The code of densenet is as follows:
import tensorflow as tf
import os
import random
import math
import tensorflow.contrib.slim as slim
import time
import logging
import numpy as np
import pickle
from PIL import Image
import tensorflow as tf
#from tflearn.layers.conv import global_avg_pool
from tensorflow.contrib.layers import batch_norm, flatten
from tensorflow.contrib.framework import arg_scope
import numpy as np
# Hyperparameter
growth_k = 12
nb_block = 2 # how many (dense block + Transition Layer) ?
init_learning_rate = 1e-4
epsilon = 1e-8 # AdamOptimizer epsilon
dropout_rate = 0.2
# Momentum Optimizer will use
nesterov_momentum = 0.9
weight_decay = 1e-4
# Label & batch_size
class_num = 3755
batch_size = 128
total_epochs = 50
def conv_layer(input, filter, kernel, stride=1, layer_name="conv"):
with tf.name_scope(layer_name):
network = tf.layers.conv2d(inputs=input, filters=filter, kernel_size=kernel, strides=stride, padding='SAME')
return network
def Global_Average_Pooling(x, stride=1):
#It is global average pooling without tflearn
width = np.shape(x)[1]
height = np.shape(x)[2]
pool_size = [width, height]
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride) # The stride value does not matter
"""
return global_avg_pool(x, name='Global_avg_pooling')
# But maybe you need to install h5py and curses or not
"""
def Batch_Normalization(x, training, scope):
with arg_scope([batch_norm],
scope=scope,
updates_collections=None,
decay=0.9,
center=True,
scale=True,
zero_debias_moving_mean=True) :
return tf.cond(training,
lambda : batch_norm(inputs=x, is_training=training, reuse=None),
lambda : batch_norm(inputs=x, is_training=training, reuse=True))
def Drop_out(x, rate, training) :
return tf.layers.dropout(inputs=x, rate=rate, training=training)
def Relu(x):
return tf.nn.relu(x)
def Average_pooling(x, pool_size=[2,2], stride=2, padding='VALID'):
return tf.layers.average_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding=padding)
def Max_Pooling(x, pool_size=[3,3], stride=2, padding='VALID'):
return tf.layers.max_pooling2d(inputs=x, pool_size=pool_size, strides=stride, padding=padding)
def Concatenation(layers) :
return tf.concat(layers, axis=3)
def Linear(x) :
return tf.layers.dense(inputs=x, units=class_num, name='linear')
class DenseNet():
def __init__(self, x, nb_blocks, filters, training):
self.nb_blocks = nb_blocks
self.filters = filters
self.training = training
self.model = self.Dense_net(x)
def bottleneck_layer(self, x, scope):
# print(x)
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
x = conv_layer(x, filter=4 * self.filters, kernel=[1,1], layer_name=scope+'_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch2')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[3,3], layer_name=scope+'_conv2')
x = Drop_out(x, rate=dropout_rate, training=self.training)
# print(x)
return x
def transition_layer(self, x, scope):
with tf.name_scope(scope):
x = Batch_Normalization(x, training=self.training, scope=scope+'_batch1')
x = Relu(x)
x = conv_layer(x, filter=self.filters, kernel=[1,1], layer_name=scope+'_conv1')
x = Drop_out(x, rate=dropout_rate, training=self.training)
x = Average_pooling(x, pool_size=[2,2], stride=2)
return x
def dense_block(self, input_x, nb_layers, layer_name):
with tf.name_scope(layer_name):
layers_concat = list()
layers_concat.append(input_x)
x = self.bottleneck_layer(input_x, scope=layer_name + '_bottleN_' + str(0))
layers_concat.append(x)
for i in range(nb_layers - 1):
x = Concatenation(layers_concat)
x = self.bottleneck_layer(x, scope=layer_name + '_bottleN_' + str(i + 1))
layers_concat.append(x)
x = Concatenation(layers_concat)
return x
def Dense_net(self, input_x):
x = conv_layer(input_x, filter=2 * self.filters, kernel=[7,7], stride=2, layer_name='conv0')
x = Max_Pooling(x, pool_size=[3,3], stride=2)
for i in range(self.nb_blocks) :
