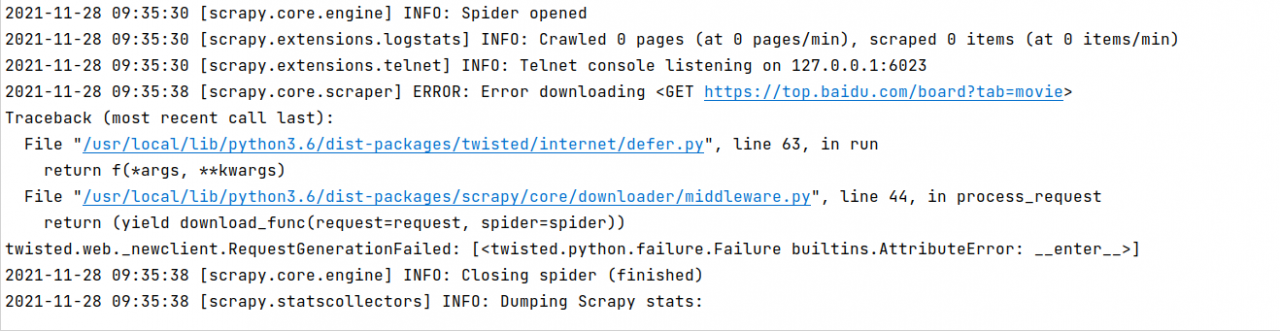
“PyAutoGUI was unable to import pyscreeze. (This is likely because you’re running a version of Python that Pillow (which pyscreeze depends on) doesn’t support currently.) Please install this module to enable the function you tried to call.” pyautogui.PyAutoGUIException: PyAutoGUI was unable to import pyscreeze. (This is likely because you’re running a version of Python that Pillow (which pyscreeze depends on) doesn’t support currently.) Please install this module to enable the function you tried to call.
solution:
pip install pyscreeze
Download the dependency package to solve the problem
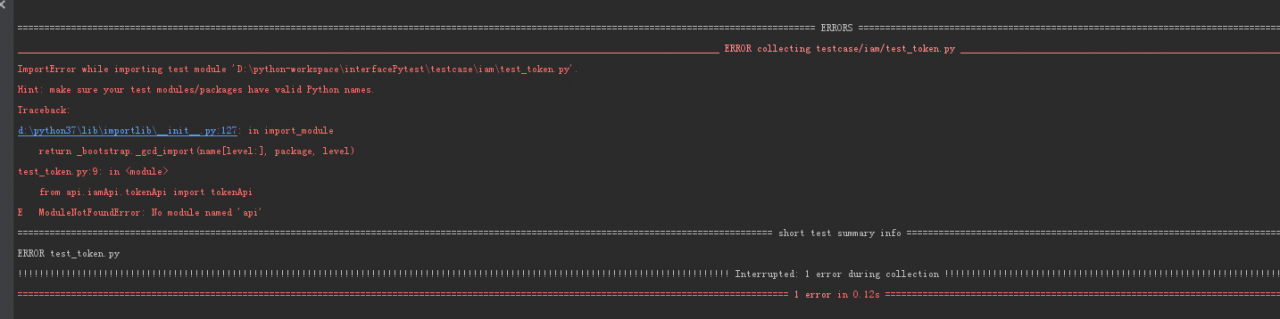
2. Because I used the python plug-in of idea, I didn’t choose my own Python installation path when I first created the python project, so idea automatically created a python running environment for me on disk F. however, the python commands I used on the command line and the downloaded packages are on disk d.. Finally, the problem was solved by changing the running environment:
File ➡ project Structure ➡ SDKs
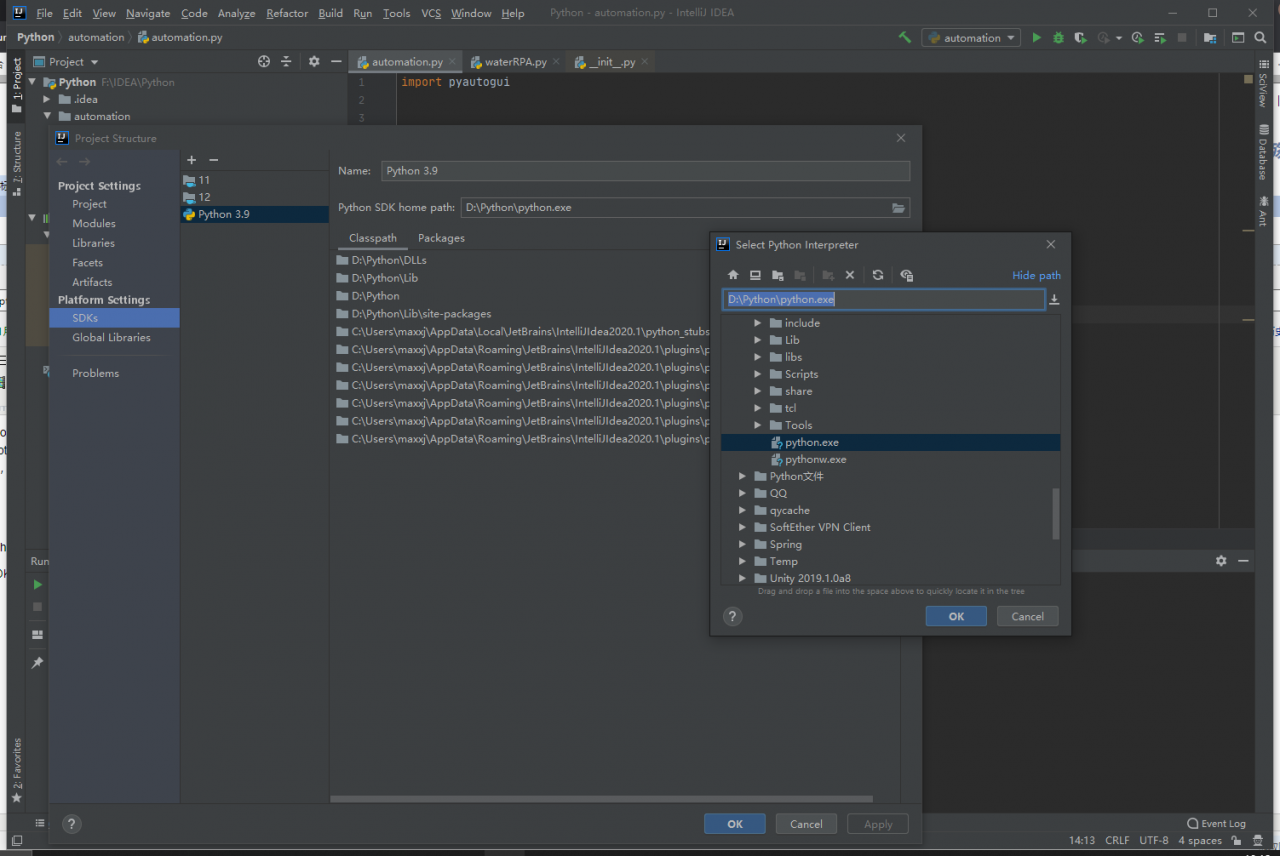
Select python.exe under your own Python directory
Then restart and reload the running environment