The crawler crawls the pictorial 403 (when the URL gets the input stream 403), because the request header is missing
Error message: server returned HTTP response code: 403 for URL:
The http403 command is to prohibit malicious access to this website, and the content cannot be crawled from this website
If crawling is forbidden on the server side, you can cheat the server by setting the user agent
It’s not just about adding
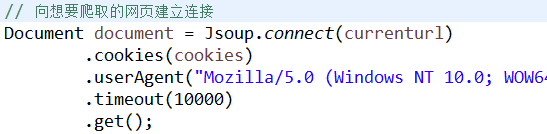
When downloading a picture, the request should be added

Similar Posts:
- How to Solve Python Error: crawler uses proxy anti blocking IP: http error 403: forbidden
- How to Solve Python Error: “HTTP Error 403: Forbidden”
- failed to open stream: HTTP request failed! HTTP/1.1 404 Not Found
- Python crawling picture prompt urllib.error.httperror: http error 403: forbidden solution
- The solution of ‘STR’ object has no attribute ‘get’ error
- Complete failure: http request failed!
- file_get_contents failed to open stream: HTTP request failed! HTTP/1.1 400 Bad Request
- [Solved] HTTP Error 301: The HTTP server returned a redirect error that would lead to an infinite loop.
- Unable to open thread: http request failed! (4 pesos, PHP 4)
- User timeout caused connection failure (exception record) of scrapy project