# 6 -> 12 -> 48
x = self.dense_block(input_x=x, nb_layers=4, layer_name='dense_'+str(i))
x = self.transition_layer(x, scope='trans_'+str(i))
"""
x = self.dense_block(input_x=x, nb_layers=6, layer_name='dense_1')
x = self.transition_layer(x, scope='trans_1')
x = self.dense_block(input_x=x, nb_layers=12, layer_name='dense_2')
x = self.transition_layer(x, scope='trans_2')
x = self.dense_block(input_x=x, nb_layers=48, layer_name='dense_3')
x = self.transition_layer(x, scope='trans_3')
"""
x = self.dense_block(input_x=x, nb_layers=32, layer_name='dense_final')
# 100 Layer
x = Batch_Normalization(x, training=self.training, scope='linear_batch')
x = Relu(x)
x = Global_Average_Pooling(x)
x = flatten(x)
x = Linear(x)
# x = tf.reshape(x, [-1, 10])
return x
def build_graph(top_k):
# with tf.device('/cpu:0'):
# keep_prob = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob')
images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1], name='image_batch')
# label = tf.placeholder(tf.float32, shape=[None, 10])
labels = tf.placeholder(dtype=tf.int64, shape=[None], name='label_batch')
training_flag = tf.placeholder(tf.bool)
logits = DenseNet(x=images, nb_blocks=nb_block, filters=growth_k, training=training_flag).model
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels))
# loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=logits))
"""
l2_loss = tf.add_n([tf.nn.l2_loss(var) for var in tf.trainable_variables()])
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=nesterov_momentum, use_nesterov=True)
train = optimizer.minimize(cost + l2_loss * weight_decay)
In paper, use MomentumOptimizer
init_learning_rate = 0.1
but, I'll use AdamOptimizer
"""
global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)
rate = tf.train.exponential_decay(2e-4, global_step, decay_steps=2000, decay_rate=0.97, staircase=True)
optimizer = tf.train.AdamOptimizer(learning_rate=rate, epsilon=epsilon)
train_op = optimizer.minimize(loss, global_step=global_step)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), labels), tf.float32))
probabilities = logits
tf.summary.scalar('loss', loss)
tf.summary.scalar('accuracy', accuracy)
merged_summary_op = tf.summary.merge_all()
predicted_val_top_k, predicted_index_top_k = tf.nn.top_k(probabilities, k=top_k)
accuracy_in_top_k = tf.reduce_mean(tf.cast(tf.nn.in_top_k(probabilities, labels, top_k), tf.float32))
return {'images': images,
'labels': labels,
'training_flag': training_flag,
'top_k': top_k,
'global_step': global_step,
'train_op': train_op,
'loss': loss,
'accuracy': accuracy,
'accuracy_top_k': accuracy_in_top_k,
'merged_summary_op': merged_summary_op,
'predicted_distribution': probabilities,
'predicted_index_top_k': predicted_index_top_k,
'predicted_val_top_k': predicted_val_top_k}
logger = logging.getLogger('Training a chinese write char recognition')
logger.setLevel(logging.INFO)
# formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
logger.addHandler(ch)
run_mode = "train"
charset_size = class_num
max_steps = 122002
save_steps = 1000
cur_test_acc = 0
"""
# for online 3755 words training
checkpoint_dir = '/aiml/dfs/checkpoint_888/'
train_data_dir = '/aiml/data/train/'
test_data_dir = '/aiml/data/test/'
log_dir = '/aiml/dfs/'
"""
checkpoint_dir = './checkpoint_densenet/'
train_data_dir = './data/train/'
test_data_dir = './data/test/'
log_dir = './'
tf.app.flags.DEFINE_string('mode', run_mode, 'Running mode. One of {"train", "valid", "test"}')
tf.app.flags.DEFINE_boolean('random_flip_up_down', True, "Whether to random flip up down")
tf.app.flags.DEFINE_boolean('random_brightness', True, "whether to adjust brightness")
tf.app.flags.DEFINE_boolean('random_contrast', True, "whether to random constrast")
tf.app.flags.DEFINE_integer('charset_size', charset_size, "Choose the first `charset_size` character to conduct our experiment.")
tf.app.flags.DEFINE_integer('image_size', 64, "Needs to provide same value as in training.")
