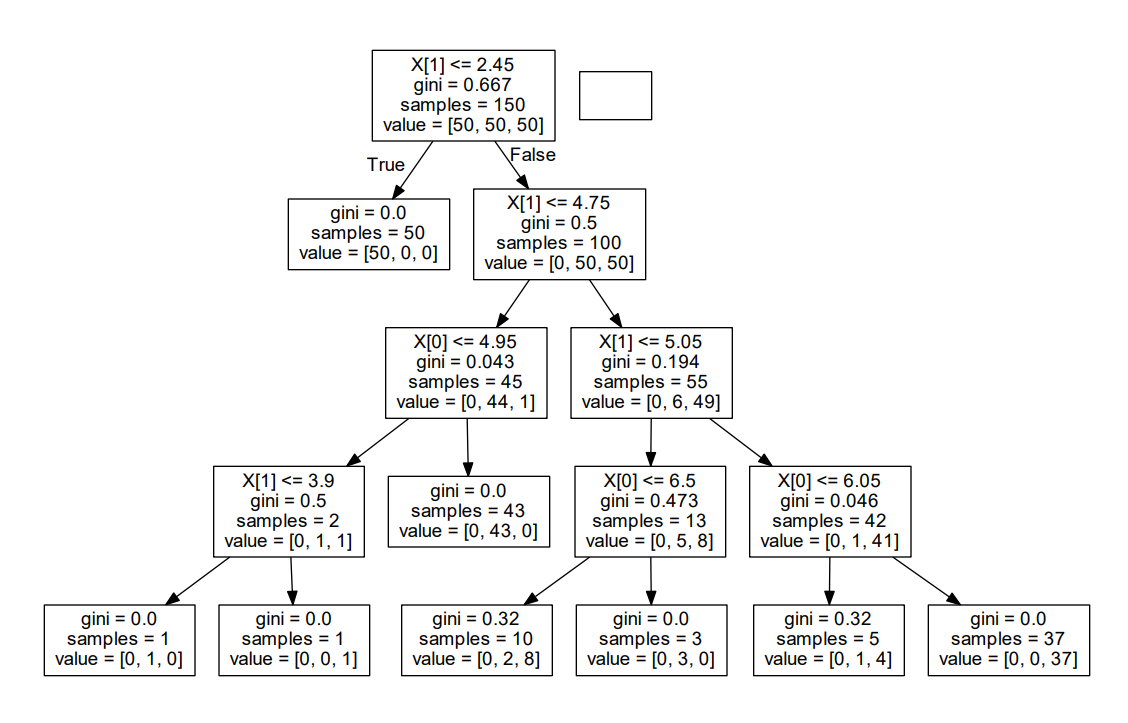
error: InvocationException: GraphViz’s executables not found The
source code is as follows
from itertools import product
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
# Still using the iris data that comes with it
iris = datasets.load_iris()
X = iris.data[:, [0, 2]]
y = iris.target
# Training the model, limiting the maximum depth of the tree to 4
clf = DecisionTreeClassifier(max_depth=4)
#Fitting the model
clf.fit(X, y)
# draw
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
plt.show()
There is no problem up to here, then start generating the image of the spanning tree, here is the code
from IPython.display import Image
from sklearn import tree
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
I started to report errors . I InvocationException: GraphViz's executables not found
learned through Baidu that the environment variables of graphviz were not configured properly,
but I didn’t know where my graphviz was installed,
so I used everything (a very useful software for finding files) to find my graphviz in the bin file. The location
and then edit the environment variables
and finally successfully run the code
brew update reports “fatal: Could not resolve HEAD to a revision”
When executing the brew update command:
% brew update
error:Not a valid ref: refs/remotes/origin/master
fatal: Could not resolve HEAD to a revision
Already up-to-date.
resolve
% brew update –verbose
% brew update -verbose
Checking if we need to fetch /opt/homebrew...
Checking if we need to fetch /opt/homebrew/Library/Taps/homebrew/homebrew-cask...
Fetching /opt/homebrew...
Checking if we need to fetch /opt/homebrew/Library/Taps/homebrew/homebrew-core...
Fetching /opt/homebrew/Library/Taps/homebrew/homebrew-core...
