How to Solve SyntaxError: invalid character in identifier
Solution:
SyntaxError: invalid character in identifier
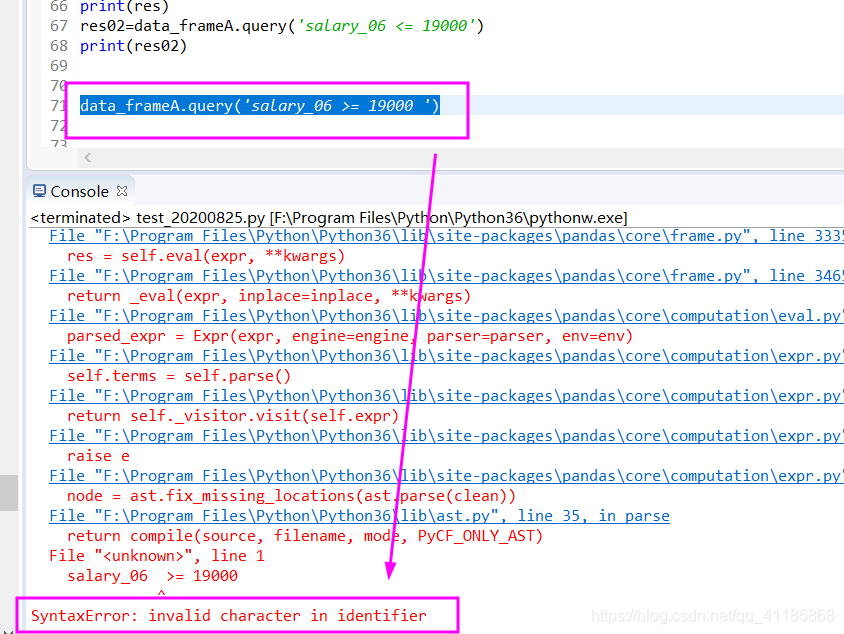
How to Solve SyntaxError: invalid character in identifier
SyntaxError: invalid character in identifier
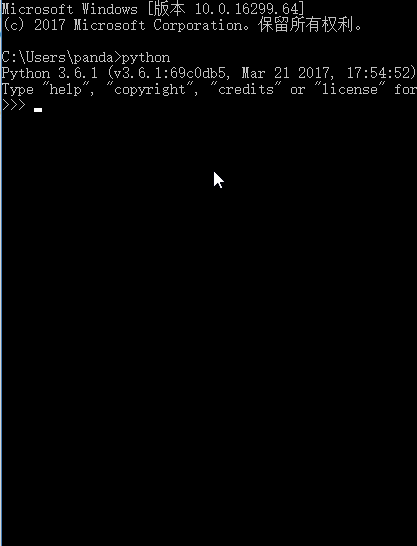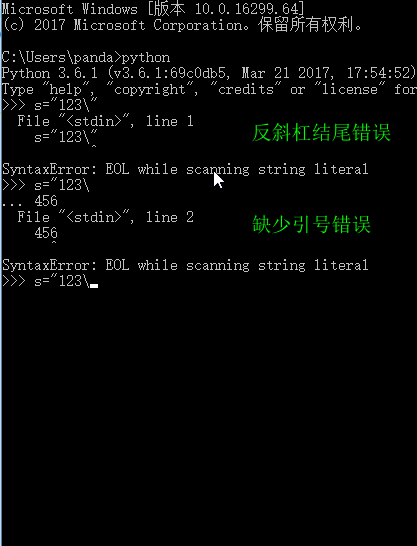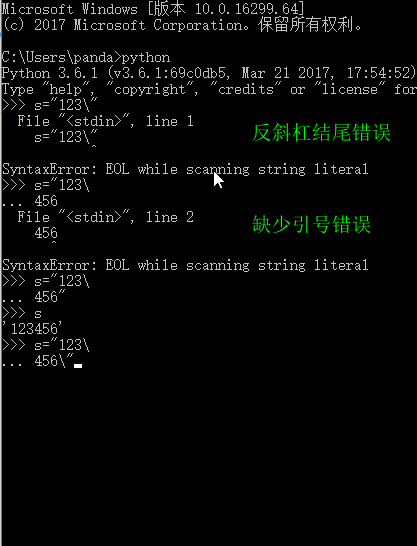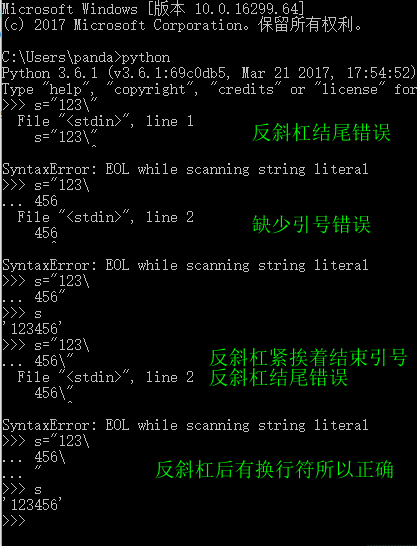
The cause of the error is that the string ends in or the string is missing quotation marks
This error occurs when writing code to splice windows path. Only by looking up the data can we know that the string in Python cannot end with \
My code is as follows
import os
dirname = "test"
path = r'C:\Users\panda\Desktop\newfile\' + dirnameWhen running, an error will be reported
File "test.py", line 3
path = r'C:\Users\panda\Desktop\newfile\' + dirname
^
SyntaxError: EOL while scanning string literalSo how to solve it
Method 1: use os.path.join
path = os.path.join(r'C:\Users\panda\Desktop\newfile', dirname)Method 2: the backslash of the path uses escape instead of R
path = 'C:\\Users\\panda\\Desktop\\newfile\\' + dirnameMethod 3: format string
dirname="test"
path = r'C:\Users\panda\Desktop\newfile\%s' % (dirname) # The first formatting method
#从 python 2.6 start
path = r'C:\Users\panda\Desktop\newfile\{}'.format(dirname) # The second formatting methodMethod 4: String interpolation
Support string interpolation from Python 3.6
# python 3.6 support string interpolation
dirname = "test"
path3 = rf'C:\Users\panda\Desktop\newfile\{dirname}' Reference: https://docs.python.org/3/whatsnew/3.6.html#whatsnew36 -pep498
Why can’t a string end with a (backslash)
Because backslashes have other uses. In Python, when a complete string is too long, a line cannot be written and you want to wrap it. However, if you want to keep it as a string, you can wrap it with a backslash. Therefore, the backslash cannot be immediately followed by the quotation mark at the end of the string
The following is a demonstration with repl
fs.js:143
