XML reading exception invalid byte 1 of 1-byte UTF-8 sequence
To put it simply, when you parse someone else’s XML format, this error may be that someone else did not save the UTF-8 character encoding format when generating XML
In the Chinese version of window, the default encoding of Java is GBK, that is, although we have identified that we want to save XML in UTF-8 format, in fact, the file is saved in GBK format, so this is why we can use GBK and GB2312 encoding to generate XML files, which can be correctly parsed, while the file generated in UTF-8 format cannot be parsed by XML parser
Encoding exception encountered during XML parsing:
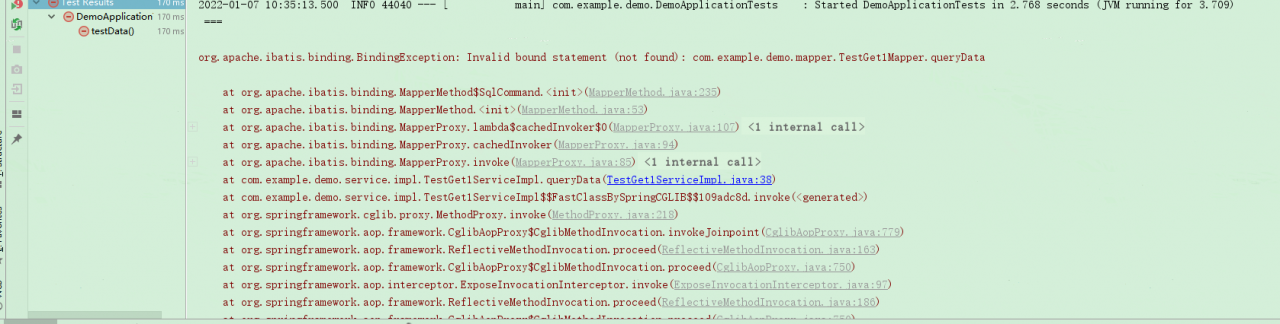
org.dom4j.DocumentException: Invalid byte 1 of 1-byte UTF-8 sequence. Nested exception: Invalid byte 1 of 1-byte UTF-8 sequence.
at org.dom4j.io.SAXReader.read(SAXReader.java:484)
at org.dom4j.io.SAXReader.read(SAXReader.java:321)
at com.dataoperate.PaseXml.pXml(PaseXml.java:28)
at com.dataoperate.JdbcOp.insertDb(JdbcOp.java:30)
at com.dataoperate.JdbcOp.main(JdbcOp.java:89)
Nested exception:
com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: Invalid byte 1 of 1-byte UTF-8 sequence.
at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.invalidByte(UTF8Reader.java:684)
at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.read(UTF8Reader.java:554)
at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.load(XMLEntityScanner.java:1742)
at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.peekChar(XMLEntityScanner.java:487)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2687)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:648)
at com.sun.org.apache.xerces.internal.impl.XMLNSDocumentScannerImpl.next(XMLNSDocumentScannerImpl.java:140)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:511)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:808)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:737)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:119)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1205)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:522)
at org.dom4j.io.SAXReader.read(SAXReader.java:465)
at org.dom4j.io.SAXReader.read(SAXReader.java:321)
at com.dataoperate.PaseXml.pXml(PaseXml.java:28)
at com.dataoperate.JdbcOp.insertDb(JdbcOp.java:30)
at com.dataoperate.JdbcOp.main(JdbcOp.java:89)
Nested exception: com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: Invalid byte 1 of 1-byte UTF-8 sequence.
at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.invalidByte(UTF8Reader.java:684)
at com.sun.org.apache.xerces.internal.impl.io.UTF8Reader.read(UTF8Reader.java:554)
at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.load(XMLEntityScanner.java:1742)
at com.sun.org.apache.xerces.internal.impl.XMLEntityScanner.peekChar(XMLEntityScanner.java:487)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl$FragmentContentDriver.next(XMLDocumentFragmentScannerImpl.java:2687)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentScannerImpl.next(XMLDocumentScannerImpl.java:648)
at com.sun.org.apache.xerces.internal.impl.XMLNSDocumentScannerImpl.next(XMLNSDocumentScannerImpl.java:140)
at com.sun.org.apache.xerces.internal.impl.XMLDocumentFragmentScannerImpl.scanDocument(XMLDocumentFragmentScannerImpl.java:511)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:808)
at com.sun.org.apache.xerces.internal.parsers.XML11Configuration.parse(XML11Configuration.java:737)
at com.sun.org.apache.xerces.internal.parsers.XMLParser.parse(XMLParser.java:119)
at com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser.parse(AbstractSAXParser.java:1205)
at com.sun.org.apache.xerces.internal.jaxp.SAXParserImpl$JAXPSAXParser.parse(SAXParserImpl.java:522)
at org.dom4j.io.SAXReader.read(SAXReader.java:465)
at org.dom4j.io.SAXReader.read(SAXReader.java:321)
at com.dataoperate.PaseXml.pXml(PaseXml.java:28)
at com.dataoperate.JdbcOp.insertDb(JdbcOp.java:30)
at com.dataoperate.JdbcOp.main(JdbcOp.java:89)
solve:
1. The simplest is to <?xml version=”1.0″ encoding=”UTF-8″?> Change to<?xml version=”1.0″ encoding=”gbk”?>
2. Or change the character set of XML to UTF-8 and save it
3. When parsing the code, rewrite the XML first
SAXReader reader = new SAXReader();
org.dom4j.Document document = reader.read("D:\\ha.xml");
OutputFormat of = new OutputFormat();
of.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileWriter "d:\\dom4j.xml"), of);
4. When reading Dom4j directly, use IO to read and modify the character code
FileInputStream in = new FileInputStream(new File(fileName));
Reader read = new InputStreamReader(in,"gbk");
Document document = reader.read(read);