Premise:
After writing the project code in the local idea, package and upload the whole project to the cluster for testing
Note that the input and output paths should be written correctly

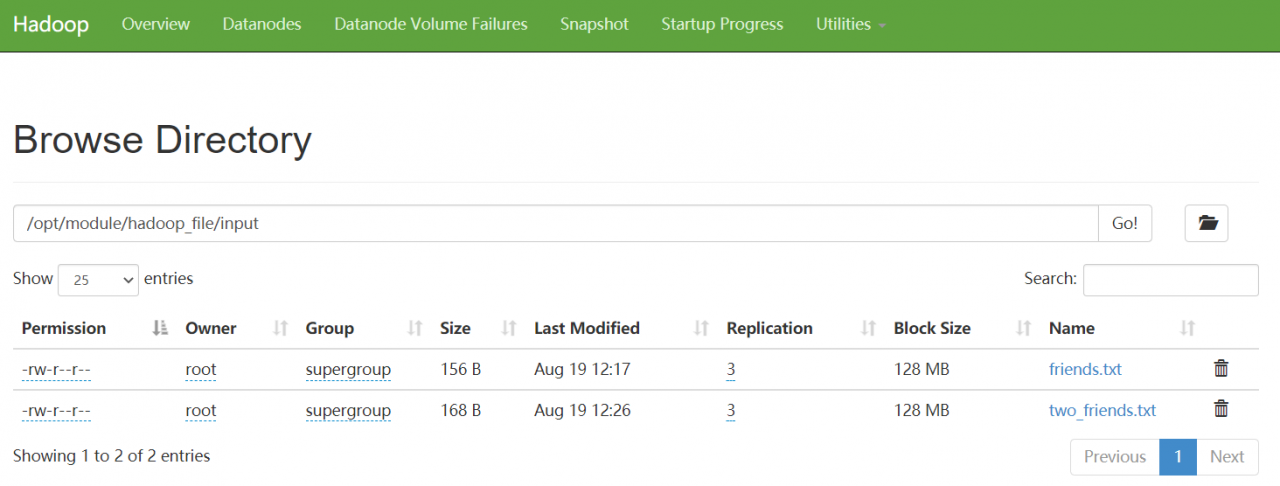
Upload the two files to the HDFS cluster
# Upload Files hadoop fs -put /opt/module/hadoop_file/input/friends.txt /opt/module/hadoop_file/input # Delete Files hadoop fs -rm -f /opt/module/hadoop_file/input/friends.txt # Delete Folder hadoop fs -rm -r /opt/module/hadoop_file/input
Start Mr program for jar package test
# Run MR Programmer hadoop jar friends.jar com.lxz.friends.OneShareFriendsDriver
Problems encountered:
1
Error Message:INFO mapreduce.Job: Task Id : attempt_1629344910248_0009_m_000000_0, Status : FAILED Error: java.io.IOException: Initialization of all the collectors failed. Error in last collector was :interface javax.xml.soap.Text
The reason is that in your idea project, you rely on importing javax.xml.soap.text. You should import org.apache.hadoop.io.text
2
Error Message:INFO mapreduce.Job: Task Id : attempt_1607842602362_0032_m_000000_2, Status : FAIL
The reason is that there are spaces in your input file. Carefully check the writing format of the input file
Summary: MR is still a time-consuming and laborious program. The advantage is that as long as you write the program code and adjust the number of mapper and reducer resources, it is only a matter of time for the data to run out. Error reporting is not terrible. You must remember to check the log information in the logs folder under the current directory of Hadoop installation
Similar Posts:
- An error is reported when sqoop imports data into MySQL database: error tool. Exporttool: error during export: export job failed!
- [Solved] Hadoop Error: Input path does not exist: hdfs://Master:9000/user/hadoop/input
- [Solved] wordcount Error: org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist:
- [Solved] Tez Compression codec com.hadoop.compression.lzo.LzoCodec not found.
- Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
- [Solved] Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses
- [Solved] Cannot initialize Cluster. Please check your configuration for mapreduce.framework.name and the correspond server addresses
- Mapreduce:Split metadata size exceeded 10000000
- The key technologies in hadoop-3.0.0 configuration yarn.nodemanager.aux -Services item
- Solution to the problem of unable to load native Hadoop Library in MAC development