For image classification tasks, a common choice for convolutional neural network (CNN) architecture is repeated blocks of convolution and max pooling layers, followed by two or more densely connected layers. The final dense layer has a softmax activation function and a node for each potential object category.
As an example, consider the VGG-16 model architecture, depicted in the figure below.
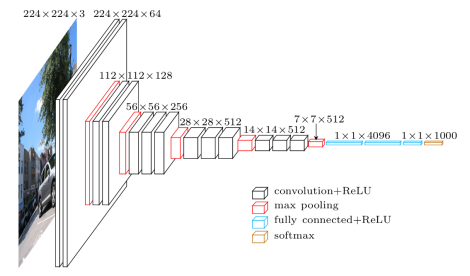
We can summarize the layers of the VGG-16 model by executing the following line of code in the terminal:
python -c 'from keras.applications.vgg16 import VGG16; VGG16().summary()'
Your output should appear as follows:
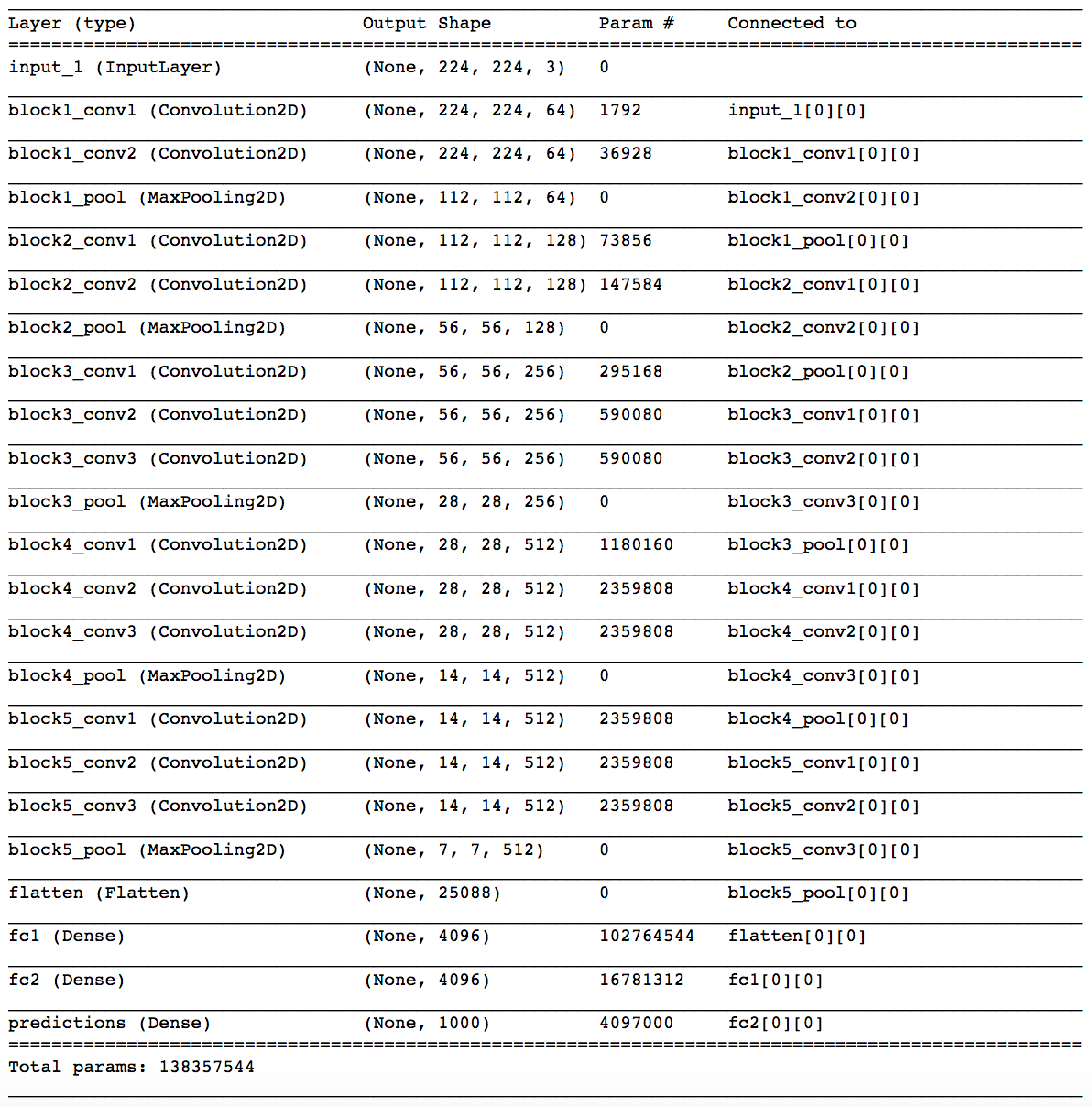
You will notice five blocks of (two to three) convolutional layers followed by a max pooling layer. The final max pooling layer is then flattened and followed by three densely connected layers. Notice that most of the parameters in the model belong to the fully connected layers!
