windows 10 home Chinese version, Python 3.6.4, scrapy 1.5.0,
tips: there are some problems in this article. Please do not read it if you really test it.
07-14 14:26 update:
After more than two hours of testing, it is found that the reason for this problem is that after the crawler was written yesterday, the following attributes were added to the crawler:
download_ timeout = 20
Explanation of this property:
The amount of time (in secs) that the downloader will wait before timing out.
It takes more than 20 seconds to get the robots.txt file of a website’s subdomain name. Therefore, even if there are three attempts, it will eventually fail
This value is 180 by default. Because a website is a domestic website, I think all its files will be downloaded very quickly. It doesn’t need to be 180, so I change it to 20. Who knows, robots.txt of its subdomain takes so long:
When the test period is changed to 30, the condition is good. At present, the setting of this value has been cancelled, and the required data can be captured
But why is robots.txt so slow to download
Delete the errback defined in the request for testing, can also get the required data
So what’s the use of defining errback in a request
Now, the dnslookuperror will not occur if you execute the following command again inside or outside the project (tested) (but how did it happen in the morning?):
scrapyshell” http://money.163.com/18/0714/03/DML7R3EO002580S6.html “
— the following parts can be ignored —
Yesterday, I wrote a crawler program to capture news data, but there was an error in capturing the data of a website: timeout, retrying… At first, it exceeded the default waiting time of 180 seconds. Later, I changed it to 20 seconds in the crawler program, so the figure below shows 20 seconds
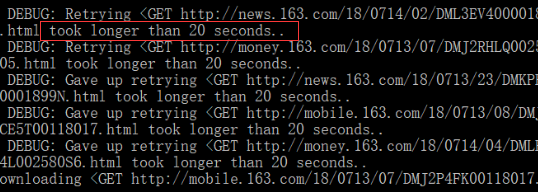
I don’t know what’s going on! Above is the use of scrapy project based on crawler runner program to run, do not see more data
Try to add allowed in the crawler_ Domains is tested in the following two forms (the second one will be used in the end) – think it has something to do with the subdomain name: it still fails
1 #allowed_domains = ['www.163.com', 'money.163.com', 'mobile.163.com',
2 # 'news.163.com', 'tech.163.com']
3
4 allowed_domains = ['163.com']Later, in settings.py, the robots.txt protocol was turned off and cookie support was turned on: still failed
1 # Obey robots.txt rules
2 ROBOTSTXT_OBEY = False
3
4 # Disable cookies (enabled by default)
5 COOKIES_ENABLED = TrueAt this point, relying on the previous knowledge reserve is unable to solve the problem
Using the scratch shell to test the webpage with timeout, we get the abnormal information of twisted.internet.error.dnslookuperror
scrapy shell ” http://money.163.com/18/0714/03/DML7R3EO002580S6.html “

![]()
However, the IP address of the failed subdomain can be obtained by using ping command:
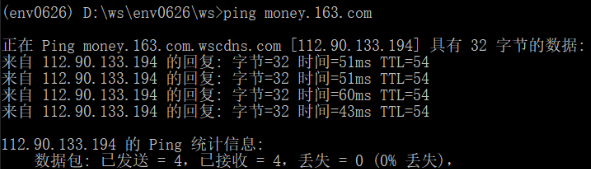
twisted as a very common Python library, how can such a problem happen! Not at all
Help the Internet! Finally, we find the following articles:
How do I catch errors with scrapy so I can do something when I get User Timeout error?
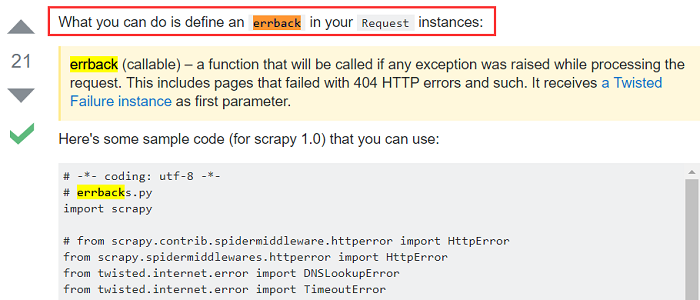
Best answer! Define errback in the request instance( Please read it three times)
So simple?What does it have to do with handling dnslookuperror errors?Why is it OK to define a callback function
Don’t understand, don’t act
Keep searching, no more
Well, try this method. Change the crawler program of a website as follows:
Added errback = self.errback_ 163, where the callback function errback_ 163 is written in the same way as in the reference article above (it was later found that it came from the official script requests and responses)
1 yield response.follow(item, callback = self.parse_a_new,
2 errback = self.errback_163)Ready, test the latest program with scape crawl (after restoring the previously modified configuration – comply with robots.txt protocol, prohibit cookies, allowed)_ Domains set to 163. Com): successfully captured the desired data
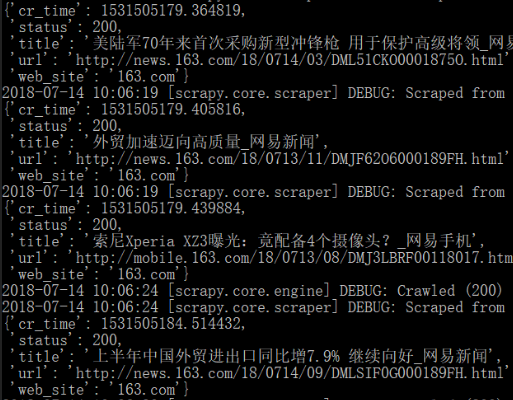
OK, the problem is solved. However, the previous question has not been solved ~ follow up dig it~“ The magic “errback~
Similar Posts:
- Spider Error: Scratch processing timeout [How to Solve]
- [reprint] extjs sets the timeout of Ajax request
- Composite graph + cookie free domains
- Nginx Timeout Error: upstream timed out (110: Connection timed out) while reading response header from ups…
- Error Code: 2006 – MySQL server has gone away
- Two solutions to cross origin read blocking (CORB) blocked cross origin response error of Web Service API
- MySQL external import data error [How to Solve]
- AWStats Vs Webalizer Vs Google Analytics Visito…
- How to Solve Error: Server returned HTTP response code: 403 for URL:
- java.io.IOException: Server returned HTTP response code: 405 for URL: