Recently in the project, I found that when I contracted out two machines, one of them was slow to collect. I wanted to take a look at the package. Before, I just looked at the package.
This time I really care about the window. At first glance, I think it’s strange. I used the following command to catch the bag:
tcpdump-ieth0tcpandport9981-w/data/steven/tcpdump/tcpdump.cap-C1-s0&
Mainly is – C, limits the file size to 1m to cut the file. Because the two programs are connected for a long time, there is no syn handshake process for the packets caught in the middle.
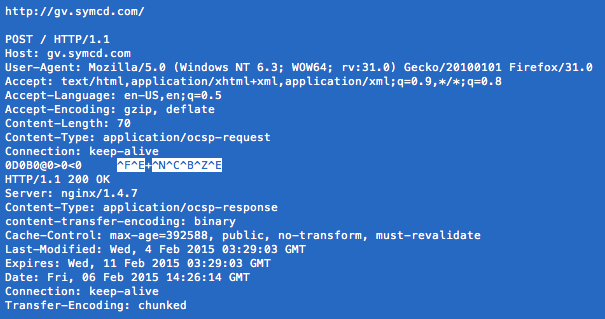
Looking at the data, I think it’s very strange.

99 machine told 100 machine, win = 36, but then 100 sent a len = 180 data to 99, which is not in line with the implementation of sliding window!
For a long time, I didn’t find the relevant information, because the method I used to check was wrong. Later, I asked my colleagues to restart the program and catch another bag with a handshake
Syn package, a look, it seems to be more normal:

This package win looks a bit normal, although there is still a problem, 99 win is much smaller than 100. Why do I think the first bag is abnormal
Because RFC has said that MSS Ethernet is 1460 bytes (1500 – 40), and the minimum MSS seems to be 536 bytes (576, the minimum number of bytes of reorganization buffer – 40).
Click on the syn package, and the following two fields attract my attention:
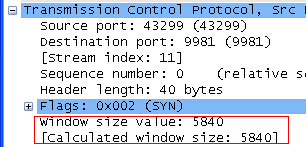
Google took a look at Wireshark window size value calculated window size and found two articles in the reference link
You can only look at the first one when you are surrounded by a wall
Since the TCP header window field is only 16bit, which represents 64K at most, an optional magnification is used to represent a larger window.
1. When TCP shakes hands three times, in syn or syn, ACK packet, inform options optional information, inform the other party that the amplification factor will be used.
2. Syn itself is not amplified
3. Therefore, the window size value represents the value of the message, and the calculated window size represents the enlarged value, that is, the actual available value
This value should be calculated by Wireshark for the sake of friendliness.
Back to the question I said at the beginning, I used the – C parameter when I tcpdump, that is, when the file exceeds 1m, it will be cut into multiple files, when your
When the file does not contain the three times handshake packet (SYN), Wireshark will not know your magnification, so the displayed value will have my question:
Why is win only 36 but can be len = 180.
As you can see, in the tcpdump file without syn package, Wireshark does not know your multiple, so – 1 (unknown) is displayed, and
The value win = 37 is displayed outside your package. If you calculate 128 to correct it (actually 128), the calculated window size is correct
It should show 37 * 128 = 4736, which is not much different from the following. It’s much bigger than 180. Of course, it can send 180.

The following package is caught in the included syn. He can tell you that the multiple is 128, which is actually 5760
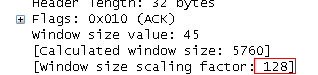
Finally, there are two questions about this matter:
Why are the windows on both sides so different when shaking hands?100 is at least 2.4 times of 99.
when TCP starts this magnification.
A: it seems that Linux has a kernel configuration parameter
a[ steven@KFJK ~]$ more /proc/sys/net/ipv4/tcp_ window_ Scaling
1
here is a brief description of [original] adjustment algorithm of TCP receiving window (Part 1)
“if the maximum value of receiving window is limited by TCP_ Rmem [2] = 4194304, then RCV_ Wscale = 7, and the window enlargement is 128. ”
and the setting of my system seems to be just right (but the factor is far more than that):
[ steven@KFJK ~]$ cat /proc/sys/net/ipv4/tcp_ Rmem
4096 87380 4194304
the article recommended by colleagues is good, TCP windows and window scaling
by the way, the article recommended by colleagues Wireshark TCP protocol analysis is also very good.
If you have time, you’d better read the detailed explanation of TCP/IP. Here are two articles written by an expert, fast food:
Things about TCP in coolshell (Part 1) and things about TCP (Part 2)