1. In the middle of training or at the beginning of saving CKPT, there will be the following problems
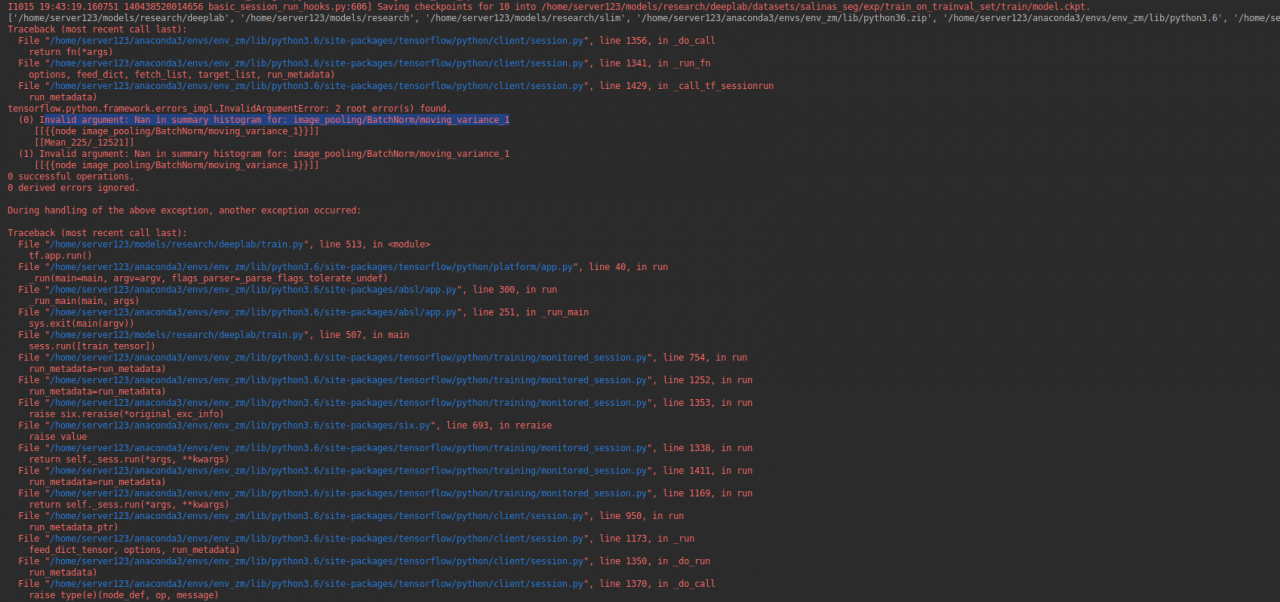
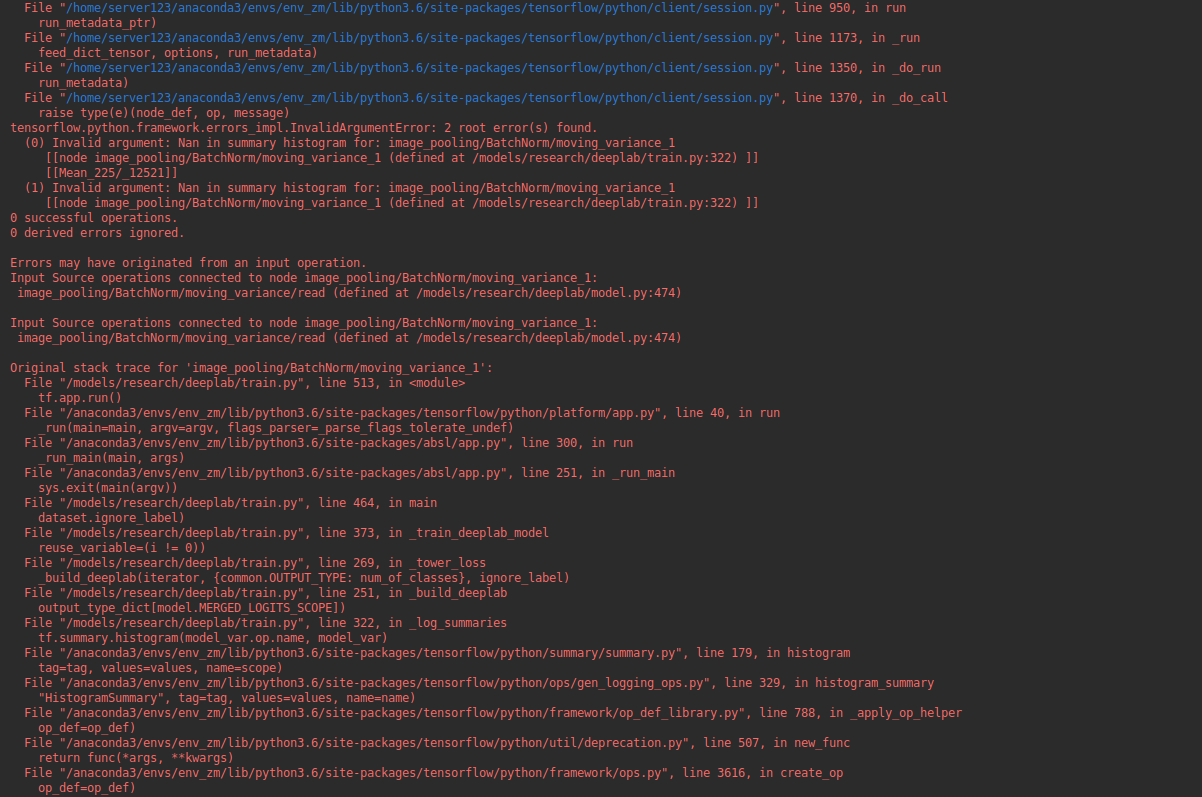
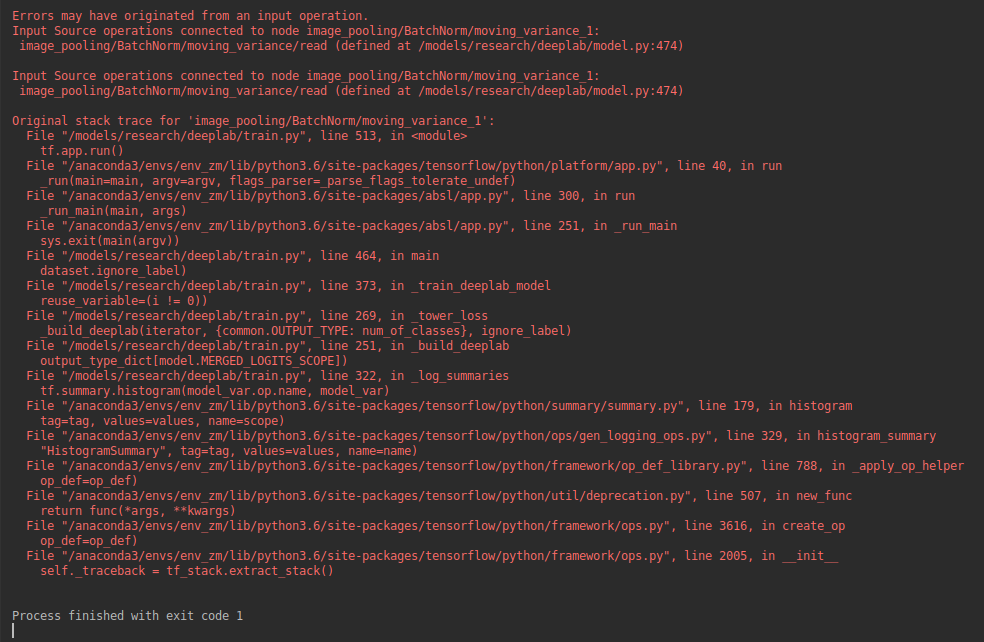
2. According to https://blog.csdn.net/qq_ 41046851/article/details/90552364_ No, it didn’t work
3. According to https://blog.csdn.net/jairana/article/details/83900226#41__ 294fine_ tune_ batch_ Normal = false, no success, learning_ Rate is already 0.0001
4. Exp/train_ on_ trainval_ After all the data in set/train are deleted (that is, the result of the last training is deleted), it runs successfully. Through the above changes, the problem of making mistakes after training for a period of time yesterday is solved. Now the training can run normally even after 1000 iterations
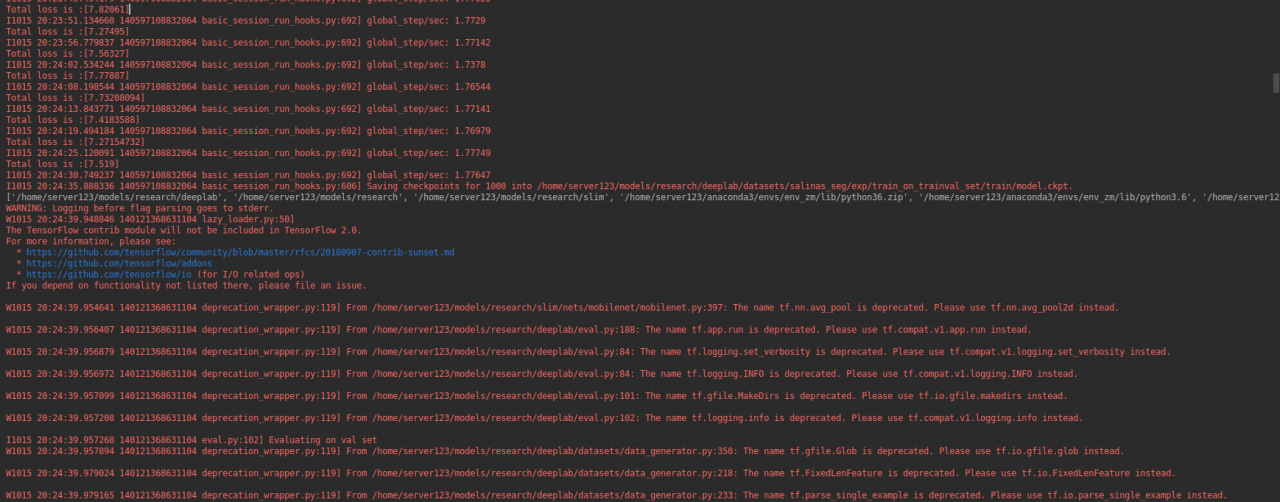
Similar Posts:
- 「ImportError: libcublas.so.10.0: cannot open shared object file: No such file or directory」
- No compatible servers were found when installing MySQL
- ERROR: An error occurred while processing your request. The Development environment shouldn’t be enabled for deployed applications.
- Solution to lifecycle exception with Tomcat error
- tf.data.Dataset.from_tensor_slices: How to Use shuffle(), repeat(), batch()
- Preservation and recovery of TF. Train. Saver () model of tensorflow
- Idea uses git’s pull command to report error 1
- docker: Error response from daemon: Conflict. The container name “/xx” is already in use
- [Solved] An error occurred when paddlepaddle iterated data: typeerror: ‘function’ object is not iterative
- Missing libiconv-2.dll solution and unable to locate input point libiconv-2.dll to DLL