When starting spark-shell, the following error is reported:
Exception in thread " main " java.lang.NoSuchMethodError: org.apache.hadoop.security.HadoopKerberosName.setRuleMechanism(Ljava/lang/ String;)V
at org.apache.hadoop.security.HadoopKerberosName.setConfiguration(HadoopKerberosName.java: 84 )
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java: 318 )
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java: 303 )
at org.apache.hadoop.security.UserGroupInformation.doSubjectLogin(UserGroupInformation.java: 1827 )
at org.apache.hadoop.security.UserGroupInformation.createLoginUser(UserGroupInformation.java: 709 )
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java: 659 )
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java: 570 )
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$ 1 .apply(Utils.scala: 2422 )
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$ 1 .apply(Utils.scala: 2422 )
at scala.Option.getOrElse(Option.scala: 121 )
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala: 2422 )
at org.apache.spark.SecurityManager. <init>(SecurityManager.scala: 79 )
at org.apache.spark.deploy.SparkSubmit.secMgr$lzycompute$ 1 (SparkSubmit.scala: 348 )
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$secMgr$ 1 (SparkSubmit.scala: 348 )
at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$ 7 .apply(SparkSubmit.scala: 356 )
at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$ 7 .apply(SparkSubmit.scala: 356 )
at scala.Option.map(Option.scala: 146 )
at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala: 355 )
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala: 784 )
at org.apache.spark.deploy.SparkSubmit.doRunMain$ 1 (SparkSubmit.scala: 161 )
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala: 184 )
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala: 86 )
at org.apache.spark.deploy.SparkSubmit$$anon$ 2 .doSubmit(SparkSubmit.scala: 930 )
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala: 939 )
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Solution:
This is due to the wrong configuration that caused the hadoop package to conflict with the spark package.
It turns out that I didn’t know when the configuration in spark-defaults.conf was modified.
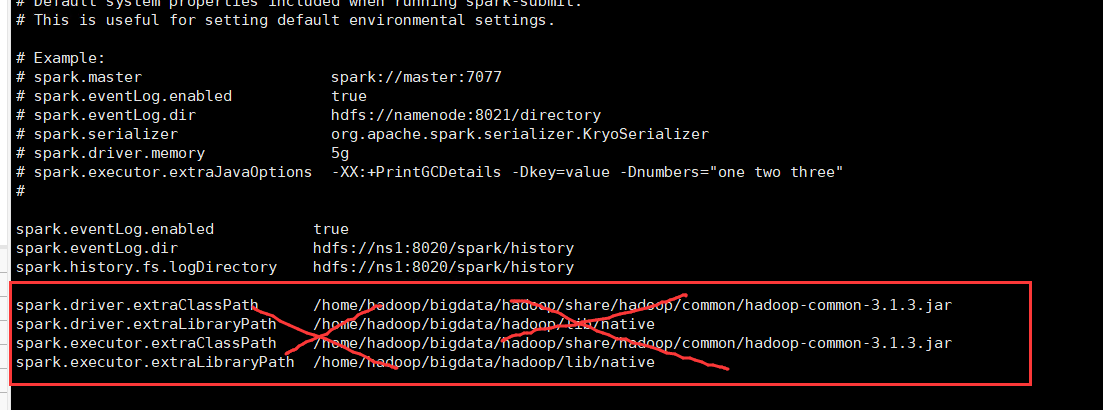
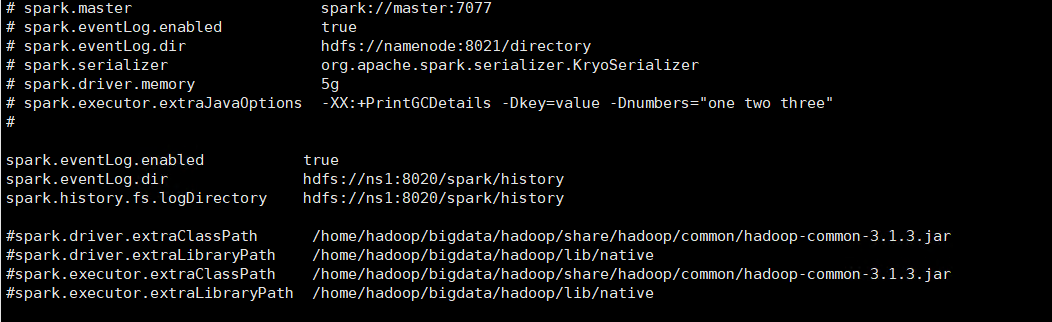
So the solution is very simple, just delete this configuration.
Similar Posts:
- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
- org.apache.spark.SparkException: A master URL must be set in your configuration
- [Solved] ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
- [Solved] idea Remote Submit spark Error: java.io.IOException: Failed to connect to DESKTOP-H
- Only one SparkContext may be running in this JVM
- [Solved] Spark-HBase Error: java.lang.NoClassDefFoundError: org/htrace/Trace
- [Solved] SparkException: Could not find CoarseGrainedScheduler or it has been stopped.
- [Solved] java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;) V sets the corresponding Scala version
- Kafka Error: Caused by: java.lang.OutOfMemoryError: Map failed [How to Solve]
- [Solved] Hadoop Error: Input path does not exist: hdfs://Master:9000/user/hadoop/input