The problem of Kryo serialization buffer size causing task failure
Problem report
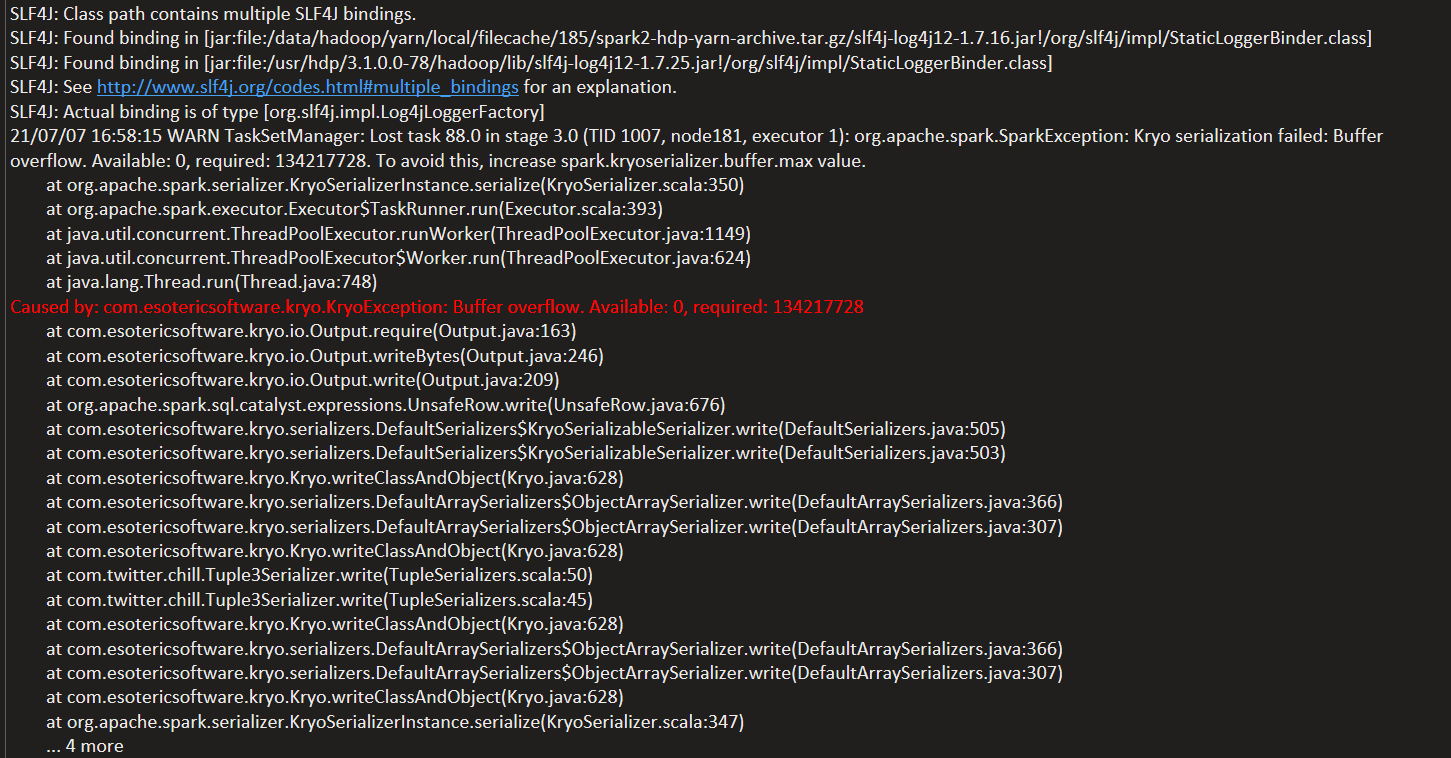
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/data/hadoop/yarn/local/filecache/185/spark2-hdp-yarn-archive.tar.gz/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/3.1.0.0-78/hadoop/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
21/07/07 16:58:15 WARN TaskSetManager: Lost task 88.0 in stage 3.0 (TID 1007, node181, executor 1): org.apache.spark.SparkException: Kryo serialization failed: Buffer overflow. Available: 0, required: 134217728. To avoid this, increase spark.kryoserializer.buffer.max value.
