PHP FPM and nginx are started normally, and page 502 is solved
Background: for the newly installed system, after manually installing PHP, nginx and PHP FPM modules, deploy a PHP project locally. When running, it is found that only nginx version page displays 502
The troubleshooting process is as follows, which is briefly recorded:
Check the startup of PHP FPM and nginx:
# Check if php-fpm and nginx are up
ps -ef|grep php-fpm
ps -ef|grep nginx
The result is: both are up and running
View the nginx log information at the time of the request:
# First, we looked at the location of the nginx runtime logs.
find/-name nginx.conf # Find the nginx configuration file and see where the error.log is stored
# View the error.log information as follows.
*58 connect() failed (111: Connection refused) while connecting to upstream
Troubleshooting results:
PHP FPM and nginx are all started normally, so it is not the reason why PHP FPM is not started. Continue to check and find that:
There are two ways to link nginx and php.
1. fastcgi_pass 127.0.0.1:9000;
2. fastcgi_pass unix:/run/php/php7.0-fpm.sock;
You have to go to the php fpm configuration file to see how this works
/etc/php/7.0/fpm/pool.d/www.conf
If Listen is the port, write 127.0.0.1:9000;
If it's a path, the nginx configuration file should learn the path as well.unix:/run/php/php7.0-fpm.sock;
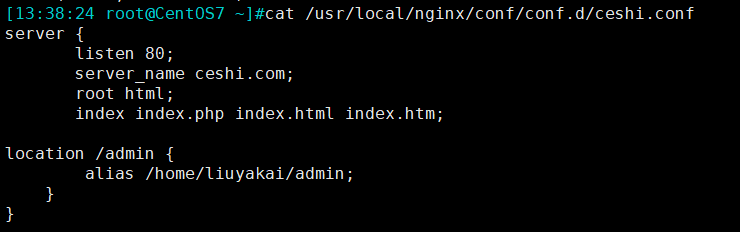
Perfect solution: check the www.conf configuration file, and the path is after listen, so modify the nginx configuration file of the project:
### # fastcgi_pass 127.0.0.1:9000; # Comment out this port and replace it with the following path format
fastcgi_pass unix:/run/php/php7.3-fpm.sock; # fastcgi_pass to the address of phm.sock on the local machine