Problem Description:
Container killed by the ApplicationMaster.
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
21/10/10 08:51:52 INFO mapreduce.Job: map 100% reduce 0%
21/10/10 08:51:53 INFO mapreduce.Job: Job job_1633826412371_0001 failed with state FAILED due to: Task failed task_1633826412371_0001_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0
21/10/10 08:51:54 INFO mapreduce.Job: Counters: 9
Job Counters
Failed map tasks=4
Launched map tasks=4
Other local map tasks=3
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=52317
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=52317
Total vcore-milliseconds taken by all map tasks=52317
Total megabyte-milliseconds taken by all map tasks=53572608
21/10/10 08:51:54 WARN mapreduce.Counters: Group FileSystemCounters is deprecated. Use org.apache.hadoop.mapreduce.FileSystemCounter instead
21/10/10 08:51:54 INFO mapreduce.ExportJobBase: Transferred 0 bytes in 110.2385 seconds (0 bytes/sec)
21/10/10 08:51:54 WARN mapreduce.Counters: Group org.apache.hadoop.mapred.Task$Counter is deprecated. Use org.apache.hadoop.mapreduce.TaskCounter instead
21/10/10 08:51:54 INFO mapreduce.ExportJobBase: Exported 0 records.
21/10/10 08:51:54 ERROR tool.ExportTool: Error during export: Export job failed!
Solution:
① First, check whether the table structure in hive is consistent with MySQL. (desc table name)
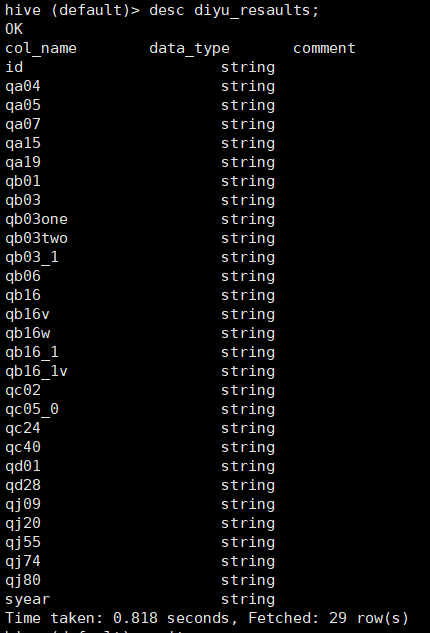
If the table structure is consistent, it may be caused by inconsistent character sets of MySQL tables
② Sqoop import data to MySQL database command:
bin/sqoop export \ > --connect “jdbc:mysql://master:3306/mysql?useUnicode=true&characterEncoding=utf-8” \ > --username root \ > --password 000000 \ > --table QX_diyu_results \ > --num-mappers 1 \ > --export-dir /user/hive/warehouse/diyu_resaults \ > --input-fields-terminated-by ","
It can be seen from the command that the code I use is utf8, so the character set of the MySQL table should be modified to utf8
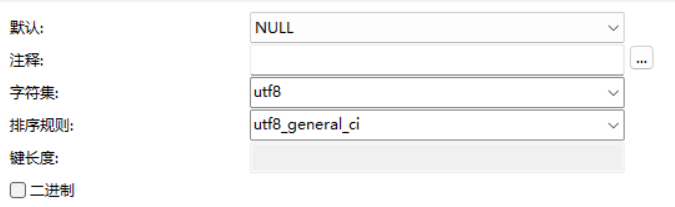
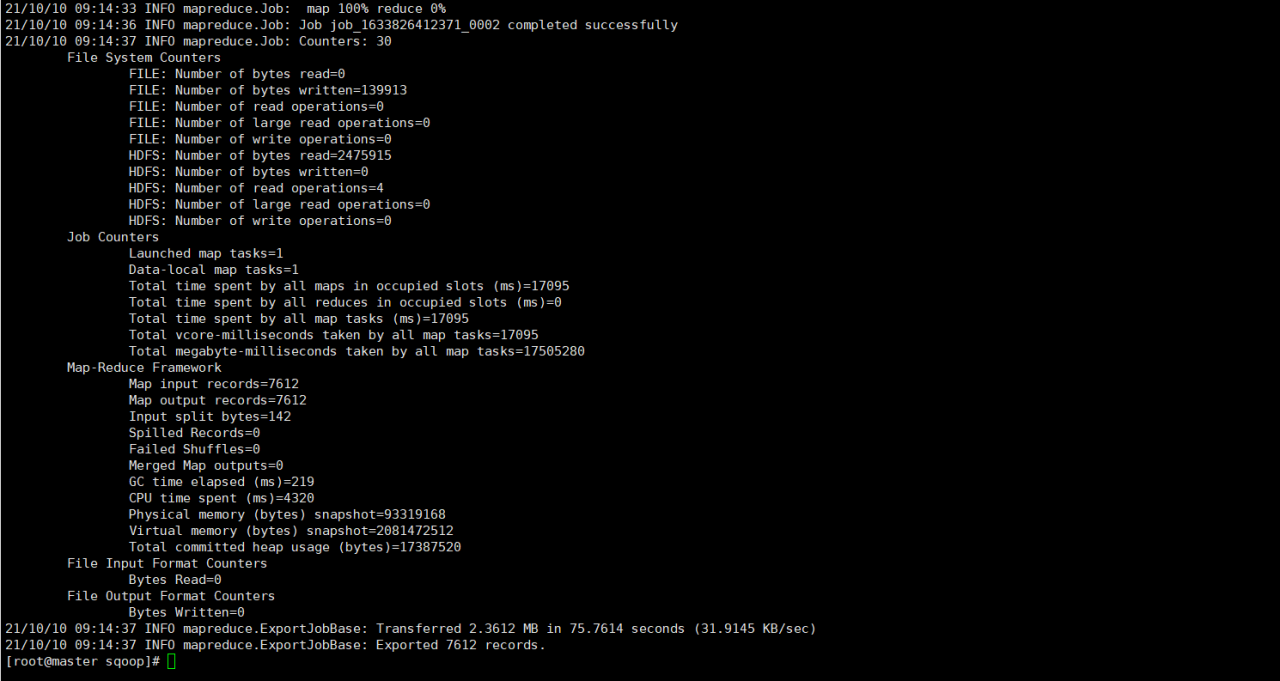
After the modification, run the command again. The following results show that the data import is successful:
Similar Posts:
- [Solved] wordcount Error: org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist:
- [Solved] Error message when Hadoop runs Mr program
- [Solved] Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses
- [Solved] Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses
- The key technologies in hadoop-3.0.0 configuration yarn.nodemanager.aux -Services item
- Tuning and setting of memory and CPU on yarn cluster
- [Solved] Hadoop Error: Input path does not exist: hdfs://Master:9000/user/hadoop/input
- [Solved] Tez Compression codec com.hadoop.compression.lzo.LzoCodec not found.
- Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
- Mapreduce:Split metadata size exceeded 10000000