at org.apache.spark.serializer.KryoSerializerInstance.serialize(KryoSerializer.scala:350)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:393)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: com.esotericsoftware.kryo.KryoException: Buffer overflow. Available: 0, required: 134217728
at com.esotericsoftware.kryo.io.Output.require(Output.java:163)
at com.esotericsoftware.kryo.io.Output.writeBytes(Output.java:246)
at com.esotericsoftware.kryo.io.Output.write(Output.java:209)
at org.apache.spark.sql.catalyst.expressions.UnsafeRow.write(UnsafeRow.java:676)
at com.esotericsoftware.kryo.serializers.DefaultSerializers$KryoSerializableSerializer.write(DefaultSerializers.java:505)
at com.esotericsoftware.kryo.serializers.DefaultSerializers$KryoSerializableSerializer.write(DefaultSerializers.java:503)
at com.esotericsoftware.kryo.Kryo.writeClassAndObject(Kryo.java:628)
at com.esotericsoftware.kryo.serializers.DefaultArraySerializers$ObjectArraySerializer.write(DefaultArraySerializers.java:366)
at com.esotericsoftware.kryo.serializers.DefaultArraySerializers$ObjectArraySerializer.write(DefaultArraySerializers.java:307)
at com.esotericsoftware.kryo.Kryo.writeClassAndObject(Kryo.java:628)
at com.twitter.chill.Tuple3Serializer.write(TupleSerializers.scala:50)
at com.twitter.chill.Tuple3Serializer.write(TupleSerializers.scala:45)
at com.esotericsoftware.kryo.Kryo.writeClassAndObject(Kryo.java:628)
at com.esotericsoftware.kryo.serializers.DefaultArraySerializers$ObjectArraySerializer.write(DefaultArraySerializers.java:366)
at com.esotericsoftware.kryo.serializers.DefaultArraySerializers$ObjectArraySerializer.write(DefaultArraySerializers.java:307)
at com.esotericsoftware.kryo.Kryo.writeClassAndObject(Kryo.java:628)
at org.apache.spark.serializer.KryoSerializerInstance.serialize(KryoSerializer.scala:347)
... 4 more
Problem Description
Spark-submit uses kryo serialization parameters when submitting a task. The program reports an error about the size of the serialization buffer during the calculation process. The task submission code:
spark-submit \
--class cn.yd.spark.logAnalyze.LogAnalyze \
--name 'log_analyze' \
--queue offline \
--master yarn \
--deploy-mode cluster \
--conf spark.sql.shuffle.partitions=500 \
--conf spark.default.parallelism=500 \
--conf spark.sql.parquet.compression.codec=snappy \
--conf spark.kryoserializer.buffer.max=128m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.locality.wait.node=6 \
--num-executors 4 \
--executor-cores 1 \
--driver-memory 5g \
--executor-memory 2g \
--conf 'spark.driver.extraJavaOptions= -XX:+UseCodeCacheFlushing -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/log/offline/store_sort_week_driver_error.dump' \
--conf 'spark.executor.extraJavaOptions=-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+ParallelRefProcEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/log/offline/store_sort_week_executor_error.dump' \
/data/xxx.jar
problem causes
This problem is due to the spark.kryoserializer.buffer.max=128mset through the parameter value results in small, since the time required to write data to check on the sequence of parameters, if the maximum value of the data to be written is greater than the set will be thrown
Source :
// Check the constructor method, where the maximum value of the buffer will be set
/** Creates a new Output for writing to a byte array.
* @param bufferSize The initial size of the buffer.
* @param maxBufferSize The buffer is doubled as needed until it exceeds maxBufferSize and an exception is thrown. Can be -1
* for no maximum. */
public Output (int bufferSize, int maxBufferSize) {
if (maxBufferSize < -1) throw new IllegalArgumentException("maxBufferSize cannot be < -1: " + maxBufferSize);
this.capacity = bufferSize;
this.maxCapacity = maxBufferSize == -1 ? Integer.MAX_VALUE : maxBufferSize;
buffer = new byte[bufferSize];
}
// From here it can be seen that the exception is thrown when capacity == maxCapacity
/** @return true if the buffer has been resized. */
protected boolean require (int required) throws KryoException {
if (capacity - position >= required) return false;
if (required > maxCapacity)
throw new KryoException("Buffer overflow. Max capacity: " + maxCapacity + ", required: " + required);
flush();
while (capacity - position < required) {
if (capacity == maxCapacity)
throw new KryoException("Buffer overflow. Available: " + (capacity - position) + ", required: " + required);
// Grow buffer.
if (capacity == 0) capacity = 1;
capacity = Math.min(capacity * 2, maxCapacity);
if (capacity < 0) capacity = maxCapacity;
byte[] newBuffer = new byte[capacity];
System.arraycopy(buffer, 0, newBuffer, 0, position);
buffer = newBuffer;
}
return true;
}
solution
- Adjust the maximum value of sequence serialization parameters, such as 1G
- Serialization method is not applicable, two parameters are removed from the submission script
Similar Posts:
- [Solved] Django REST Framwork Use HyperlinkedModelSerializer Error: `HyperlinkedIdentityField` requires the request in the serializer context
- [Solved] Exception in thread “main” java.lang.NoSuchMethodError: org.apache.hadoop.security.HadoopKerberosName.setRuleMechanism(Ljava/lang/String;)V
- [Solved] idea Remote Submit spark Error: java.io.IOException: Failed to connect to DESKTOP-H
- Only one SparkContext may be running in this JVM
- Idea Run Scala Error: Exception in thread “main” java.lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
- [Solved] java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;) V sets the corresponding Scala version
- [Solved] Kafka 0.8.2.2 Producer:java.net.ConnectException: Connection timed out: no further information
- [Solved] Error: JAVA_HOME is not set and could not be found.
- Spark2.x Error: Queue’s AM resource limit exceeded.
- When debugging stored procedure, ora-20000: oru-10027: buffer overflow is prompted