When training maskrcnn, there are some problems
failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detectedAt first, I thought it was because I didn’t install CUDA properly. After checking the installation problem, I found that there was no problem and then restart the computer to run
import tensorflow as tf
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))This is the test code, you can check whether the GPU can run normally
The first time after restarting the computer, the GPU can run normally, indicating that there is no problem with the GPU configuration
However, when the program to call GPU is run again, an error will be reported
failedcalltocuI nit:CUDA_ ERROR_ NO_ DEVICE:noCUDA-capabledeviceisdetected
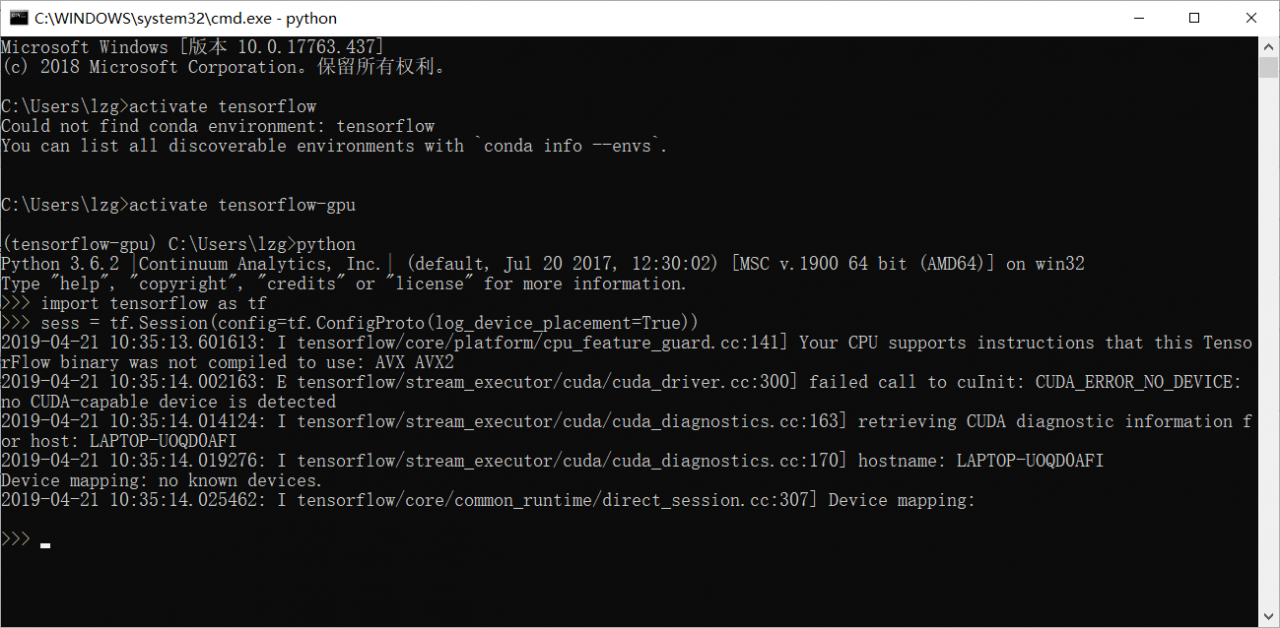
This is a bit strange. At first, I thought that the program was stopped, but the GPU was still occupied. So I checked it with NVIDIA SMI and found an error
UnabletodeterminethedevicehandleforGPU0000:01:00.0:GPUislost.RebootthesystemtorecoverthisGPU
The GPU has been lost… Need to restart… After restart, GPU can be used again, but this problem will appear after using GPU once again
After Google found that it is probably because the video memory occupation is too high, leading to GPU offline, by reducing the batch_ Size may solve the problem. It can be considered to modify some model training parameters from the aspect of reducing the memory occupation in the training process, which needs to be tested
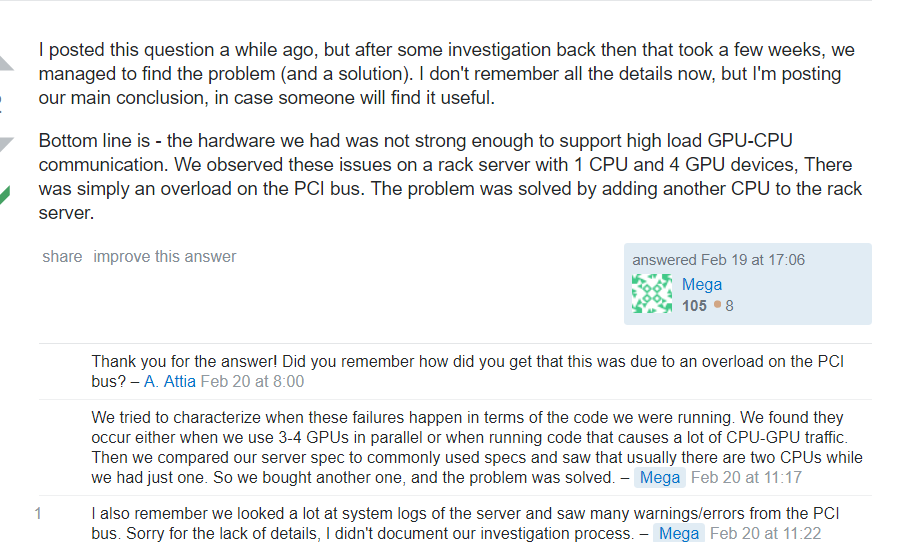
So far, the problem has not been solved, and it will be updated in time after the fundamental solution