Abstract
We are using spark in a process: using spark. Sql() function to read data into memory to form dataset [row] (dataframe). Because row is a new spark dataset, automatic coding can not be realized, so we need to encode this dataset in order to use these operators for related operations. How to encode is a problem, Here is a summary of these issues. Error: unable to find encoder for type stored in a dataset. Primitive types (int, string, etc) and product types (case classes) are supported by importing spark.implies_ Support for serializing other types will be added in future releases.
This error is generally reported that when we use the operator, the data type of the return value is often not the automatic encoding part that spark can complete through its own reflection. For example, through the map operator, the return value type of the function of the map operator is map type, so the above problem will appear, because the map set class is not in the basic type and string, Within the scope of case class and tuple, spark can not automatically encode by reflection
The reason for this problem
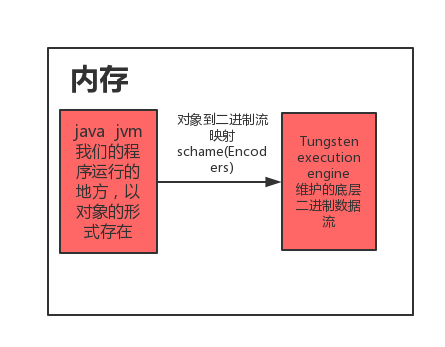
The version after spark 2.0 uses a new distributed dataset, in which dataframe is the alias of dataset [row]. The new dataset uses a lot of optimizations, one of which is to use the computing engine of tungsten execution engine, which uses a lot of optimizations. One of them is to maintain a memory manager, which frees computing from Java JVM and improves memory optimization greatly. At the same time, the new computing engine stores the data in the memory in the form of binary. Most of the calculations are carried out on the binary data stream. There is no need to reverse sequence the binary data stream into Java objects, and then sequence the calculation results into binary data stream, but directly operate on the binary stream, In this case, we need to have a mechanism, that is, the mapping relationship between Java objects and binary data stream. Otherwise, we don’t know how many bytes the binary data stream corresponds to. The process of spark is completed by encoders. Spark itself completes part of the automatic encoding process by reflection: basic types and string, case class and tuple, For other collection types or our custom classes, he can’t complete such coding. We need to define such a code ourselves, that is, let it have a schema
How to solve this problem
Method 1
This is to convert it into RDD and use RDD for operation, but this is not recommended. Compared with RDD, dataset performs a lot of underlying optimization and has very good performance
val orderInfo1 = spark.sql(
"""
|SELECT
|o.id,
|o.user_id
|FROM default.api_order o
|limit 100
""".stripMargin).rdd.map(myfunction)
Method 2
Let it automatically convert dataset [row] to dataset [P], if there are complex types in row
case class Orders(id: String, user_id: String)
object a {
def main(args: Array[String]): Unit ={
import spark.implicits._
val orderInfo1 = spark.sql(
"""
|SELECT
|o.id,
|o.user_id
|FROM default.api_order o
|limit 100
""".stripMargin).as[Orders].map(myfunction)
}
}
Method 3:
Customize a schema, and then encode it with rowencoder. This is just an example. In fact, all types in it can automatically complete the encoding process through spark reflection
import spark.implicits._
val schema = StructType(StructType(Seq(StructField("id",StringType,true),StructField("user_id",StringType,true))))
val encoders = RowEncoder(schema)
val orderInfo1 = spark.sql(
"""
|SELECT
|o.id,
|o.user_id
|FROM default.api_order o
|limit 100
""".stripMargin).map(row => row)(encoders)
Method 4:
It is possible to directly use the strategy of schema matching in Scala, case row, because of the knowledge of schema matching in case row() Scala. In this way, we can know how many basic types there are in the set row, then we can automatically encode the row through Scala, and then we can carry out corresponding processing
import spark.implicits._
val orderInfo1 = spark.sql(
"""
|SELECT
|o.id,
|o.user_id
|FROM default.api_order o
|limit 100
""".stripMargin).map{case Row(id: String, user_id: String) => (id,user_id)}
This gets the schema as
orderInfo1: org.apache.spark.sql.Dataset[(String, String)] = [_1: string, _2: string]
If replaced with this.
val orderInfo1 = spark.sql(
"""
|SELECT
|o.id,
|o.user_id
|FROM default.api_order o
|limit 100
""".stripMargin).map{case Row(id: String, user_id: String) => List(id,user_id)}
The resulting schema is.
orderInfo1: org.apache.spark.sql.Dataset[List[String]] = [value: array<string>]
You can see: spark is to see the meta ancestor as a case class a special form of ownership, schame field name called _1,_2 such special case clase