#Solution: The created shortcut needs to add the starting position StartIn=str(target).replace(s, "")
import winshell
import os
def create_shortcut_to_desktop():
target = sys.argv[0]
title = 'XX shortcut'
s = os.path.basename(target)
fname = os.path.splitext(s)[0]
winshell.CreateShortcut(
Path=os.path.join(winshell.desktop(), fname + '.lnk'),
StartIn=str(target).replace(s, ""),
Target=target,
Icon=(target, 0),
Description=title)
def delete_shortcut_from_startup():
target = sys.argv[0]
s = os.path.basename(target)
fname = os.path.splitext(s)[0]
# delfile = micpath.join(winshell.startup(), fname + '.lnk')
delfile = os.path.join(winshell.desktop(), fname + '.lnk')
if os.path.exists(delfile):
winshell.delete_file(delfile)
CentOS8 Failed to start docker.service: Unit docker.service not found [How to Solve]
The reason for this problem is the podman in CentOS 8. Podman is a docker like software preinstalled in CentOS 8, so you don’t need to uninstall it directly
solution:
dnf remove podman
Then reinstall docker
sudo yum install -y yum-utils device-mapper-persistent-data lvm2 sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo yum install -y docker-ce docker-ce-cli containerd.io
Set startup and self startup
sudo systemctl enable docker
Oh!
[Solved] puppeteer Install Error: Failed to download Chromium
There are many solutions on the Internet. Most of them are to modify the chromium download source, or use cnpm, or skip the download and manually download chromium on the official website.
The self-test is not very easy to use.
Find the solution of international friends from the issue of puppeter.
Solution:
npm install puppeteer --unsafe-perm=true --allow-root
failure: repodata/filelists.sqlite.bz2 from teamviewer: [Errno 256] No more mirrors to try
When installing CHD, enter Yum install cloudera-manager-agent-6.2.1-1426065. el7.x86_64.rpm – y error
[root@master x86_64]# yum install cloudera-manager-agent-6.2.1-1426065.el7.x86_64.rpm -y
Loaded plugins: fastestmirror, langpacks
Checking cloudera-manager-agent-6.2.1-1426065.el7.x86_64.rpm: cloudera-manager-agent-6.2.1-1426065.el7.x86_64
cloudera-manager-agent-6.2.1-1426065.el7.x86_64.rpm will be installed
Resolving dependencies
--> Checking the transaction
---> Package cloudera-manager-agent.x86_64.0.6.2.1-1426065.el7 will be installed
--> Processing the dependency /lib/lsb/init-functions, which is required by the package cloudera-manager-agent-6.2.1-1426065.el7.x86_64
Loading mirror speeds from cached hostfile
* base: mirrors.bupt.edu.cn
* extras: mirrors.bupt.edu.cn
* updates: mirrors.bupt.edu.cn
base/7/x86_64/filelists_db | 7.2 MB 00:00:04
extras/7/x86_64/filelists_db | 259 kB 00:00:00
mysql-connectors-community/x86_64/filelists_db | 120 kB 00:00:00
mysql-tools-community/x86_64/filelists_db | 414 kB 00:00:00
mysql57-community/x86_64/filelists_db | 1.6 MB 00:00:00
teamviewer/x86_64/filelists_db | 106 kB 00:00:00
https://linux.teamviewer.com/yum/stable/main/binary-x86_64/repodata/filelists.sqlite.bz2: [Errno -1] Metadata file does not match checksum
Trying another mirror.
One of the configured repositories failed (TeamViewer - x86_64),
and yum doesn't have enough cached data to continue. At this point the only
safe thing yum can do is fail. There are a few ways to work "fix" this:
1. Contact the upstream for the repository and get them to fix the problem.
2. Reconfigure the baseurl/etc. for the repository, to point to a working
upstream. This is most often useful if you are using a newer
distribution release than is supported by the repository (and the
packages for the previous distribution release still work).
3. Run the command with the repository temporarily disabled
yum --disablerepo=teamviewer ...