tf.app.flags.DEFINE_boolean('gray', True, "whether to change the rbg to gray")
tf.app.flags.DEFINE_integer('max_steps', max_steps, 'the max training steps ')
tf.app.flags.DEFINE_integer('eval_steps', 50, "the step num to eval")
tf.app.flags.DEFINE_integer('save_steps', save_steps, "the steps to save")
tf.app.flags.DEFINE_string('checkpoint_dir', checkpoint_dir, 'the checkpoint dir')
tf.app.flags.DEFINE_string('train_data_dir', train_data_dir, 'the train dataset dir')
tf.app.flags.DEFINE_string('test_data_dir', test_data_dir, 'the test dataset dir')
tf.app.flags.DEFINE_string('log_dir', log_dir, 'the logging dir')
##############################
# resume training
tf.app.flags.DEFINE_boolean('restore', True, 'whether to restore from checkpoint')
##############################
tf.app.flags.DEFINE_boolean('epoch', 10, 'Number of epoches')
tf.app.flags.DEFINE_boolean('batch_size', 128, 'Validation batch size')
FLAGS = tf.app.flags.FLAGS
class DataIterator:
def __init__(self, data_dir):
# Set FLAGS.charset_size to a small value if available computation power is limited.
truncate_path = data_dir + ('%05d' % FLAGS.charset_size)
print(truncate_path)
self.image_names = []
for root, sub_folder, file_list in os.walk(data_dir):
if root < truncate_path:
self.image_names += [os.path.join(root, file_path) for file_path in file_list]
random.shuffle(self.image_names)
self.labels = [int(file_name[len(data_dir):].split(os.sep)[0]) for file_name in self.image_names]
@property
def size(self):
return len(self.labels)
@staticmethod
def data_augmentation(images):
if FLAGS.random_flip_up_down:
# images = tf.image.random_flip_up_down(images)
images = tf.contrib.image.rotate(images, random.randint(0, 15) * math.pi/180, interpolation='BILINEAR')
if FLAGS.random_brightness:
images = tf.image.random_brightness(images, max_delta=0.3)
if FLAGS.random_contrast:
images = tf.image.random_contrast(images, 0.8, 1.2)
return images
def input_pipeline(self, batch_size, num_epochs=None, aug=False):
images_tensor = tf.convert_to_tensor(self.image_names, dtype=tf.string)
labels_tensor = tf.convert_to_tensor(self.labels, dtype=tf.int64)
input_queue = tf.train.slice_input_producer([images_tensor, labels_tensor], num_epochs=num_epochs)
labels = input_queue[1]
images_content = tf.read_file(input_queue[0])
images = tf.image.convert_image_dtype(tf.image.decode_png(images_content, channels=1), tf.float32)
if aug:
images = self.data_augmentation(images)
new_size = tf.constant([FLAGS.image_size, FLAGS.image_size], dtype=tf.int32)
images = tf.image.resize_images(images, new_size)
image_batch, label_batch = tf.train.shuffle_batch([images, labels], batch_size=batch_size, capacity=50000,
min_after_dequeue=10000)
return image_batch, label_batch
def train():
print('Begin training')
train_feeder = DataIterator(FLAGS.train_data_dir)
test_feeder = DataIterator(FLAGS.test_data_dir)
with tf.Session() as sess:
train_images, train_labels = train_feeder.input_pipeline(batch_size=FLAGS.batch_size, aug=True)
test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size)
graph = build_graph(top_k=1)
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
saver = tf.train.Saver()
train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/val')
start_step = 0
if FLAGS.restore:
ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if ckpt:
saver.restore(sess, ckpt)
print("restore from the checkpoint {0}".format(ckpt))
start_step += int(ckpt.split('-')[-1])
logger.info(':::Training Start:::')
try:
while not coord.should_stop():
start_time = time.time()
train_images_batch, train_labels_batch = sess.run([train_images, train_labels])
feed_dict = {graph['images']: train_images_batch,
