Error:
TypeError: list indices must be integers or slices, not strerror code block:
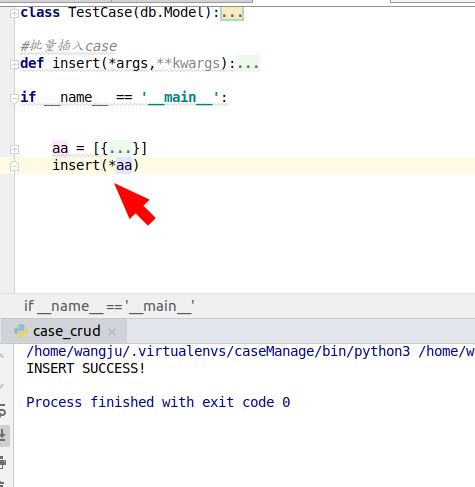
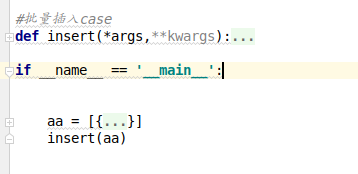
AA is a set of list and dict data
The function insert receives two parameters, * args, * * kwargs
I hope to pass the list AA to * args
But in the execution of the program, a title display error was reported
first of all, the basic concepts of * args and * kwargs:
For * args and * * kwargs, we can call them parameter groups in functions, but they are different
1: * functions of args: – – – receive n position parameters and convert them into tuple form
2: The function of * * kwargs is to receive n keyword parameters and convert them into dict form
3: The location parameter must precede the keyword parameter, that is, (* args, * * kwargs)
problem analysis:
A * sign before the parameter AA indicates that it is an assembled tuple, otherwise Python will think AA is a positional parameter
So the program can run as expected