summary:
Login users can view the article details, and visitors can’t view the article details and report errors
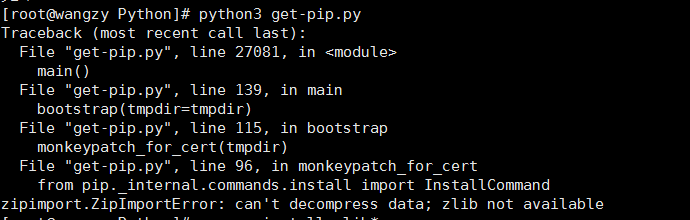
Error codes are as follows:
Starting development server at http://127.0.0.1:8000/
Quit the server with CTRL-BREAK.
--The above codes are basically to determine the identity of the visitor--
1
The value of next_topic is: <QuerySet [<Topic: Topic object (2)>, <Topic: Topic object (3)>]>
Internal Server Error: /v1/topics/qq66907360
Traceback (most recent call last):
File "D:\Program Files (x86)\Python\Python310\lib\site-packages\django\core\handlers\exception.py", line 47, in inner
response = get_response(request)
File "D:\Program Files (x86)\Python\Python310\lib\site-packages\django\core\handlers\base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "D:\Program Files (x86)\Python\Python310\lib\site-packages\django\views\generic\base.py", line 69, in view
return self.dispatch(request, *args, **kwargs)
File "D:\Program Files (x86)\Python\Python310\lib\site-packages\django\views\generic\base.py", line 101, in dispatch
return handler(request, *args, **kwargs)
File "D:\PycharmProjects\linuxTangblog\topic\views.py", line 151, in get
res = self.make_topic_res(author,author_topic,is_self)
File "D:\PycharmProjects\linuxTangblog\topic\views.py", line 29, in make_topic_res
next_id = next_topic.id if next_topic else None
AttributeError: 'QuerySet' object has no attribute 'id'
[17/Dec/2021 15:02:20] "GET /v1/topics/qq66907360?t_id=1 HTTP/1.1" 500 79151
Troubleshooting process:
After traversing the ‘queryset’ object, I found that the traversed data is an object object object, and then I took the value with the object value,
The value of next_topic is: <QuerySet [<Topic: Topic object (2)>, <Topic: Topic object (3)>]>
next_topic = Topic.objects.filter(id__gt=author_topic.id,author=author,limit='public')
for i in next_topic:
print(i.id)
Then I thought that the previous article and the next article only need one value, but obviously the queryset object has multiple values, which does not meet the expectation. Then I look at the code and find that the condition of first () or last () is not written
if is_self:
#Next
next_topic = Topic.objects.filter(id__gt=author_topic.id,author=author).first()
#previous
last_topic = Topic.objects.filter(id__lt=author_topic.id,author=author).last()
else:
next_topic = Topic.objects.filter(id__gt=author_topic.id,author=author,limit='public')
last_topic = Topic.objects.filter(id__lt=author_topic.id,author=author,limit='public')
Solution:
Add the condition of first() or last()
if is_self:
#Next
next_topic = Topic.objects.filter(id__gt=author_topic.id,author=author).first()
#previous
last_topic = Topic.objects.filter(id__lt=author_topic.id,author=author).last()
else:
next_topic = Topic.objects.filter(id__gt=author_topic.id,author=author,limit='public').first()
last_topic = Topic.objects.filter(id__lt=author_topic.id,author=author,limit='public').last()