graph['labels']: train_labels_batch,
graph['training_flag']: True}
_, loss_val, train_summary, step = sess.run(
[graph['train_op'], graph['loss'], graph['merged_summary_op'], graph['global_step']],
feed_dict=feed_dict)
train_writer.add_summary(train_summary, step)
end_time = time.time()
logger.info("the step {0} takes {1} loss {2}".format(step, end_time - start_time, loss_val))
if step > FLAGS.max_steps:
break
accuracy_test = 0
if step % FLAGS.eval_steps == 1:
test_images_batch, test_labels_batch = sess.run([test_images, test_labels])
feed_dict = {graph['images']: test_images_batch,
graph['labels']: test_labels_batch,
graph['training_flag']: False}
accuracy_test, test_summary = sess.run(
[graph['accuracy'], graph['merged_summary_op']],
feed_dict=feed_dict)
test_writer.add_summary(test_summary, step)
logger.info('===============Eval a batch=======================')
logger.info('the step {0} test accuracy: {1}'
.format(step, accuracy_test))
logger.info('===============Eval a batch=======================')
if step % FLAGS.save_steps == 1:
logger.info('Save the ckpt of {0}'.format(step))
saver.save(sess, os.path.join(FLAGS.checkpoint_dir, 'my-model'),
global_step=graph['global_step'])
global cur_test_acc
cur_test_acc = accuracy_test
except tf.errors.OutOfRangeError:
logger.info('==================Train Finished================')
saver.save(sess, os.path.join(FLAGS.checkpoint_dir, 'my-model'), global_step=graph['global_step'])
finally:
coord.request_stop()
coord.join(threads)
def validation():
print('validation')
test_feeder = DataIterator(FLAGS.test_data_dir)
final_predict_val = []
final_predict_index = []
groundtruth = []
with tf.Session() as sess:
test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size, num_epochs=1)
graph = build_graph(top_k=3)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer()) # initialize test_feeder's inside state
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if ckpt:
saver.restore(sess, ckpt)
print("restore from the checkpoint {0}".format(ckpt))
print(':::Start validation:::')
try:
i = 0
acc_top_1, acc_top_k = 0.0, 0.0
while not coord.should_stop():
i += 1
start_time = time.time()
test_images_batch, test_labels_batch = sess.run([test_images, test_labels])
feed_dict = {graph['images']: test_images_batch,
graph['labels']: test_labels_batch,
graph['training_flag']: False}
batch_labels, probs, indices, acc_1, acc_k = sess.run([graph['labels'],
graph['predicted_val_top_k'],
graph['predicted_index_top_k'],
graph['accuracy'],
graph['accuracy_top_k']], feed_dict=feed_dict)
final_predict_val += probs.tolist()
final_predict_index += indices.tolist()
groundtruth += batch_labels.tolist()
acc_top_1 += acc_1
acc_top_k += acc_k
end_time = time.time()
logger.info("the batch {0} takes {1} seconds, accuracy = {2}(top_1) {3}(top_k)"
.format(i, end_time - start_time, acc_1, acc_k))
except tf.errors.OutOfRangeError:
logger.info('==================Validation Finished================')
acc_top_1 = acc_top_1 * FLAGS.batch_size/test_feeder.size
acc_top_k = acc_top_k * FLAGS.batch_size/test_feeder.size
logger.info('top 1 accuracy {0} top k accuracy {1}'.format(acc_top_1, acc_top_k))
finally:
coord.request_stop()
coord.join(threads)
return {'prob': final_predict_val, 'indices': final_predict_index, 'groundtruth': groundtruth}
def inference(image):
print('inference')
temp_image = Image.open(image).convert('L')
temp_image = temp_image.resize((FLAGS.image_size, FLAGS.image_size), Image.ANTIALIAS)
temp_image = np.asarray(temp_image)/255.0
temp_image = temp_image.reshape([-1, 64, 64, 1])
with tf.Session() as sess:
logger.info('========start inference============')