4. Disable the repository permanently, so yum won't use it by default. Yum
will then just ignore the repository until you permanently enable it
again or use --enablerepo for temporary usage:
yum-config-manager --disable teamviewer
or
subscription-manager repos --disable=teamviewer
5. Configure the failing repository to be skipped, if it is unavailable.
Note that yum will try to contact the repo. when it runs most commands,
so will have to try and fail each time (and thus. yum will be be much
slower). If it is a very temporary problem though, this is often a nice
compromise:
yum-config-manager --save --setopt=teamviewer.skip_if_unavailable=true
failure: repodata/filelists.sqlite.bz2 from teamviewer: [Errno 256] No more mirrors to try.
https://linux.teamviewer.com/yum/stable/main/binary-x86_64/repodata/filelists.sqlite.bz2: [Errno -1] Metadata file does not match checksum
Solution:
yum clean all yum makecache
[Solved] Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
1. An error is reported when running the serialization test of the local cluster
[INFO]
[INFO] --- exec-maven-plugin:3.0.0:exec (default-cli) @ HadoopWritable ---
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Exception in thread "main" java.io.IOException: Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses.
at org.apache.hadoop.mapreduce.Cluster.initialize(Cluster.java:116)
at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:109)
at org.apache.hadoop.mapreduce.Cluster.<init>(Cluster.java:102)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1540)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1536)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapreduce.Job.connect(Job.java:1536)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1564)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)
at com.alex.FlowDriver.main(FlowDriver.java:45)
[ERROR] Command execution failed.
Command execution failed.
org.apache.commons.exec.ExecuteException: Process exited with an error: 1 (Exit value: 1)
at org.apache.commons.exec.DefaultExecutor.executeInternal (DefaultExecutor.java:404)
at org.apache.commons.exec.DefaultExecutor.execute (DefaultExecutor.java:166)
at org.codehaus.mojo.exec.ExecMojo.executeCommandLine (ExecMojo.java:982)
at org.codehaus.mojo.exec.ExecMojo.executeCommandLine (ExecMojo.java:929)
at org.codehaus.mojo.exec.ExecMojo.execute (ExecMojo.java:457)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo (DefaultBuildPluginManager.java:137)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:208)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:154)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute (MojoExecutor.java:146)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:117)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject (LifecycleModuleBuilder.java:81)
at org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder.build (SingleThreadedBuilder.java:56)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:128)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:305)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:954)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:288)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:192)
at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:498)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:289)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:229)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:415)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:356)
at org.codehaus.classworlds.Launcher.main (Launcher.java:47)
2. Reason: lack of jar package
Solution: import Hadoop MapReduce client common package
Adding dependencies using maven
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.3</version>
<scope>compile</scope>
</dependency>
[Solved] b”SQLSTATE[HY000] [2002] php_network_getaddresses: getaddrinfo failed:
What I encounter is that the value of host is wrong
Modification Evn configuration is good
The local address is the local address, and then it is solved
DB_HOST=localhost
Failed to parse multipart servlet request; nested exception is java.io.IOException: org.apache.tomcat.util.http.fileupload.FileUploadException: Stream closed
spring.mvc.hiddenmethod.filter.enabled=true
spring.servlet.multipart.max-file-size=500MB
spring.servlet.multipart.max-request-size=2048MB
[Solved] Failed to start app/proxyman/inbound: failed to listen TCP on 11057
Solution:
Run administrator cmd
netsh int ipv4 set dynamicport tcp start=30000 num=20000
Restart!
