Explain the function of static keyword and final keyword in Java in detail>>> 
When installing tensorflow, there was an error that DLL file could not be found when using import tensorflow. Referring to many solutions of blogs and stackflow, we found that only the version number did not match, but it did not specify what version was the right one. Therefore, we wrote this pit avoiding guide. Thank you again for your guidance and help
Author’s environment:
Python version 3.6
Tensorflow version 1.14
ImportError: Could not find ‘cudart64_ 100.dll’
Brief answer:
Carefully analyze the types and causes of errors
Find out your tensorflow and CUDA version
Using the corresponding version to solve the problem, complete the adaptation of CUDA and TF, cudnn and CUDA, protobuf and TF
I. causes of error types
The problem is that we can’t find the module of CUDA system DLL file, so we need to download cuda10.0. First, check whether the file exists in CUDA’s path
Access CUDA through the path of C:// program files/NVIDIA GPU computing toolkit/CUDA, and find out whether cudart64 exists in its bin directory_ 100.dll module
If yes, check whether the environment variable is added; If not, it may be the matching problem between CUDA version and tensorflow version
2. Find out your tensorflow and CUDA version
Enter the command line environment, first through Python — version to determine their own Python version is 3.6
Then check the installed tensorflow version through PIP list. The version of the author is 1.14
Check CUDA version through nvcc — version. The previous CUDA version is v9.0.176
Find the corresponding version information through the official website of tesnsorflow
You can see that when tensorflow’s version & gt= 1.13, CUDA version needs to be 10.0, and cudnn version number needs to be greater than 7.4.1
Here I choose to unload CUDA version to apply tensorflow version
Directly enter the path of C:// program files/NVIDIA GPU computing toolkit/CUDA to delete the folder and environment variables
Found a high school students to build the server download link, here the download speed will be faster:
How much is circumcision in Wuxi http://www.bhnkyixue.com/
The corresponding cudnn corresponds to CUDA version
After installing CUDA version, open jupyter again and run import tensorflow. It is found that it is not successful, and the ‘cudnn64’ is not found_ Error in 7. DLL ‘:
ImportError: Could not find ‘cudnn64_ 7.dll’
This prompt indicates that the DLL file of cudnn module is missing. According to the tensorflow document, cudnn should be > 7.4.1. Download cudnn. The directory structure of cudnn is as follows:
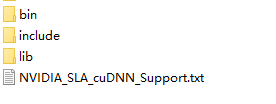
Put the files in cudnn directory in CUDA directory
4. Match the corresponding protobuf to the corresponding TF version
At this time, there should be no problem. The author continued to run import tensorflow, MMP, but it did not run smoothly. There was a “descriptor” error