As you can probably imagine, an architecture like this has the risk of overfitting to the training dataset. In practice, dropout layers are used to avoid overfitting.
Global Average Pooling
In the last few years, experts have turned to global average pooling (GAP) layers to minimize overfitting by reducing the total number of parameters in the model. Similar to max pooling layers, GAP layers are used to reduce the spatial dimensions of a three-dimensional tensor. However, GAP layers perform a more extreme type of dimensionality reduction, where a tensor with dimensionsh×w×dh×w×dis reduced in size to have dimensions1×1×d1×1×d. GAP layers reduce eachh×wh×wfeature map to a single number by simply taking the average of allhwhwvalues.
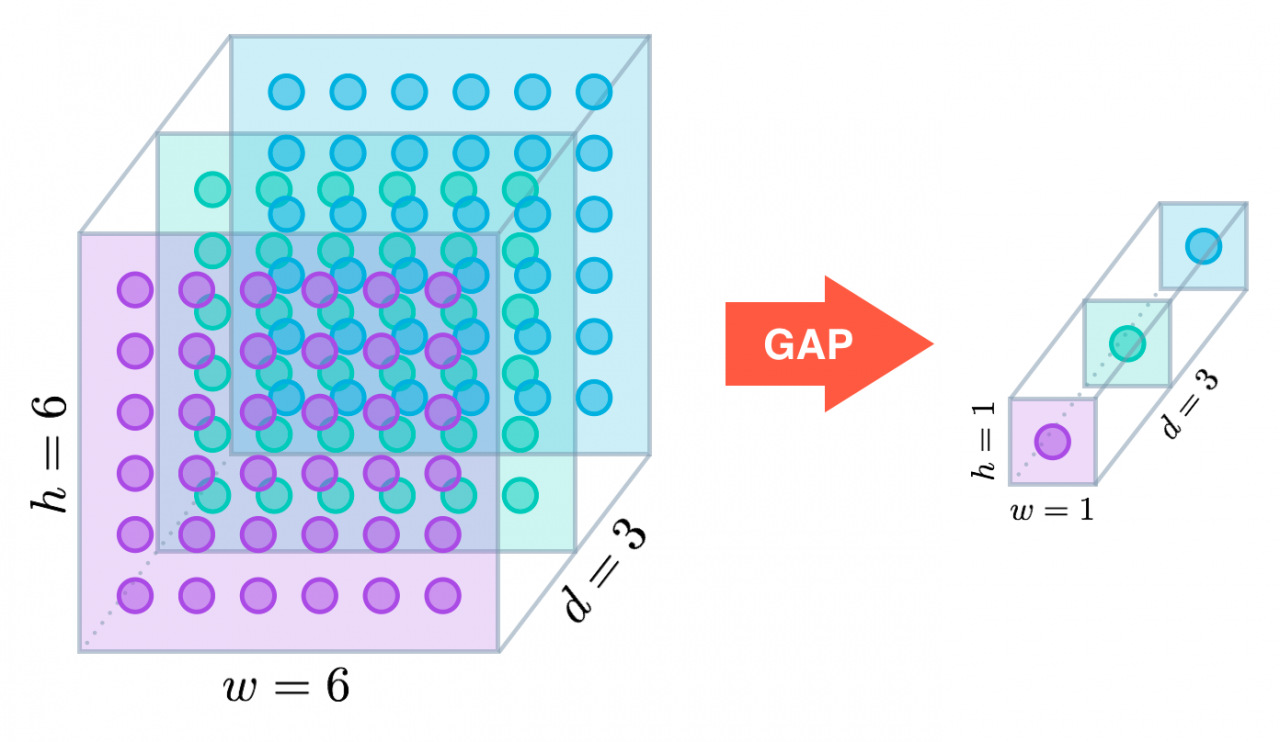
Thefirst paperto propose GAP layers designed an architecture where the final max pooling layer contained one activation map for each image category in the dataset. The max pooling layer was then fed to a GAP layer, which yielded a vector with a single entry for each possible object in the classification task. The authors then applied a softmax activation function to yield the predicted probability of each class. If you peek at theoriginal paper, I especially recommend checking out Section 3.2, titled “Global Average Pooling”.
TheResNet-50 modeltakes a less extreme approach; instead of getting rid of dense layers altogether, the GAP layer is followed by one densely connected layer with a softmax activation function that yields the predicted object classes.
Object Localization
In mid-2016,researchers at MITdemonstrated that CNNs with GAP layers (a.k.a. GAP-CNNs) that have been trained for a classification task can also be used forobject localization. That is, a GAP-CNN not only tells uswhatobject is contained in the image – it also tells uswherethe object is in the