throw new ERR_INVALID_CALLBACK(cb);
^
TypeError [ERR_INVALID_CALLBACK]: Callback must be a function. Received undefined
at makeCallback (fs.js:143:11)
at Object.unlink (fs.js:1024:14)
at D:\node\littleAlbum\controller\router.js:88:16
at IncomingForm.<anonymous> (D:\node\littleAlbum\node_modules\formidable\lib\incoming_form.js:107:9)
at IncomingForm.emit (events.js:210:5)
at IncomingForm._maybeEnd (D:\node\littleAlbum\node_modules\formidable\lib\incoming_form.js:557:8)
at D:\node\littleAlbum\node_modules\formidable\lib\incoming_form.js:238:12
at WriteStream.<anonymous> (D:\node\littleAlbum\node_modules\formidable\lib\file.js:79:5)
at Object.onceWrapper (events.js:299:28)
at WriteStream.emit (events.js:210:5) {
code: 'ERR_INVALID_CALLBACK'
}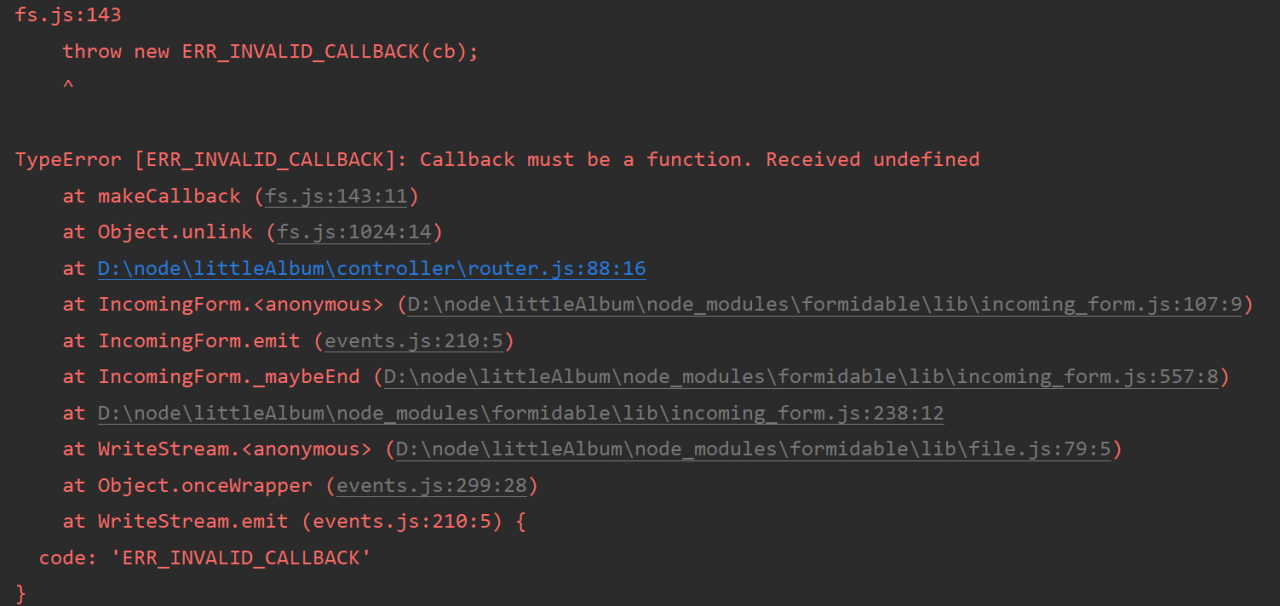
Reason:
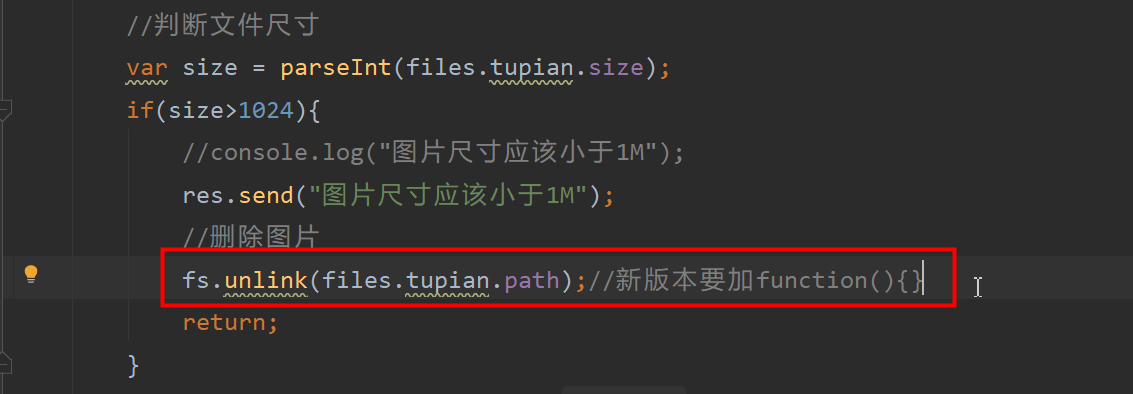
Solution:

The load function is read_ The specific parameters of Excel () are as follows
read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None,names=None, parse_cols=None, parse_dates=False,date_parser=None,na_values=None,thousands=None, convert_float=True, has_index_names=None, converters=None,dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)
Common parameter analysis:
io : string, path object ; Excel path
sheetname: string, int, mixed list of Strings/ints, or none, default 0 returns multiple tables, use sheetname = [0,1], if sheetname = none returns the whole table, note: int/String returns dataframe, while none and list return Dict Of dataframe
header: int, list of ints, default 0 specifies the column name row, default 0, that is, take the first row, the data is the data below the column name row, if the data does not contain the column name, set header = none
skirows: list like, rows to skip at the beginning
skip_ Footer: int, default 0, omit the int line data from the tail
index_ Col: int, list of ints, default none specifies that the column is an index column. You can also use U “strings”
Names: array like, default none, specifies the name of the column
Data source:
sheet1:
ID NUM-1 NUM-2 NUM-3
36901 142 168 661
36902 78 521 602
36903 144 600 521
36904 95 457 468
36905 69 596 695
sheet2:
ID NUM-1 NUM-2 NUM-3
36906 190 527 691
36907 101 403 470
(1) Function prototype
basestation ="F://pythonBook_PyPDAM/data/test.xls"
data = pd.read_excel(basestation)
print data
Output: a dataframe
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
(2) Sheetname parameter: use sheetname = [0,1] to return multiple tables. If sheetname = none, return the whole table. Note: int/String returns dataframe, while none and list return Dict Of dataframe
data_1 = pd.read_excel(basestation,sheetname=[0,1])
print data_1
print type(data_1)
Output: dict of dataframe
OrderedDict([(0, ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695),
(1, ID NUM-1 NUM-2 NUM-3
0 36906 190 527 691
1 36907 101 403 470)])
(3) Header parameter: specify the row of column name, 0 by default, that is, the first row. The data is the data below the row of column name. If the data does not contain column name, set header = none. Note that there is a row of column name here
data = pd.read_excel(basestation,header=None)
print data
Output:
0 1 2 3
0 ID NUM-1 NUM-2 NUM-3
1 36901 142 168 661
2 36902 78 521 602
3 36903 144 600 521
4 36904 95 457 468
5 36905 69 596 695
data = pd.read_excel(basestation,header=[3])
print data
Output:
36903 144 600 521
0 36904 95 457 468
1 36905 69 596 695
(4) Skirows parameter: omits the data with the specified number of rows
data = pd.read_excel(basestation,skiprows = [1])
print data
Output:
ID NUM-1 NUM-2 NUM-3
0 36902 78 521 602
1 36903 144 600 521
2 36904 95 457 468
3 36905 69 596 695
(5)skip_ Footer parameter: omits the data from the int line of the tail number
data = pd.read_excel(basestation, skip_footer=3)
print data
Output:
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
(6)index_ Col parameter: specify column as index column, or use U “strings”
data = pd.read_excel(basestation, index_col="NUM-3")
print data
output:
ID NUM-1 NUM-2
NUM-3
661 36901 142 168
602 36902 78 521
521 36903 144 600
468 36904 95 457