ImportError: cannot import name ‘descriptor’
Summary of TF installation problems on stackflow
Through searching on stackflow, it is found that the reason for this error is that the versions of protobuf and TF do not correspond, because there is a dependency relationship between TF and pro. Therefore, the author will first install pro, then install TF, and finally re install TF. TF will automatically install the dependency pro
There was a little episode in the middle. The author used virtualenv’s py virtual environment, so after installing the version, the error of ‘descriptor’ still appeared, so I tested it in the native py environment and found that TF can be imported. The reason is that the system can’t find the sitepackage in the PY virtual environment. If the directory in py bin of the virtual environment is set as the environment variable, it can be called normally
The final result is imported successfully
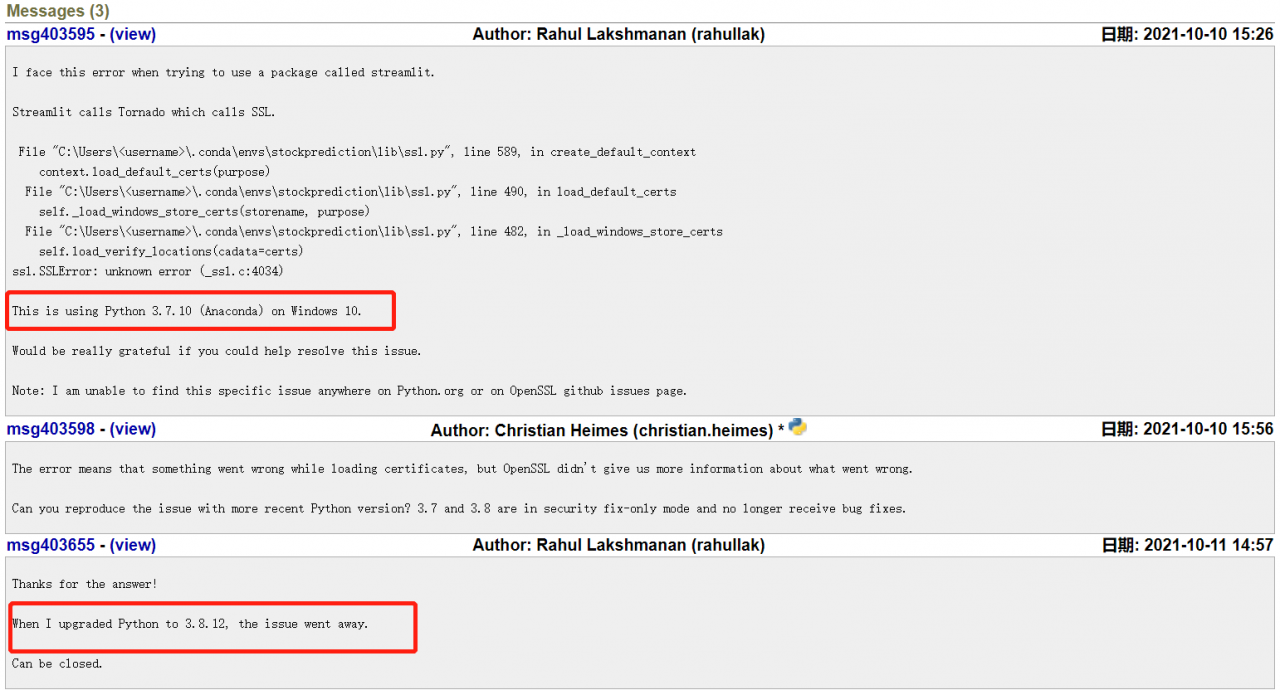 explanation on the Internet. I think it should be the python version, so I upgraded the python version in Anaconda navigator. Then enter
explanation on the Internet. I think it should be the python version, so I upgraded the python version in Anaconda navigator. Then enter 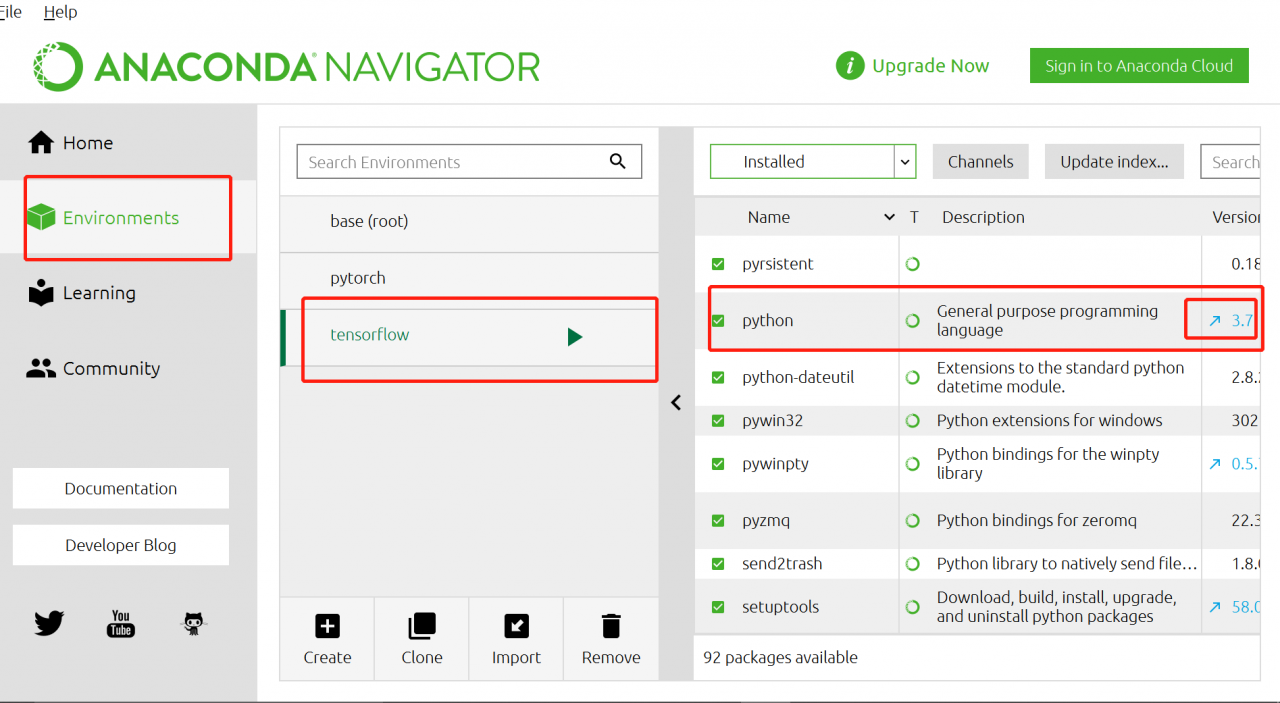
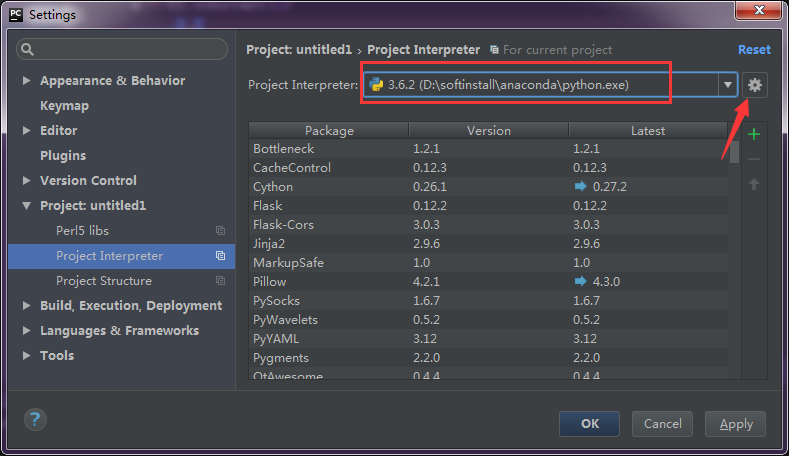
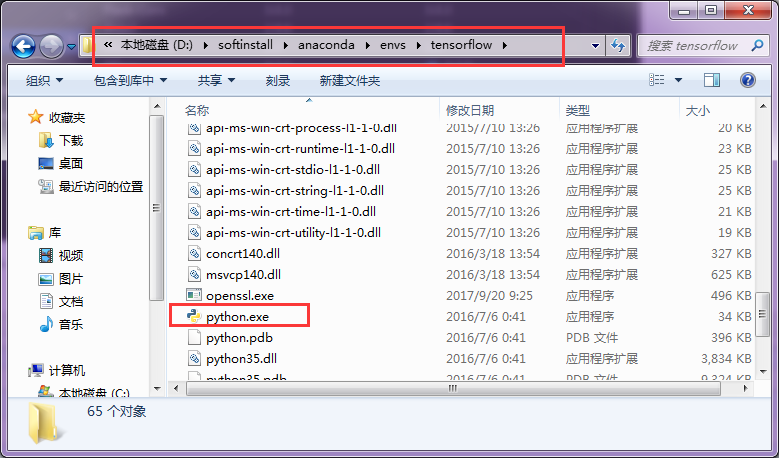
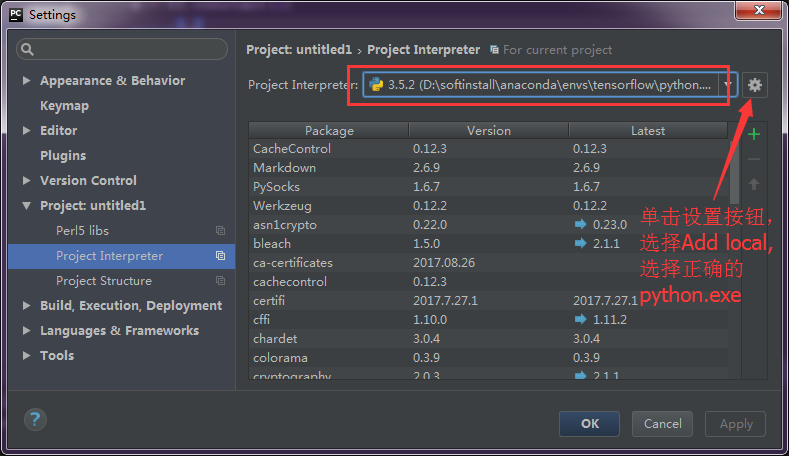


 .
.