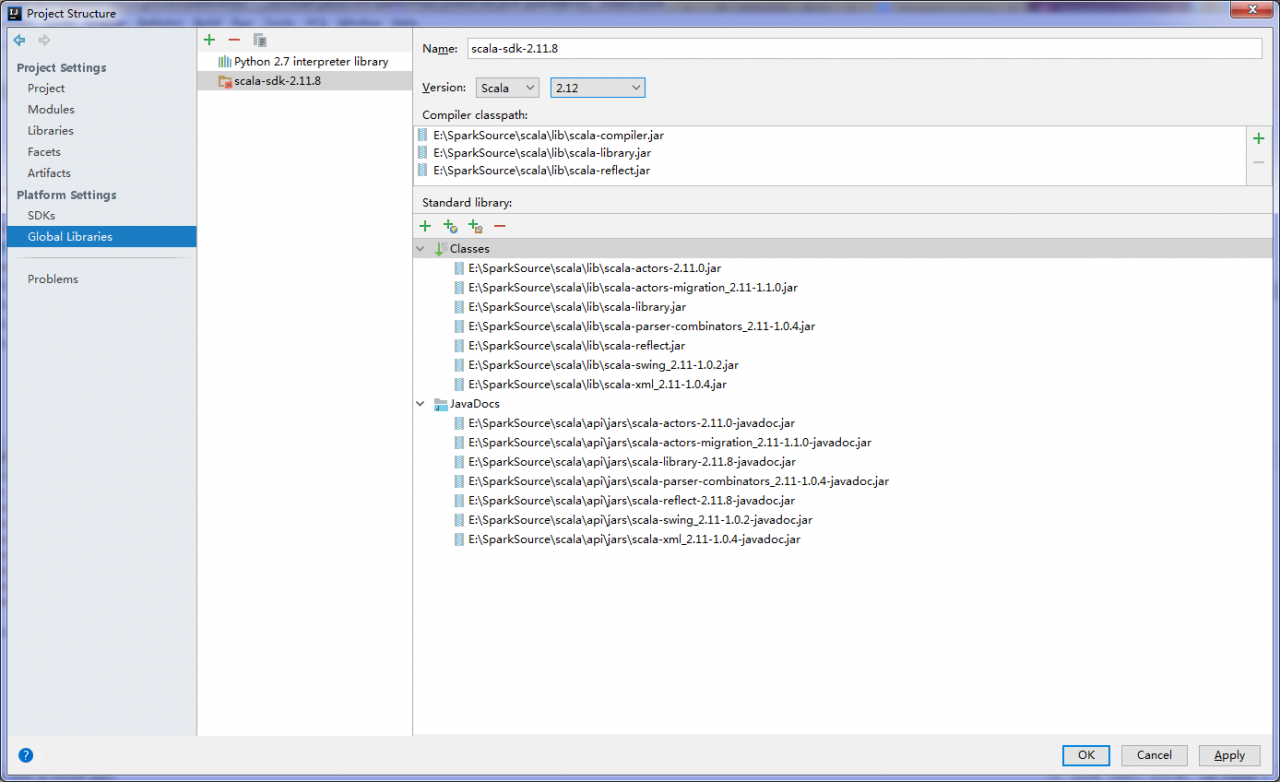
I.Description
Using idea + Scala + spark, the running program code is as follows:
package cn.idcast.hello
import org.apache.spark.rdd.RDD
import org.apache.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* Author itcast
* Desc Demo Spark Starter Case-WordCount
*/
object WordCount_bak {
def main(args: Array[String]): Unit = {
//TODO 1.env/preparesc/SparkContext/SparkContext execution environment
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//TODO 2.source/read data
//RDD:A Resilient Distributed Dataset (RDD): Resilient Distributed Dataset, simply understood as a distributed collection! It is as simple to use as an ordinary collection!
// RDD [is a row of data]
val lines: RDD[String] = sc.textFile("data/input/words.txt")
//TODO 3.transformation/data manipulation/transformation
//cut:RDD[one word]
val words: RDD[String] = lines.flatMap(_.split(" "))
//record as 1:RDD[(word, 1)]
val wordAndOnes: RDD[(String, Int)] = words.map((_,1))
//group aggregation:groupBy + mapValues(_.map(_. _2).reduce(_+_)) ===>group+aggregate inside Spark in one step:reduceByKey
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_+_)
//TODO 4.sink/output
//direct output
result.foreach(println)
//collect as a local collection and then output
println(result.collect().toBuffer)
//output to the specified path (can be a file/folder)
result.repartition(1).saveAsTextFile("data/output/result")
result.repartition(2).saveAsTextFile("data/output/result2")
result.saveAsTextFile("data/output/result3")
// For easy viewing of the Web-UI you can let the program sleep for a while
Thread.sleep(1000 * 60)
//TODO 5. Close the resource
sc.stop()
}
}
(forget the screenshot) an error is reported in the result: exception in thread “main” Java lang.NoSuchMethodError:com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;) V
It is said on the Internet that the jar package conflicts, but it does not solve the problem
II.Solution
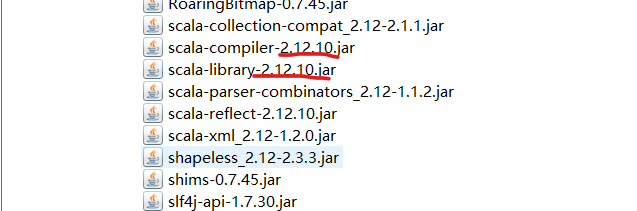
Root cause of the problem: the scala version of windows is inconsistent with the scala version of spark, as shown in the figure:
This is spark’s own version, 2.12.10
I installed 2.12.11 on windows (forgot the screenshot), and later replaced it with 2.12.10 (reinstallation):
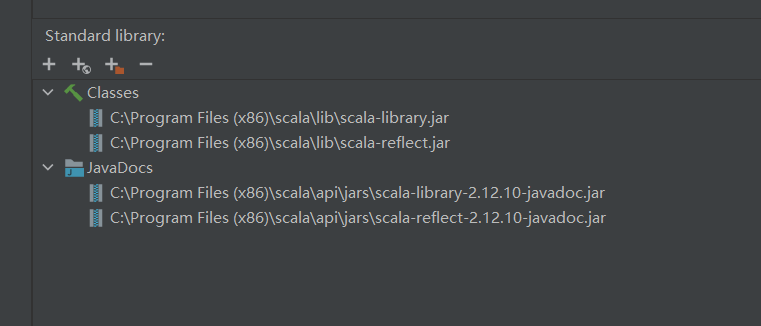
After that, it runs successfully without error