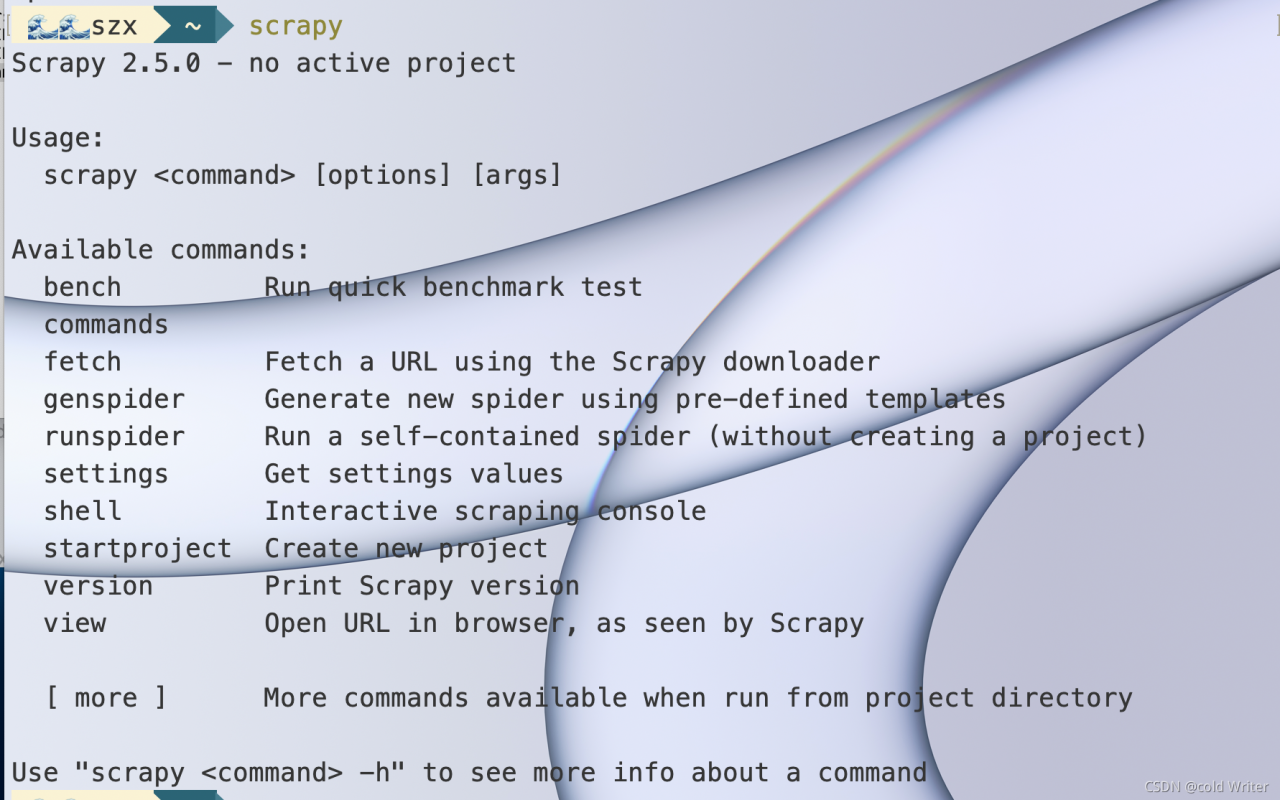
Background: originally, I planned to create a crawler project with scratch, but it showed Zsh: command not found: scratch . After reading many blogs, I solved the problem and decided to record it.
Main reference Blogs:
https://www.jianshu.com/p/51196153f804
https://stackoverflow.com/questions/17607944/scrapy-not-installed-correctly-on-mac
Problem analysis:
When I reinstall the script, I show:
WARNING: The script scrapy is installed in
'/Library/Frameworks/Python.framework/Versions/3.9/bin' which is not on PATH.
Consider adding this directory to PATH
or, if you prefer to suppress this warning, use --no-warn-script-location.
Note /library/frameworks/python.framework/versions/3.9/bin is not in the path. We need to add this path to the environment variable (consumer adding this directory to path).