Fetching /opt/homebrew/Library/Taps/homebrew/homebrew-cask...
fatal: unable toaccess'https://github.com/Homebrew/homebrew-cask/': Failed to connect to github.com port443: Operation timed outError: Fetching /opt/homebrew/Library/Taps/homebrew/homebrew-cask failed!
Updating /opt/homebrew...
Branch 'master' set up to track remote branch 'master' from 'origin'.
Switched toand reset branch 'master'
Your branch is up to date with'origin/master'.
Switched toand reset branch 'stable'
Current branch stable is up to date.
Updating /opt/homebrew/Library/Taps/homebrew/homebrew-core...
fatal: Could not resolve HEAD to a revision
After the successful installation of mujoco_py, run the example in the built-in example and find an error: ERROR: GLEW initalization error: Missing GL version
Modify the configuration in .vimrc and add the following:
ERROR: GLEW initalization error: Missing GL version
Run the built-in example:
internal_functions.py multigpu_rendering.py
Environment variables need to be set:
export LD_PRELOAD=”
Otherwise, an error will be reported.
For a personal analysis of the environment variable export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libGLEW.so setting:
The mujuco211 version itself comes with the glew library, so when running mujuco-py to run the simulation, set export LD_PRELOAD=”
But when running the visual drawing, you need to call the glew library of the system. At this time, set export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libGLEW.so
If the glew library of the system is not called when drawing, a version error will be reported, and if the glew library of mujoco itself is not called when running the simulation, an error will also be reported.
The serialize_model.py substep_callback.py in the example does not need to set environment variables.
mjvive.py needs the support of VR SDK, etc., which is not considered here. (This should be run after you install HTC’s VR device client on your linux computer)
In Android development, to use the ToolBar control to replace the ActionBar control, you need to use the setSupportActionBar() method in the java code, as follows:
I found a method on the Internet, but it is ” Win10 Home Edition ” that cannot use this method, the specific operation can be found in the reference link at the end!!!!
Uncaught ReferenceError: $ is not defined (anonymous function)
The reason for this error:
1. The path of the jQuery library file is incorrect. Checking whether the file path is correct can usually solve the error.
2. If the path of the library file is correct, the order of loading the jQuery library file in the html may be wrong. If the jQuery library file is loaded in the first position, the error can be solved.
There are many reasons for mybatis to report an error: Invalid bound statement (not found), but just like the error message, the sql statement in the xml cannot be found. There are three types of errors:
Type 1: Syntax error
Java DAO layer interface
public void delete(@Param("id")String id);
Java corresponding mapper.xml file
<? xml version="1.0" encoding="UTF-8" ?>
<! DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis -3-mapper.dtd" >
< mapper namespace ="xxx.xxx.xxx.Mapper" >
<!-- delete data -->
< delete id ="delete" parameterType ="java.lang.String" >
DELETE FROM xxx WHERE id=#{id}
</ delete >
</ mapper >
Check: 1. Whether the method name (delete) in the interface is consistent with the id=”delete” in the xml file
2. Whether the path in namespace=”xxx.xxx.xxx.Mapper” in the xml file is consistent with the path of the interface file
3. Whether parameterType and resultType are accurate; resultMap and resultType are different.
Second: compile error
Navigate to the project path: under the error path in target\classes\, find out whether the corresponding xml file exists.
(1) If there is no corresponding xml file, you need to add the following code to pom.xml:
Delete the files in the classes folder, recompile, and the corresponding xml file appears.
(2) If there is an xml file, open the xml file and check whether the error part is consistent with the source file and inconsistent, then
First clear the files in the classes folder, execute the command: mvn clean to clean up the content, and then recompile.
The third type: configuration error
There was a problem with the configuration path when specifying scan packages in the project configuration file. For example: the specification of the “basePackage” property package name in the spring configuration file must be specific to the package where the interface is located, and do not write the parent or even higher-level package, otherwise problems may occur; cn.dao and cn.* may also cause errors ; Note that when scanning, the package may not be scanned.
Fourth: Referenced dependency package error
The project has always been running normally. When I recompiled the project one day, I found that this error has been reported all the time. I checked it again according to the previous three methods, and the error is still reported. Finally, I suddenly remembered that the company released a message a few days ago, saying that there are several internal dependency packages updated, because I wrote [xxx,) in the pom.xml file, and the latest dependency package will be automatically referenced. Then I modified the pom.xml file, returned the version to the old version, and after recompiling, the problem was solved.
