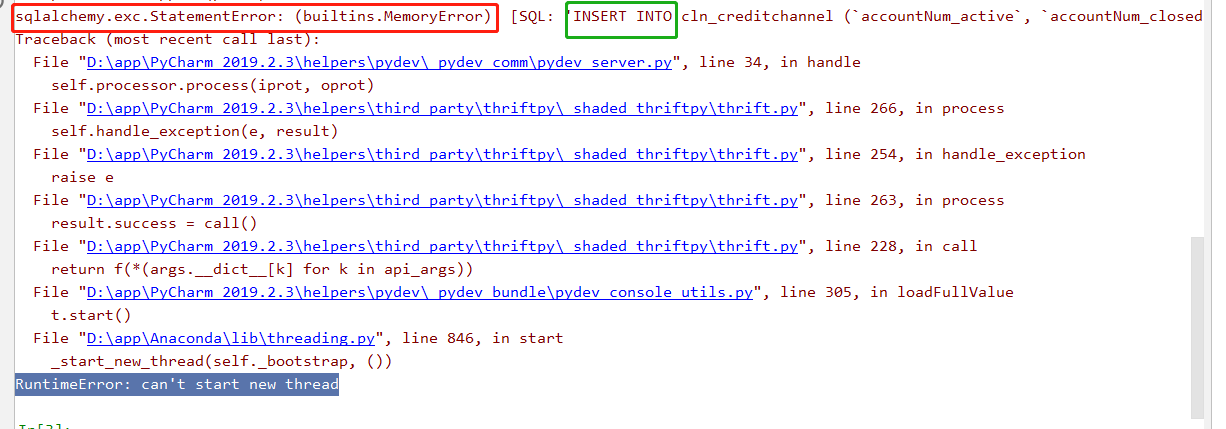
Obviously I just simply ran a python script for data cleaning 28W data, somehow it reported the following error.
too many threads running within your python process
The “can’t start new thread” error almost certainly due to the fact that you have already have too many threads running within your python process,
and due to a resource limit of some kind the request to create a new thread is refused. You should probably look at the number of threads you’re creating; the maximum number you will be able to create will be determined by your environment,
but it should be in the order of hundreds at least. It would probably be a good idea to re-think your architecture here;
seeing as this is running asynchronously anyhow, perhaps you could use a pool of threads to fetch resources from another site instead of always starting up a thread for every request. Another improvement to consider is your use of Thread.join and Thread.stop; this would probably be better accomplished by providing a timeout value to the constructor of HTTPSConnection.
Similar Posts:
- MonkeyPatchWarning: Monkey-patching ssl after ssl has already been imported may lead to errors
- Flink Project Start Error: java.lang.OutOfMemoryError: unable to create new native thread [How to Solve]
- Python AttributeError: ‘unicode’ object has no attribute ‘tzinfo’
- [Solved] std::thread “terminate called without an active exception”
- Stackexchange.redis timeout performing timeout problem
- Stackexchange.redis timeout performing timeout problem
- Paramiko Error: Garbage packet received [How to Solve]
- Redis uses connection pool to solve the problem of error reporting
- [How to Solve] Starting MySQL.. ERROR! The server quit without updating PID file
- How to deal with the exception of database connection pool in Python flash