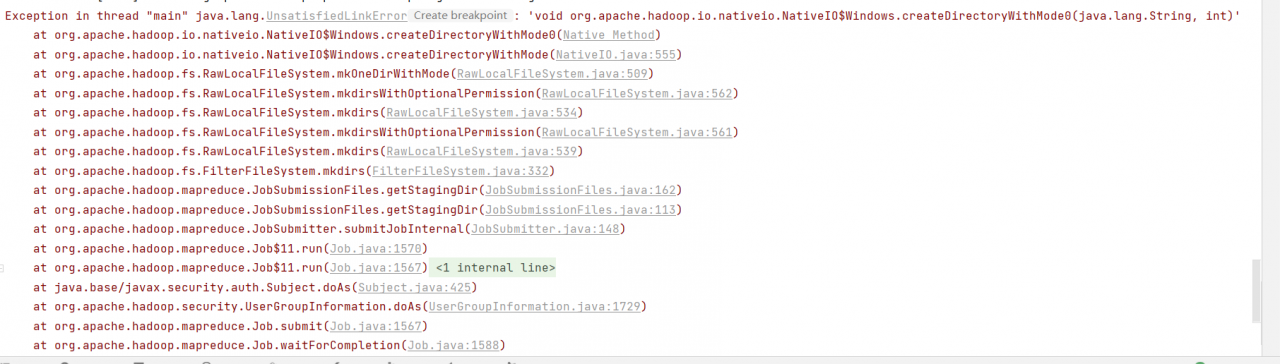
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://192.168.25.128:9000/export/yang/log.1 at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323) at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265) at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387) at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301) at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308) at hadoop1.WordCount.main(WordCount.java:53)
When I was running the wordcount instance that comes with the Hadoop cluster, the error message was that the input path did not exist. I searched the Internet for a long time and did not solve it. Finally, I found that the log.1 I created was created locally and was not uploaded. To the hdfs cluster, so an error will be reported when running, the solution is: execute the command:
[root@master ~]# hadoop fs -put log.1/ # (upload the log.1 file to the / directory)
After the operation, you can run the command again:
[root@master ~]# hadoop jar /export/servers/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /1.log /result
The execution results are as follows:
File System Counters FILE: Number of bytes read=312 FILE: Number of bytes written=237571 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=300 HDFS: Number of bytes written=206 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=7544 Total time spent by all reduces in occupied slots (ms)=5156 Total time spent by all map tasks (ms)=7544 Total time spent by all reduce tasks (ms)=5156 Total vcore-milliseconds taken by all map tasks=7544 Total vcore-milliseconds taken by all reduce tasks=5156 Total megabyte-milliseconds taken by all map tasks=7725056 Total megabyte-milliseconds taken by all reduce tasks=5279744 Map-Reduce Framework Map input records=1 Map output records=35 Map output bytes=342 Map output materialized bytes=312 Input split bytes=97 Combine input records=35 Combine output records=25 Reduce input groups=25 Reduce shuffle bytes=312 Reduce input records=25 Reduce output records=25 Spilled Records=50 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=230 CPU time spent (ms)=2110 Physical memory (bytes) snapshot=306843648 Virtual memory (bytes) snapshot=4163534848 Total committed heap usage (bytes)=142278656 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=203 File Output Format Counters Bytes Written=206
Run Successfully!