Possible reason 1: The installed library is not the corresponding python version. In the downloaded library name, cp27 represents python2.7, and the same is true for others.
Possible reason 2: This is the situation I encountered (downloaded the corresponding version of the library, and then still prompted that the current platform is not supported)
Hue reports the following error when running hive sql
java.lang.IllegalStateException: Connection to remote Spark driver was lost
View the yarn error log as follows
Container [pid= 41355 ,containerID=container_1451456053773_0001_01_000002] is running beyond physical memory limits.
Current usage: 2.0 GB of 2 GB physical memory used; 5.2 GB of 4.2 GB virtual memory used. Killing container.
Probably the job run exceeded the memory size set by map and reduce, causing the task to fail. Adjustment increased the content of map and reduce, and the problem was eliminated. Some parameters are described as follows:
The memory resource configuration of RM is mainly carried out through the following two parameters (these two values are characteristics of the Yarn platform and should be configured in yarn-site.xml):
yarn.scheduler.minimum-allocation-mb
yarn.scheduler.maximum-allocation-mb
Description: The minimum and maximum memory that a single container can apply for. The application cannot exceed the maximum value when running the application for memory. If it is less than the minimum value, the minimum value is allocated. From this point of view, the minimum value is somewhat similar to that in the operating system. Page. The minimum value has another purpose, calculating the maximum number of containers of a node Note: Once these two values are set, they cannot be changed dynamically (the dynamic change mentioned here refers to the runtime of the application).
The memory resource configuration of NM is mainly carried out through the following two parameters (these two values are the characteristics of Yarn platform and should be configured in yarn-sit.xml):
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.vmem -pmem-ratio
Description: The maximum memory available per node, the two values in RM should not exceed this value. This value can be used to calculate the maximum number of containers, that is: divide this value by the minimum container memory in the RM. The virtual memory rate is the percentage of the memory used by the task. The default value is 2.1 times; Note: The first parameter cannot be modified. Once set, it cannot be dynamically modified during the entire running process, and the default size of this value is 8G, even if If the computer memory is less than 8G, it will also be used according to the 8G memory.
The parameters related to AM memory configuration are described here by taking MapReduce as an example (these two values are AM characteristics and should be configured in mapred-site.xml), as follows:
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
Description: These two parameters specify the memory size of the two tasks (Map and Reduce tasks) used for MapReduce, and their value should be between the maximum and minimum containers in the RM. If there is no configuration, it can be obtained by the following simple formula:
max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
The general reduce should be twice the map. Note: These two values can be changed through parameters when the application starts;
other memory-related parameters in AM, as well as JVM-related parameters, can be configured through the following options:
mapreduce.map.java.opts
mapreduce.reduce .java.opts
Description: These two parameters are mainly prepared for running JVM programs (java, scala, etc.), and parameters can be passed to the JVM through these two settings. Memory-related, -Xmx, -Xms and other options. The size of this value should be between map.mb and reduce.mb in AM.
We summarize the above content. When configuring Yarn memory, we mainly configure the following three aspects: the physical memory limit available for each Map and Reduce; the JVM size limit for each task; the virtual memory limit;
the following Through a specific error example, the memory-related description is given. The error is as follows:
Container[pid=41884,containerID=container_1405950053048_0016_01_000284] is running beyond virtual memory limits. Current usage: 314.6 MB of 2.9 GB physical memory used; 8.7 GB of 6.2 GB virtual memory used. Killing container. The
configuration is as follows:
Through the configuration, we can see that the minimum memory and maximum memory of the container are: 3000m and 10000m respectively, and the default value set by reduce is less than 2000m, and the map is not set, so both values are 3000m, which is “2.9 GB physical” in the log
memory used”. Since the default virtual memory rate (that is, 2.1 times) is used, the total virtual memory for both Map Task and Reduce Task is 3000*2.1=6.2G. The virtual memory of the application exceeds this value, so an error is reported.
Solution : Adjust the virtual memory rate when starting Yarn or adjust the memory size when the application is running.
Summary: This solution is to modify the yarn.scheduler.minimum-allocation-mb parameter to 6000 and solve it.