Solution: put the file that cannot be found into the root directory of the project
The reason is unclear.
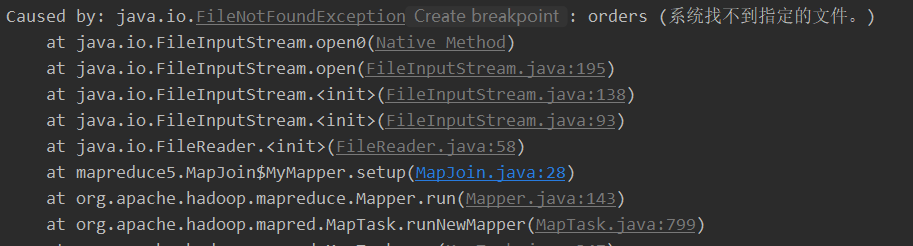
But I found that one record in the log was abnormal, so I thought of putting the file in the root directory
2021-11-18 23:20:36,770 WARN [main] mapred.LocalDistributedCacheManager (LocalDistributedCacheManager.java:symlink(201)) - Failed to create symlink: \tmp\hadoop-wuhao\mapred\local\job_local1290197105_0001_a1814cc0-1378-4a60-bfef-7c0838160efe\orders <- D:\IntelliJ IDEA 2020.3.1\IdeaProjects\MapreduceDemo/orders
Supplement:
In order to support file replication, Hadoop provides a class distributedcache. The methods of using this class are as follows:
(1) The user uses the static method distributedcache. Addcachefile() to specify the file to be copied. Its parameter is the URI of the file (if it is a file on HDFS, it can be as follows: hdfs://namenode:9000/home/XXX/file Where 9000 is the namenode port number configured by yourself. Jobtracker will get the URI list before the job starts and copy the corresponding files to the local disk of each tasktracker.
(2) The user uses the distributedcache. Getlocalcachefiles() method to obtain the file directory, and uses the standard file read-write API to read the corresponding files.
Similar: [MapReduce] reports an error: java.io.filenotfoundexception: \ user \ Mr \ input \ information.txt (the system cannot find the specified path.)_ Riding the snail chase missiles ~-csdn blog