image, and through no additional work on our part! The localization is expressed as a heat map (referred to as aclass activation map), where the color-coding scheme identifies regions that are relatively important for the GAP-CNN to perform the object identification task. Please check out the YouTube video below for anawesomedemo!
In therepository, I have explored the localization ability of the pre-trained ResNet-50 model, using the technique fromthis paper. The main idea is that each of the activation maps in the final layer preceding the GAP layer acts as a detector for a different pattern in the image, localized in space. To get the class activation map corresponding to an image, we need only to transform these detected patterns to detected objects.
This transformation is done by noticing each node in the GAP layer corresponds to a different activation map, and that the weights connecting the GAP layer to the final dense layer encode each activation map’s contribution to the predicted object class. To obtain the class activation map, we sum the contributions of each of the detected patterns in the activation maps, where detected patterns that are more important to the predicted object class are given more weight.
How the Code Operates
Let’s examine the ResNet-50 architecture by executing the following line of code in the terminal:
python -c 'from keras.applications.resnet50 import ResNet50; ResNet50().summary()'
The final few lines of output should appear as follows (Notice that unlike the VGG-16 model, the majority of the trainable parameters are not located in the fully connected layers at the top of the network!):
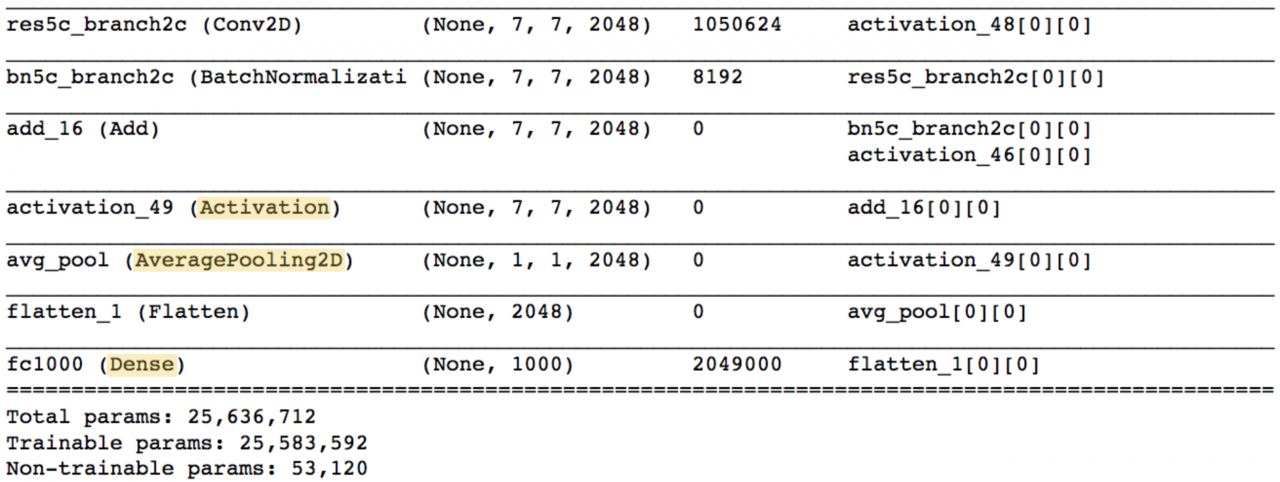
TheActivation,AveragePooling2D, andDenselayers towards the end of the network are of the most interest to us. Note that theAveragePooling2Dlayer is in fact a GAP layer!
