid_lft forever preferred_lft forever3: enp1s0f1: mtu 1500 qdisc noop state DOWN qlen 1000 link/ether 00:25:90:64:a9:31 brd ff:ff:ff:ff:ff:ff4: enp8s0f0: mtu 1500 qdisc noop state DOWN qlen 1000 link/ether 00:0c:bd:05:4e:cc brd ff:ff:ff:ff:ff:ff5: enp8s0f1: mtu 1500 qdisc noop state DOWN qlen 1000 link/ether 00:0c:bd:05:4e:cd brd ff:ff:ff:ff:ff:ff6: enp8s0f2: mtu 1500 qdisc noop state DOWN qlen 1000 link/ether 00:0c:bd:05:4e:ce brd ff:ff:ff:ff:ff:ff7: enp8s0f3: mtu 1500 qdisc noop state DOWN qlen 1000 link/ether 00:0c:bd:05:4e:cf brd ff:ff:ff:ff:ff:ff
Then write the macs of the two NICs to the configuration file at
/etc/sysconfig/network-scripts/ifcfg-enp8s0f0
/etc/sysconfig/network-scripts/ifcfg-enp8s0f1
ADD:
HWADDR=00:0c:bd:05:4e:cc
Then restart network, and it’s OK!
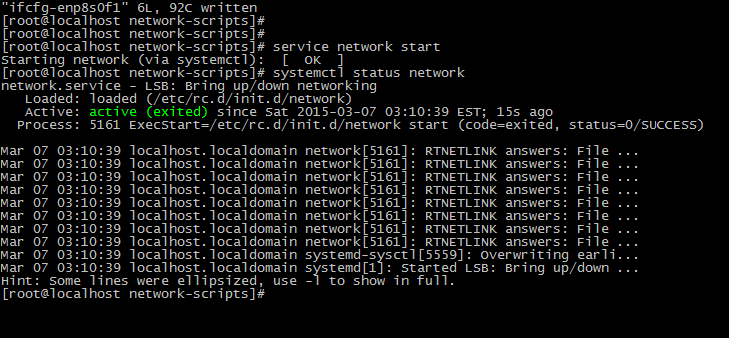
It’s been a long time since I’ve updated it. In fact, the problem is not necessarily a MAC problem, there are other possibilities. Here is another scenario.
CentOS7 in the virtual machine can’t be networked after reboot, restart network found error reported.
Solution: Disable NetworkManager
1. systemctl stop NetworkManager
2. systemctl disable NetworkManager
Then restart the network service and you can network normally!