Error when executing statement:
![]()
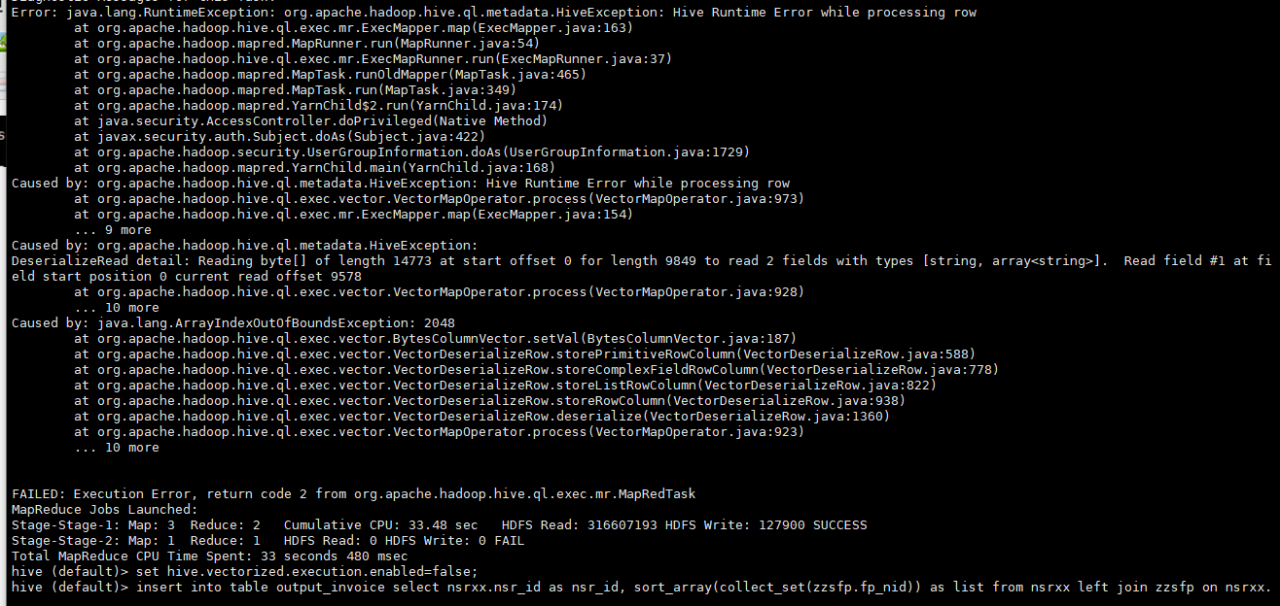
Solution:

set hive.vectorized.execution.enabled=false;
set hive.vectorized.execution.reduce.enabled=false;
Turn off vector query
Each time a vectorized query processes data, 1024 rows of data will be processed into a batch instead of one row at a time, which can significantly improve the execution speed.
Then it runs successfully
Similar Posts:
- Solution to GPU memory leak problem of tensorflow operation efficiency
- Using join buffer (Block Nested Loop)
- Hive1.1.0 startup error reporting Missing Hive Execution Jar: lib/hive-exec-*.jar
- Detailed explanation of yolo2 — yolo9000, better, faster, stronger
- The solution of failed to install Intel haxm error in Android studio installation
- [Hive on Tez] Input path does not exists error
- RuntimeError: DataLoader worker (pid(s) 24632, 26892, 10480, 2964) exited unexpectedly
- Hive SemanticException:Expression not in GROUP BY
- ERROR 3021 (HY000): This operation cannot be performed with a running slave io thread; run STOP SLAVE IO_THREAD FOR CHANNEL ” first.
- Tensorflowcenter {typeerror} non hashable type: “numpy. Ndarray”