reason:
There is a problem with the device configuration in config.yml
the default in the original file is: device: 1 # 0: CPU, 1: GPU
the configuration here conflicts with that of the native CUDA. In the CUDA installation directory, C: \ program files \ NVIDIA GPU computing toolkit \ CUDA \ v10.0 \ extras \ demo_ Suite executes the devicequery.exe command to view the ID assigned by CUDA to the GPU.
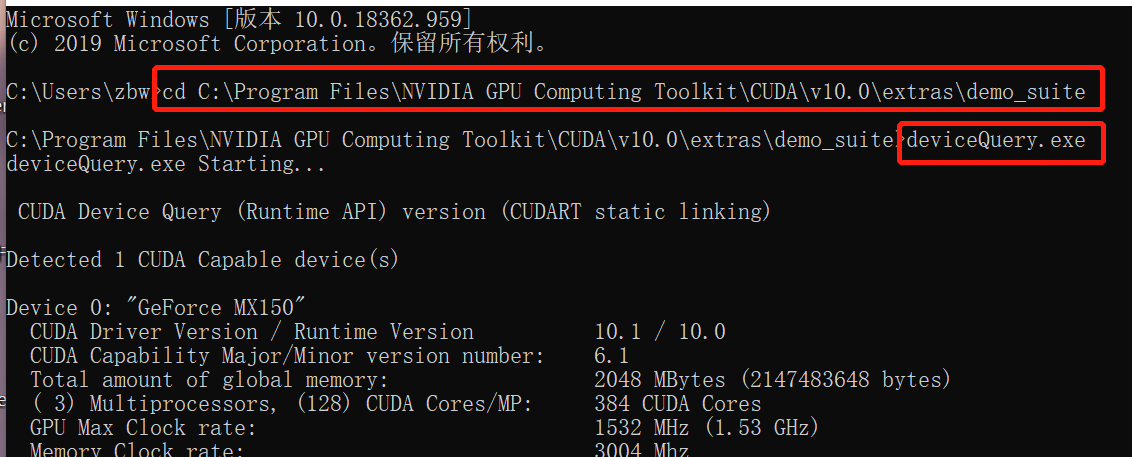
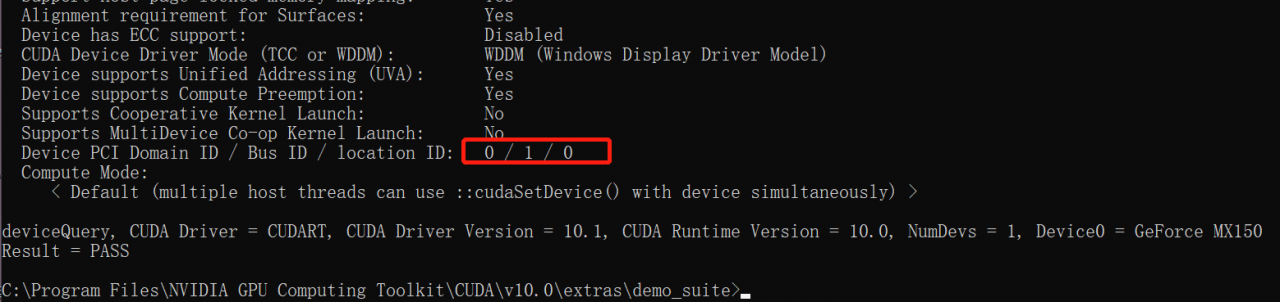
The GPU order here is 0, so there is a conflict in the configuration in config.yml, resulting in that the GPU cannot be used and an error is reported.
terms of settlement:
Rewrite the device setting of config.yml and set it as appropriate according to the resource sequence allocated by CUDA to GPU. CUDA in this machine sets GPU to 0, so device in config.yml is set to:
device: 0 # 0: GPU, 1: CPU

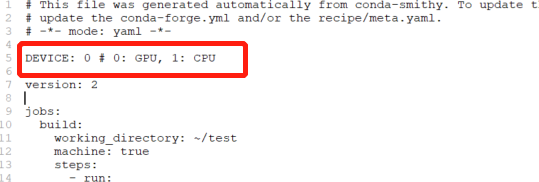
Then you can execute the GPU
Similar Posts:
- [Solved] RuntimeError: Attempting to deserialize object on CUDA device 2 but torch.cuda.device_count() is 1
- InternalError: cudaGetDevice() failed. Status: CUDA driver version is insufficient for CUDA runti…
- Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
- [Solved] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
- Error in loading pre training weight in torch. Load() in pytorch
- The network of vagrant manual – public network
- Qt qt.qpa.xcb: QXcbConnection: XCB error: 8 (BadMatch)…..
- Bringing up interface eth0: Error: No suitable device found: no device found for connection ‘System eth0’. [FAILED]
- Caffe Error-nvcc fatal:Unsupported gpu architecture ‘compute_20’
- [Solved] RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!