We’ll begin with theActivationlayer. This layer contains 2048 activation maps, each with dimensions7×77×7. Letfkfkrepresent thekk-th activation map, wherek∈{1,…,2048}k∈{1,…,2048}.
The followingAveragePooling2DGAP layer reduces the size of the preceding layer to(1,1,2048)(1,1,2048)by taking the average of each feature map. The nextFlattenlayer merely flattens the input, without resulting in any change to the information contained in the previous GAP layer.
The object category predicted by ResNet-50 corresponds to a single node in the finalDenselayer; and, this single node is connected to every node in the precedingFlattenlayer. Letwkwkrepresent the weight connecting thekk-th node in theFlattenlayer to the output node corresponding to the predicted image category.
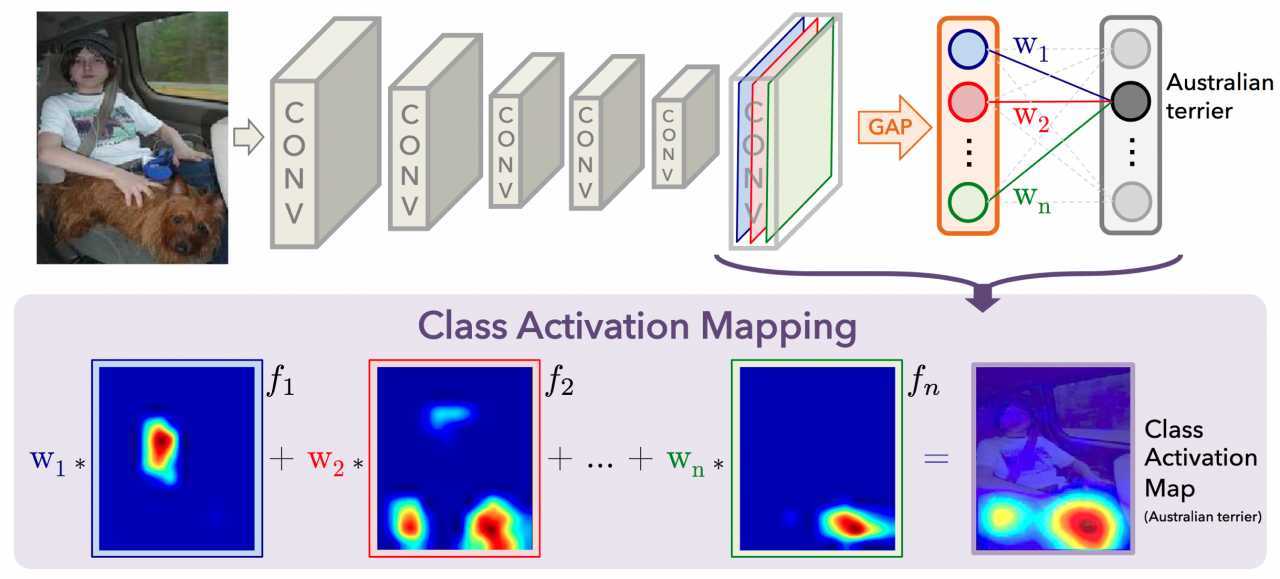
Then, in order to obtain the class activation map, we need only compute the sum
w1⋅f1+w2⋅f2+…+w2048⋅f2048w1⋅f1+w2⋅f2+…+w2048⋅f2048.
