Idea remotely submits spark job Java io. IOException: Failed to connect to DESKTOP-H
1. Error report log
Exception in thread "main" java.lang.reflect.UndeclaredThrowableException
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1713)
at org.apache.spark.deploy.SparkHadoopUtil.runAsSparkUser(SparkHadoopUtil.scala:63)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.run(CoarseGrainedExecutorBackend.scala:188)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$.main(CoarseGrainedExecutorBackend.scala:293)
at org.apache.spark.executor.CoarseGrainedExecutorBackend.main(CoarseGrainedExecutorBackend.scala)
Caused by: org.apache.spark.SparkException: Exception thrown in awaitResult:
at org.apache.spark.util.ThreadUtils$.awaitResult(ThreadUtils.scala:205)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:75)
at org.apache.spark.rpc.RpcEnv.setupEndpointRefByURI(RpcEnv.scala:101)
at org.apache.spark.executor.CoarseGrainedExecutorBackend$$anonfun$run$1.apply$mcV$sp(CoarseGrainedExecutorBackend.scala:201)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:64)
at org.apache.spark.deploy.SparkHadoopUtil$$anon$2.run(SparkHadoopUtil.scala:63)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
... 4 more
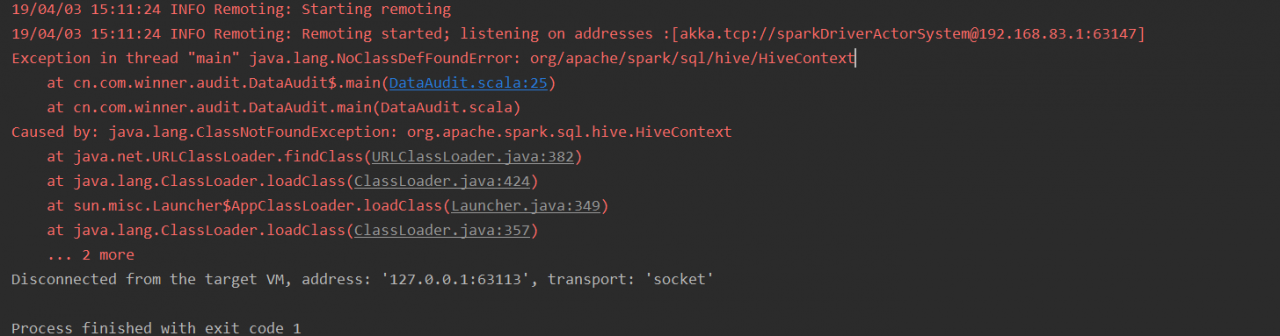
Caused by: java.io.IOException: Failed to connect to DESKTOP-HSVM
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:245)
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:187)
at org.apache.spark.rpc.netty.NettyRpcEnv.createClient(NettyRpcEnv.scala:198)
at org.apache.spark.rpc.netty.Outbox$$anon$1.call(Outbox.scala:194)
at org.apache.spark.rpc.netty.Outbox$$anon$1.call(Outbox.scala:190)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: io.netty.channel.AbstractChannel$AnnotatedConnectException: 拒绝连接: DESKTOP-HSVM
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:323)
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:340)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:633)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:580)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:497)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:459)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858)
at io.netty.util.concurrent.DefaultThreadFactory$DefaultRunnableDecorator.run(DefaultThreadFactory.java:138)
... 1 more
Caused by: java.net.ConnectException: denied to connect
... 11 more
2. cause analysis
Idea cannot establish a connection with the local machine while submitting spark jobs to the remote cluster and returning the results to the local machine.
Caused by: java.io.IOException: Failed to connect to DESKTOP-HSVM
3. solution
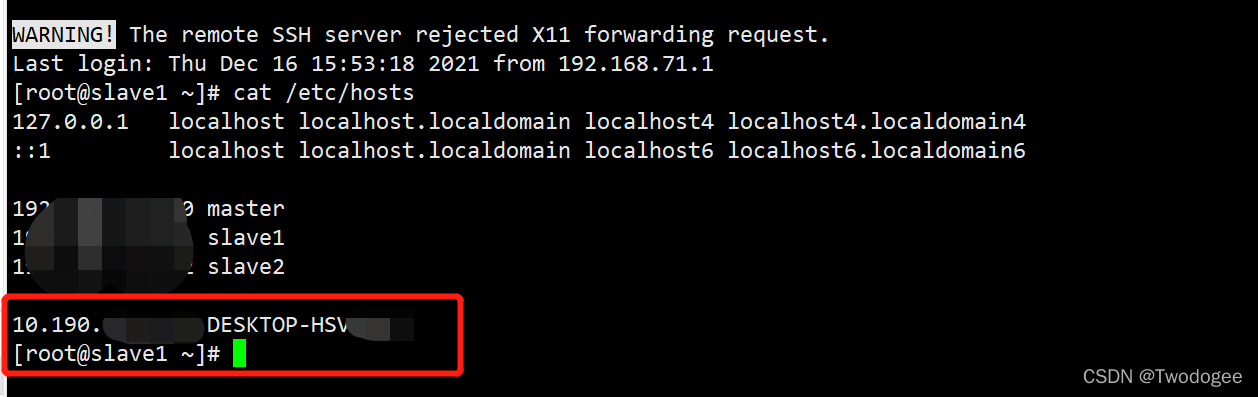
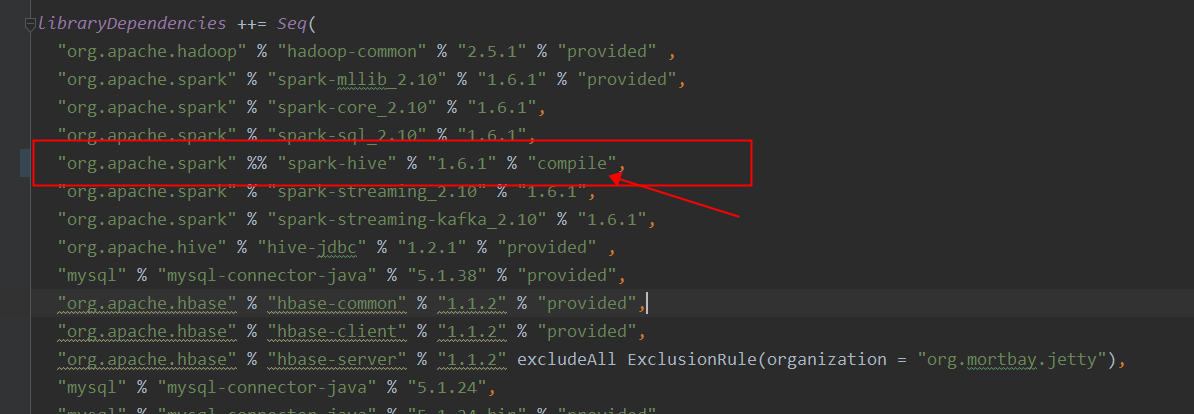
Add the native name desktop-hsvm and IP to the/etc/hosts file of the remote cluster, as shown in the following figure