1. Problem description
When learning from books, I find that the data set downloaded from GitHub will report an error when reading with pandas:
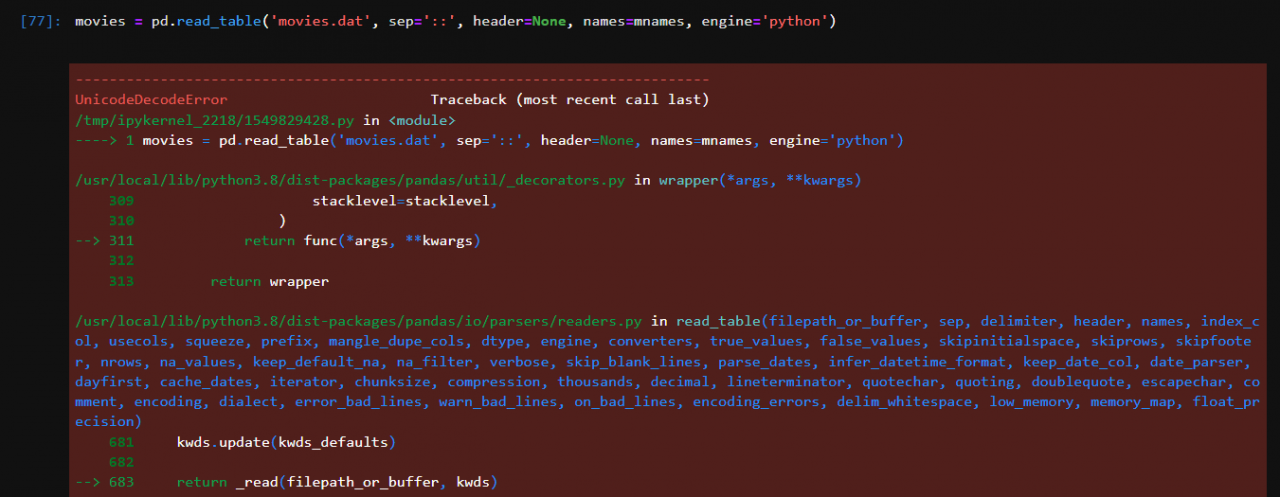
2. Solutions
It is obviously a coding problem. Use the file command to view the file code:

ISO-8859 the code in Python is iso-8859-1, which can be judged by the following function:
pip install chardet
def get_encoding(file):
with open(file, 'rb') as f:
return chardet.detect(f.read())['encoding']

Therefore, use the encoding parameter to specify the actual file format.
it’s fine too
movies = pd.read_table('movies.dat', encoding=get_encoding('movies.dat'), sep='::', header=None, names=mnames, engine='python')