You can plot these class activation maps for any image of your choosing, to explore the localization ability of ResNet-50. Note that in order to permit comparison to the original image,bilinear upsamplingis used to resize each activation map to224×224224×224. (This results in a class activation map with size224×224224×224.)
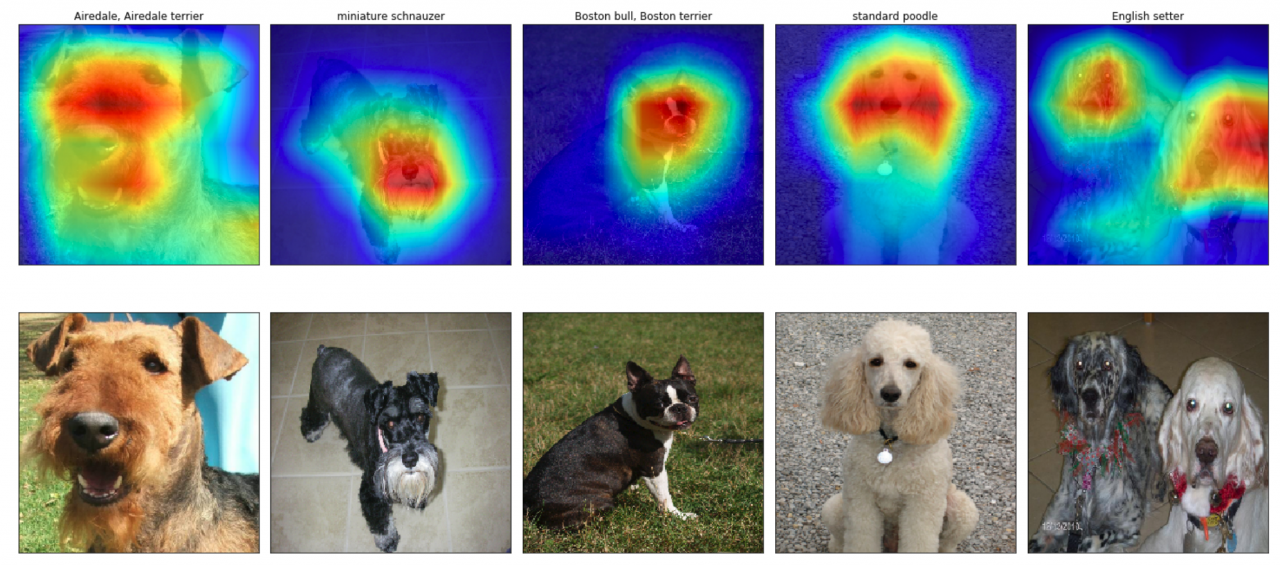
If you’d like to use this code to do your own object localization, you need only download therepository.
Similar Posts:
- Chinese character handwriting recognition based on densenetensorflow
- [Solved] module ‘keras.engine.topology’ has no attribute ‘load_weights_from_hdf5_group_by_name…
- How to Close the iframe Window opened by layui
- TensorFlow_CNN: tf.nn.max_pool VS tf.layers.max_pooling2d Parameters
- Note 32: yolov3: an incremental improvement
- [Solved] TensorFlow Error: InternalError: Failed copying input tensor
- Error: Unknown column ‘*_image_url’ in ‘field list’ [How to Solve]
- Name Error: name ‘yolo_head’ is not defined [How to Solve]
- Image has dependent child images [How to Solve]
- JS Uncaught TypeError: Cannot read property ‘toLowerCase’ of undefined