Error Messages:
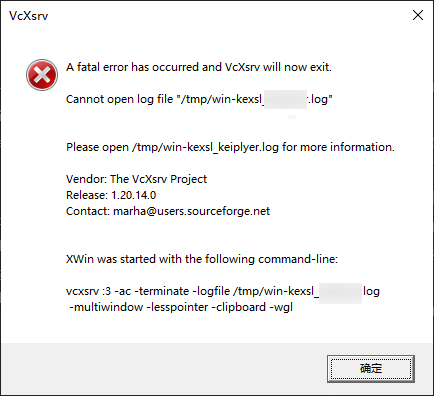
2022-11-09 11:26:21.693 ERROR 18228 --- [ restartedMain] o.s.b.d.LoggingFailureAnalysisReporter : *************************** APPLICATION FAILED TO START *************************** Description: The bean 'sysDictService' could not be injected because it is a JDK dynamic proxy The bean is of type 'com.sun.proxy.$Proxy134' and implements: org.springframework.aop.SpringProxy org.springframework.aop.framework.Advised org.springframework.cglib.proxy.Factory com.baomidou.mybatisplus.extension.service.IService org.springframework.core.DecoratingProxy Expected a bean of type 'com.sozone.basis.dict.service.SysDictService' which implements: Action: Consider injecting the bean as one of its interfaces or forcing the use of CGLib-based proxies by setting proxyTargetClass=true on @EnableAsync and/or @EnableCaching.
Solution 1:
// StartApplication.java Add this method to the project startup class
@Bean
@ConditionalOnMissingBean
public DefaultAdvisorAutoProxyCreator defaultAdvisorAutoProxyCreator() {
DefaultAdvisorAutoProxyCreator daap = new DefaultAdvisorAutoProxyCreator();
daap.setProxyTargetClass(true);
return daap;
}
Solution 2:
// application.yml
spring:
aop:
proxy-target-class: true
Problem Description:
When sorting out the project framework, there was a sudden problem. The original framework did not have this problem. I don’t know if it was caused by a dependency. . .
Finally, use solution one to successfully solve the problem. The second solution could not be solved, and I also recorded it casually, maybe I will encounter it again later.