695 36905 69 596
(7) Name parameter: Specifies the name of the column
data = pd.read_excel(basestation,names=["a","b","c","e"])
print data
a b c e
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
The specific parameters are as follows
>>> print help(pandas.read_excel)
Help on function read_excel in module pandas.io.excel:
read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None, parse_cols=None, parse_dates=False, date_parser=None, na_values=None, thousands=None, convert_float=True, has_index_names=None, converters=None, dtype=None, true_values=None, false_values=None, engine=None, squeeze=False, **kwds)
Read an Excel table into a pandas DataFrame
Parameters
----------
io : string, path object (pathlib.Path or py._path.local.LocalPath),
file-like object, pandas ExcelFile, or xlrd workbook.
The string could be a URL. Valid URL schemes include http, ftp, s3,
and file. For file URLs, a host is expected. For instance, a local
file could be file://localhost/path/to/workbook.xlsx
sheetname : string, int, mixed list of strings/ints, or None, default 0
Strings are used for sheet names, Integers are used in zero-indexed
sheet positions.
Lists of strings/integers are used to request multiple sheets.
Specify None to get all sheets.
str|int -> DataFrame is returned.
list|None -> Dict of DataFrames is returned, with keys representing
sheets.
Available Cases
* Defaults to 0 -> 1st sheet as a DataFrame
* 1 -> 2nd sheet as a DataFrame
* "Sheet1" -> 1st sheet as a DataFrame
* [0,1,"Sheet5"] -> 1st, 2nd & 5th sheet as a dictionary of DataFrames
* None -> All sheets as a dictionary of DataFrames
header : int, list of ints, default 0
Row (0-indexed) to use for the column labels of the parsed
DataFrame. If a list of integers is passed those row positions will
be combined into a ``MultiIndex``
skiprows : list-like
Rows to skip at the beginning (0-indexed)
skip_footer : int, default 0
Rows at the end to skip (0-indexed)
index_col : int, list of ints, default None
Column (0-indexed) to use as the row labels of the DataFrame.