nginx: [error] CreateFile() “D:\nginx-1.20.1/logs/nginx.pid“ failed (2: The system cannot find the
nginx: [error] CreateFile() “D:\nginx-1.20.1/logs/nginx.pid“ failed (2: The system cannot find the
After downloading and decompressing nginx, double-click nginx Exe post access http://127.0.0.1/ , the welcome interface can appear
However, when the nginx service is closed on the command line (nginx – s quit), an error is reported: nginx: [error] createfile() “D: \ nginx-1.20.1/logs/nginx. PID” failed
According to the error message, nginx cannot be found in the logs file under the nginx installation directory PID file, check the corresponding file and find that there is no such file
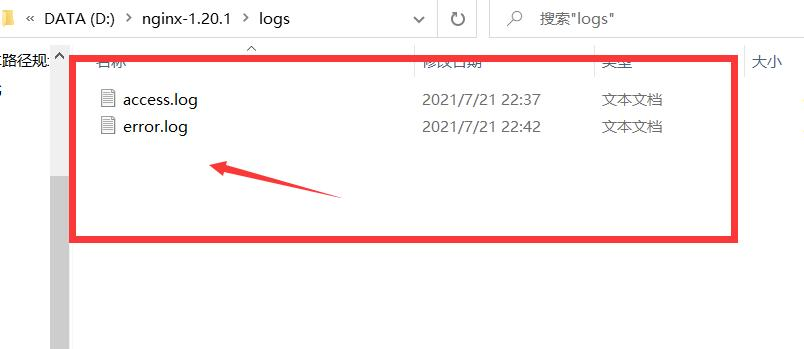
Solution:
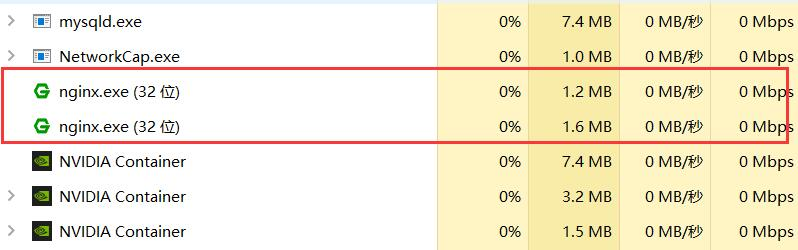
force the nginx process to close in the task manager,
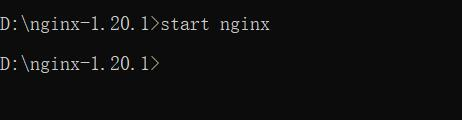
Then restart with the start nginx command on the command line,
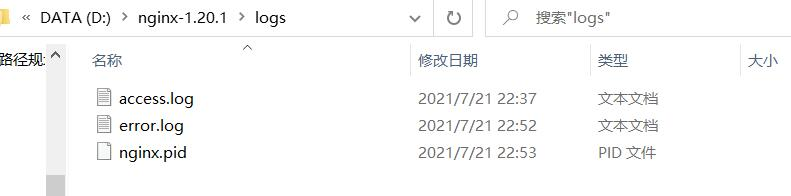
Now I find that nginx.com appears in the logs file under the nginx installation directory PID file,
Then use the command nginx – s quit to close the nginx process normally,
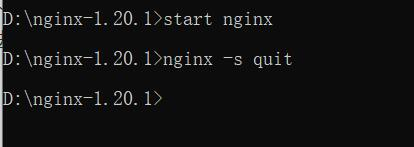
Cannot access at this time http://127.0.0.1/ , nginx was successfully closed
Cause analysis:
to kill the previous nginx process when nginx is started or restarted, you need to go through nginx PID to find the original process, and nginx PID stores the original process ID. Without the process ID, the system cannot find the original nginx process and cannot shut down naturally
After the test, either double-click nginx If nginx is started by exe or CMD command, nginx will be automatically configured under the logs file PID files can be closed normally. I don’t know why I can’t do it the first time
[Solved] linux configure: error: no acceptable C compiler found in $PATH
preface
When installing PgSQL on linux, execute /Configure -- prefix =/usr/local/PgSQL error, the same as the following:
[root@instance-0qymp8uo postgresql-14.1]# ./configure --prefix=/usr/local/pgsql
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking which template to use... linux
checking whether NLS is wanted... no
checking for default port number... 5432
checking for block size... 8kB
checking for segment size... 1GB
checking for WAL block size... 8kB
checking for gcc... no
checking for cc... no
configure: error: in `/root/postgresql-14.1':
configure: error: no acceptable C compiler found in $PATH
See `config.log' for more details
The reason for the error here is that we can’t find a suitable C compiler. We need to update GCC
./Configure is used to detect the target characteristics of your installation platform. This step is used to generate makefile to prepare for the next compilation. – prefix = is the specified software installation directory. You can set the configuration files of some software by specifying the – sys config = parameter. Some software can also add parameters such as – with, – enable , – without, – disable to control compilation. You can allow /Configure – help View detailed help instructions.
Solution:
Centos
yum install gcc
Ubuntu
apt-get install gcc