terms of settlement:
Step 1: add source ~ /. Bash at the end of the. Zshrc file_ profile。
Open the finder, press Command + Shift + G, enter. Zshrc, open the. Zshrc file, and then write source ~ /. Bash at the end of the file_ profile。
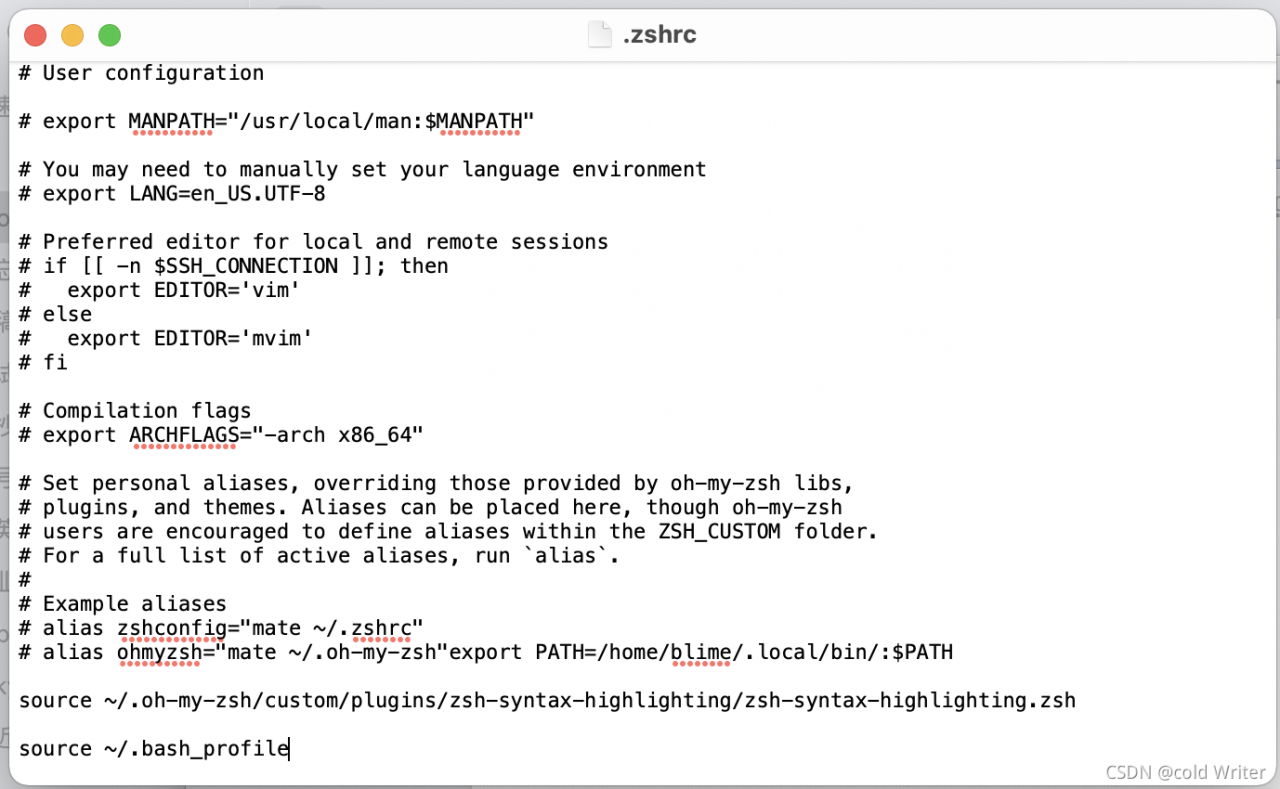
Press Command + s to save
Open the terminal, enter source ~ /. Zshrc , and execute the file.
Step 2: in. Bash_ Add environment variables to the profile file
Open the finder, press Command + Shift + G at the same time, and enter. Bash_ Profile, open. Bash_ Profile file.
Write on the last line:
export PATH="/Library/Frameworks/Python.framework/Versions/3.9/bin:$PATH"
be careful ⚠️: The number after versions is the python version number. It should be modified according to your own Python version. If the version is 2.7, it should be changed to:
export PATH="/Library/Frameworks/Python.framework/Versions/2.7/bin:$PATH"
Press Command + s to save.
Open the terminal and enter source ~ /. Bash_ Profile , execute the file.
Finally, you can enter echo $path on the terminal to see if the environment variable is added. 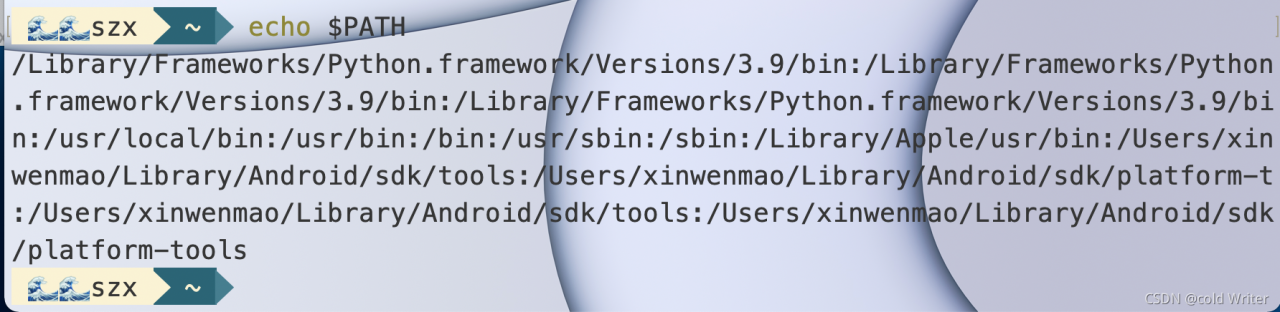
You can see that /library/frameworks/python.framework/versions/2.7/bin has been added ( and many ).
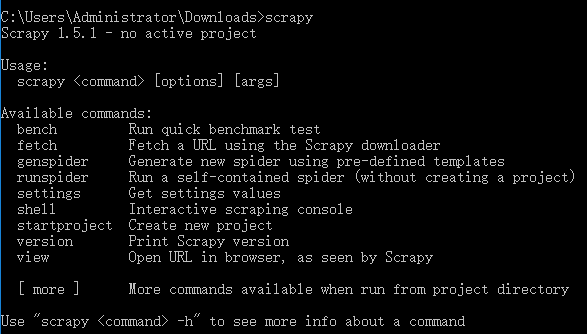
Finally, enter scapy and you can finally use it!!!