Pass None if there is no such column. If a list is passed,
those columns will be combined into a ``MultiIndex``. If a
subset of data is selected with ``parse_cols``, index_col
is based on the subset.
names : array-like, default None
List of column names to use. If file contains no header row,
then you should explicitly pass header=None
converters : dict, default None
Dict of functions for converting values in certain columns. Keys can
either be integers or column labels, values are functions that take one
input argument, the Excel cell content, and return the transformed
content.
dtype : Type name or dict of column -> type, default None
Data type for data or columns. E.g. {'a': np.float64, 'b': np.int32}
Use `object` to preserve data as stored in Excel and not interpret dtype.
If converters are specified, they will be applied INSTEAD
of dtype conversion.
.. versionadded:: 0.20.0
true_values : list, default None
Values to consider as True
.. versionadded:: 0.19.0
false_values : list, default None
Values to consider as False
.. versionadded:: 0.19.0
parse_cols : int or list, default None
* If None then parse all columns,
* If int then indicates last column to be parsed
* If list of ints then indicates list of column numbers to be parsed
* If string then indicates comma separated list of Excel column letters and
column ranges (e.g. "A:E" or "A,C,E:F"). Ranges are inclusive of
both sides.
squeeze : boolean, default False
If the parsed data only contains one column then return a Series
na_values : scalar, str, list-like, or dict, default None
Additional strings to recognize as NA/NaN. If dict passed, specific
per-column NA values. By default the following values are interpreted
as NaN: '', '#N/A', '#N/A N/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan',
'1.#IND', '1.#QNAN', 'N/A', 'NA', 'NULL', 'NaN', 'nan'.
thousands : str, default None
Thousands separator for parsing string columns to numeric. Note that
this parameter is only necessary for columns stored as TEXT in Excel,
any numeric columns will automatically be parsed, regardless of display
format.
keep_default_na : bool, default True
If na_values are specified and keep_default_na is False the default NaN
values are overridden, otherwise they're appended to.
verbose : boolean, default False
Indicate number of NA values placed in non-numeric columns
engine: string, default None
If io is not a buffer or path, this must be set to identify io.
Acceptable values are None or xlrd
convert_float : boolean, default True
convert integral floats to int (i.e., 1.0 --> 1). If False, all numeric
data will be read in as floats: Excel stores all numbers as floats
internally
has_index_names : boolean, default None
DEPRECATED: for version 0.17+ index names will be automatically
inferred based on index_col. To read Excel output from 0.16.2 and
prior that had saved index names, use True.
Returns
The storage function is pd.dataframe.to_ Excel (), note that dataframe must be written into excel, that is, write dataframe to an excel sheet. The specific parameters are as follows:
to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None,columns=None, header=True, index=True, index_label=None,startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,
inf_rep='inf', verbose=True, freeze_panes=None)
Explanation of common parameters:
excel_writer: string or ExcelWriter object File path or existing ExcelWriter Target Path
sheet_name: string, default ‘Sheet1’ Name of sheet which will contain DataFrame, Fill the pages of excel
na_rep: string, default ”,Missing data representation Missing value fill
float_format: string, default None Format string for floating point numbers
columns: sequence, optional,Columns to write Select the output column.
header: boolean or list of string, default True Write out column names. If a list of string is given it is assumed to be aliases for the column names
index: boolean, default True,Write row names (index)
index_label : string or sequence, default None, Column label for index column(s) if desired. If None is given, andheader and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex.
startrow: upper left cell row to dump data frame
startcol: upper left cell column to dump data frame
engine: string, default None ,write engine to use – you can also set this via the options,io.excel.xlsx.writer, io.excel.xls.writer, andio.excel.xlsm.writer.
merge_cells: boolean, default True Write MultiIndex and Hierarchical Rows as merged cells.