# images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1])
# Pass a shadow label 0. This label will not affect the computation graph.
graph = build_graph(top_k=3)
saver = tf.train.Saver()
ckpt = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)
if ckpt:
saver.restore(sess, ckpt)
predict_val, predict_index = sess.run([graph['predicted_val_top_k'], graph['predicted_index_top_k']],
feed_dict={graph['images']: temp_image, graph['training_flag']: False})
return predict_val, predict_index
def main(_):
print(FLAGS.mode)
if FLAGS.mode == "train":
train()
elif FLAGS.mode == 'validation':
dct = validation()
result_file = 'result.dict'
logger.info('Write result into {0}'.format(result_file))
with open(result_file, 'wb') as f:
pickle.dump(dct, f)
logger.info('Write file ends')
elif FLAGS.mode == 'inference':
image_path = './data/00098/102544.png'
final_predict_val, final_predict_index = inference(image_path)
logger.info('the result info label {0} predict index {1} predict_val {2}'.format(190, final_predict_index,
final_predict_val))
if __name__ == "__main__":
tf.app.run()densenet model reference: https://github.com/taki0112/Densenet-Tensorflow
Effects:
==============Eval a batch======================
the step 34001.0 test accuracy: 0.765625
================Eval a batch==============
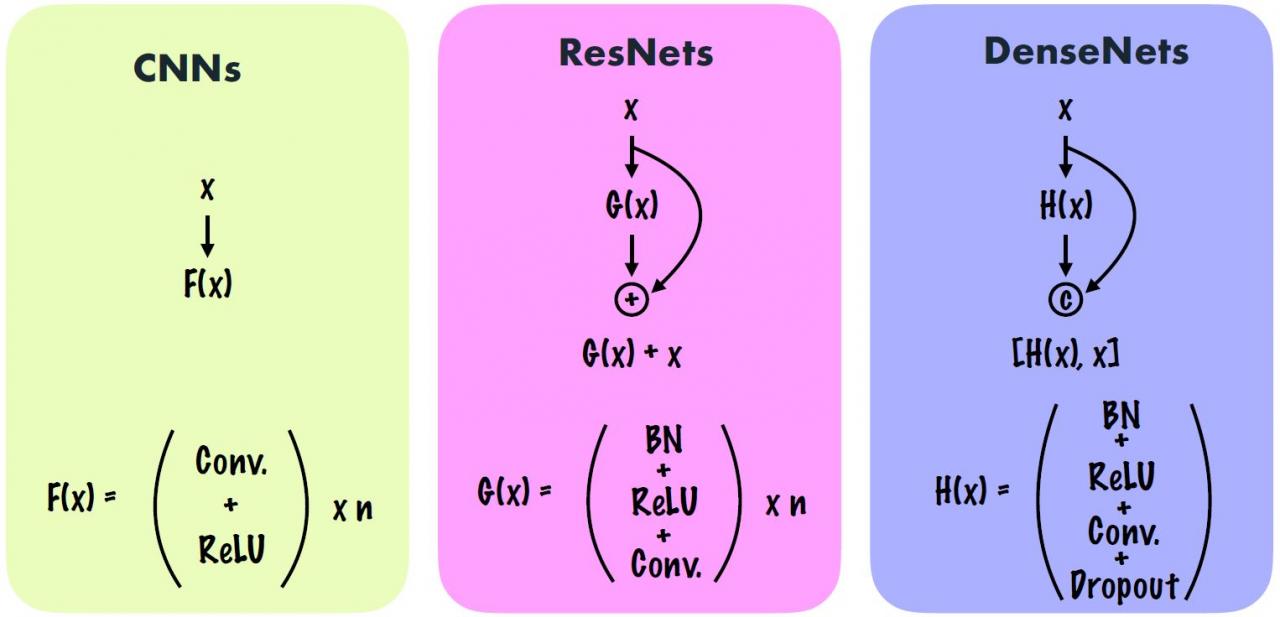
Compare Structure (CNN, ResNet, DenseNet)
Similar Posts:
- Tensorflowcenter {typeerror} non hashable type: “numpy. Ndarray”
- Solution to GPU memory leak problem of tensorflow operation efficiency
- [Solved] TensorFlow Error: InternalError: Failed copying input tensor
- Name Error: name ‘yolo_head’ is not defined [How to Solve]
- Tensorflow error due to uninitialized variable [How to Fix]
- InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor ‘…
- [How to Solve] invalid argument: Nan in summary histogram for: image_pooling/BatchNorm/moving_variance_1
- How to optimize for inference a simple, saved TensorFlow 1.0.1 graph?
- tf.data.Dataset.from_tensor_slices: How to Use shuffle(), repeat(), batch()
- [Solved] An error occurred when paddlepaddle iterated data: typeerror: ‘function’ object is not iterative