encoding: string, default None encoding of the resulting excel file. Only necessary for xlwt,other writers support unicode natively.
inf_rep: string, default ‘inf’ Representation for infinity (there is no native representation for infinity in Excel)
freeze_panes: tuple of integer (length 2), default None Specifies the one-based bottommost row and rightmost column that is to be frozen
Codes:
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
5 36906 165 453
datas:
basestation ="F://python/data/test.xls"
basestation_end ="F://python/data/test_end.xls"
data = pd.read_excel(basestation)
(1) Parameter Excel_ Writer, output path
data.to_excel(basestation_end)
Output:
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
5 36906 165 453
(2)sheet_ Name, store the data in the sheet page of Excel
data.to_excel(basestation_end,sheet_name="sheet2")
(3)na_ Rep, missing value filling
data.to_excel(basestation_end,na_rep="NULL")
Output:
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
5 36906 165 453 NULL
(4) Columns parameters: sequence, optional, columns to write select the output column
data.to_excel(basestation_end,columns=["ID"])
Output:
ID
0 36901
1 36902
2 36903
3 36904
4 36905
5 36906
(5) Header parameter: Boolean or list of string, which is true by default. You can use list to name columns. If header = false, no header will be output
data.to_excel(basestation_end,header=["a","b","c","d"])
Output:
a b c d
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
5 36906 165 453
data.to_excel(basestation_end,header=False,columns=["ID"])
header = False
Output:
0 36901
1 36902
2 36903
3 36904
4 36905
5 36906
(6) Index: Boolean, default true, write row names (index) is true by default, and the index is displayed. When index = false, the row index (name) is not displayed. index_ Label: string or sequence, default none set the column name of the index column
data.to_excel(basestation_end,index=False)
Output:
ID NUM-1 NUM-2 NUM-3
36901 142 168 661
36902 78 521 602
36903 144 600 521
36904 95 457 468
36905 69 596 695
36906 165 453
data.to_excel(basestation_end,index_label=["f"])
Output:
f ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
5 36906 165 453 When creating canvas with Python and importing images on the canvas, an error occurs_ tkinter.TclError: couldn’t recognize data in image file “F:\Python\test\a.gif””
Tkinter can only load GIF images, that is. GIF extension of the image file, want to display other types of images, such as PNG or JPG, need to use other modules
def canvas_test():
import tkinter
window = tkinter.Tk()
window.geometry('600x400')
window.title('This is Canvas')
#Create a canvas of 550 * 300
canvas = tkinter.Canvas(window, bg='green', width=550, height=300)
# Create the image on the canvas and place the imported image
image_file = tkinter.PhotoImage(file="F:\\Python\\test\\a.gif")
image = canvas.create_image(300, 10, anchor='n', image=image_file)
canvas.pack()
window.mainloop()Looking for a solution on the Internet, I learned that changing the image suffix can’t change the image format( Online reference: https://stackoverflow.com/questions/28740462/tkinter-couldnt-recognize-data-in-image-file )
So, search Baidu again for a GIF image, download it and name it c.gif (or d.jpg). As long as you save the image in GIF image format, run the following code:
def canvas_test():
import tkinter
window = tkinter.Tk()
window.geometry('600x400')
window.title('This is Canvas')
#Create a canvas of 550 * 300
canvas = tkinter.Canvas(window, bg='green', width=550, height=300)
# Create the image on the canvas and place the imported image
#image_file = tkinter.PhotoImage(file="F:\\gao\\Python\\test\\c.gif")
image_file = tkinter.PhotoImage(file="F:\\gao\\Python\\test\\d.jpg")
image = canvas.create_image(300, 10, anchor='n', image=image_file)
canvas.pack()
window.mainloop()The code runs normally, the picture is displayed normally, only the static picture is displayed
photo image only depends on the type of the image itself, and has nothing to do with the suffix of the image name
PIP install installs the third-party plug-in, and the URL of “could not fetch” appears https://pypi.python.org/simple/pool/ : there was a problem confirming SSL certificate
The solution is as follows:
create pip.ini in the python installation directory, and the configuration content of pip.ini is as follows:
0
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.comThe environment variable has configured the path of Python in the path, so there is no need to configure the path here, and then download the third-party plug-in with PIP
Python version: 3.7
def exe_try():
try:
print("start")
raise KeyError
return 1
except KeyError as e:
print("key error")
return 2
else:
print("other")
return 3
finally:
print("finally")
# return 4
result = exe_try()
print(result)
# You can see that the result of its execution is:
# start
# key error
# finally
# 4
# exe_try function catches the KeyError exception, but why does it not return 2 but 4?
# Here is the use of the return statement in try except finally:
# If there is a return statement in finally, it returns the return statement in finally,
# If finally does not have a return statement, it returns the return statement from the previous call
# Execution process:
# When the exe_try function is executed, it prints start, and then encounters a KeyError exception.
# Then the exception is caught and the code block in except is executed: the key error is printed, and return 2 is executed
# But this return 2 does not return directly, but put it on the stack
# Then it goes on to the next block in finally: prints finally, and executes return 4
# Here it still doesn't return 4 directly, but puts it on the stack as well
# At this point the entire try except else finally are executed, it will take out the return at the top of the stack and return
# And the return in finally is put on the stack afterwards, so it's on the top of the stack, and returns 4.
# If there is no return statement in finally, it will return:
# start
# key error
# finally
# 2
def change(tupleTest):
tupleTest[0] = 2
tupleTest = (1, 2, 3)
change(tupleTest)
print(tupleTest)
The above code explodes the problem error
the solution is actually easier to understand
Tuple is only readable, and does not support writing. Therefore, there is a problem with tuple assignment
Generally, if you want to do operations similar to arrays in C/C + +, you’d better use list
instead of the following code to avoid similar errors
def change(tupleTest):
tupleTest[0] = 2
tupleTest = [1, 2, 3]
change(tupleTest)
print(tupleTest)
Although this name is still very unreliable
a suggestion for beginners of Python is that the name of the code is very important. Python is typeless (the type is not displayed obviously…)
Typeerror: super() takes at least 1 argument (0 given) error occurred when writing inheritance subclass
Source code (perfect to run in python3)
class Example(QWidget):
def __init__(self):
super().__init__()
self.initUI() #Interface drawing is given to the InitUi method
The reason is super ()__ init__() Function is supported in python3, which is correct, but it will cause problems in python2
If you want to inherit the construction method of the parent class in Python 2, you need to pass in the super parameter: Super (example, self)__ init__();
In python2, it should be written as follows:
class Example(QWidget):
def __init__(self):
super(Example,self).__init__()
self.initUI() #Interface drawing is given to the InitUi method
TypeError: __ init__() missing 1 required positional argument: ‘on_ Delete ‘solution
Error: typeerror: init() missing 1 required position argument: ‘on’ when executing Python manage.py makemigrations_ delete’
solutions:
when defining foreign keys, you need to add on_ delete=;
that is: contract = models. ForeignKey (contract, on)_ delete=models.CASCADE)
the reasons are as follows:
after Django is upgraded to 2.0, when tables are associated with each other, on must be written_ Delete parameter, otherwise an exception will be reported:
typeerror: init() missing 1 required position argument: ‘on’_ delete’
on_ Delete = none, # when deleting data in an associated table, the current table and its associated field behave
on_ Delete = models.cascade, # delete the associated data and delete the associated data
on_ delete=models.DO_ Noting, # delete associated data and do nothing
on_ Delete = models. Protect, # delete the associated data, causing the error protectederror
# models. ForeignKey (‘associated table ‘, on)_ delete=models.SET_ NULL, blank=True, null=True)
on_ delete=models.SET_ Null, # delete the associated data, and set the associated value to null (if FK field needs to be set to null, one-to-one is the same)
# models.foreignkey (‘association table ‘, on)_ delete=models.SET_ Default, default =’default ‘)
on_ delete=models.SET_ Default, # delete the associated data, and set the associated value as the default value (if FK field needs to set the default value, one-to-one is the same)
on_ Delete = models.set, # delete associated data,
A. set the associated value to the specified value, set: models.set (value)
B. set the associated value to the return value of executable object, set: models.set (executable object)
a
Because many to many (manytomanyfield) has no on_ Delete parameter, so the above is only for foreign key and one to one field