Problem Description:
The scheduling system failed to execute hive task, and failed to execute all the time. The error reports are as follows:
java.io.ioexception: java.net.connectexception: call from #hostname/#ip to #hostname: 10020 failed on connection exception: java.net.connectexception: connection rejected; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
caused by: java.net.connectexception: call from #hostname/#ip to #hostname: 10020 failed on connection exception: java.net.connectexception: connection rejected; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
CONSOLE# Ended Job = job_ 1638255473937_ 0568 with exception 'java.io.ioexception (Java. Net. Connectexception: call from #hostname/#ip to #hostname: 10020 failed on connection exception: Java. Net. Connectexception: connection denied; for more details see: http://wiki.apache.org/hadoop/ConnectionRefused )
console # failed: execution error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.mapredtask. Java.net.connectexception: call from #hostname/#ip to #hostname: 10020 failed on connection exception: java.net.connectexception: connection rejected; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
You can’t see the specific problem from this information. You can’t see the problem by looking at all the logs on the server. Finally, you can see the problem by looking at yarn’s logs
According to the dispatching system, obtain applicationid: application_1638255473937_0568, and then view the corresponding log information from HDFS.
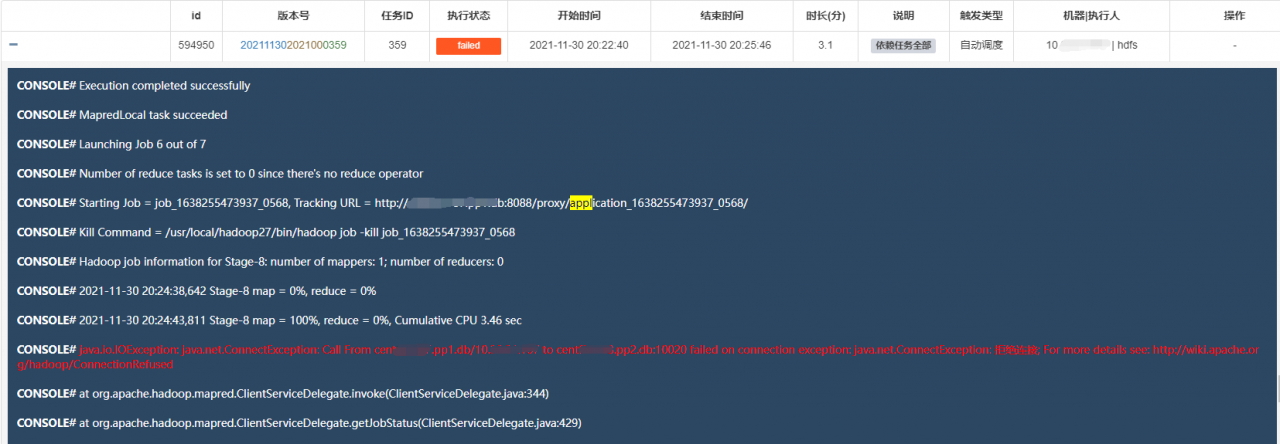
View yarn log information:
[ hdfs@centos hadoop27]$ yarn logs -applicationId application_1638255473937_0568
Key error reporting information:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.protocol.FSLimitException$MaxDirectoryItemsExceededException): The directory item limit of /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs is exceeded: limit=1048576 items=1048576

Error reporting reason:
There are more than 1048576 files in a single Hadoop directory. The default limit is 1048576, so you should increase the limit.
Solution 1:
Add the configuration parameter dfs.namenode.fs-limits.max-directory-items to the hdfs-site.xml configuration file, and increase the parameter value.

Push the configuration file to all nodes of the Hadoop cluster and restart the Hadoop service.
Solution 2:
If it is inconvenient to modify the configuration, restart the Hadoop cluster service. You can delete this directory first:/TMP/Hadoop yarn/staging/history/done_intermediate/hdfs
Then rebuild the directory.
hadoop fs -rm -r /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
hadoop fs -mkdir /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
The reason why the number of files in this directory exceeds the upper limit is that the Hadoop cluster did not start the jobhistory server before and did not clear the historical job log information
Extended information:
1: How to view the yarn log storage directory and log details
1: View through the history server UI interface. I’m here http://IP:8801/jobhistory )

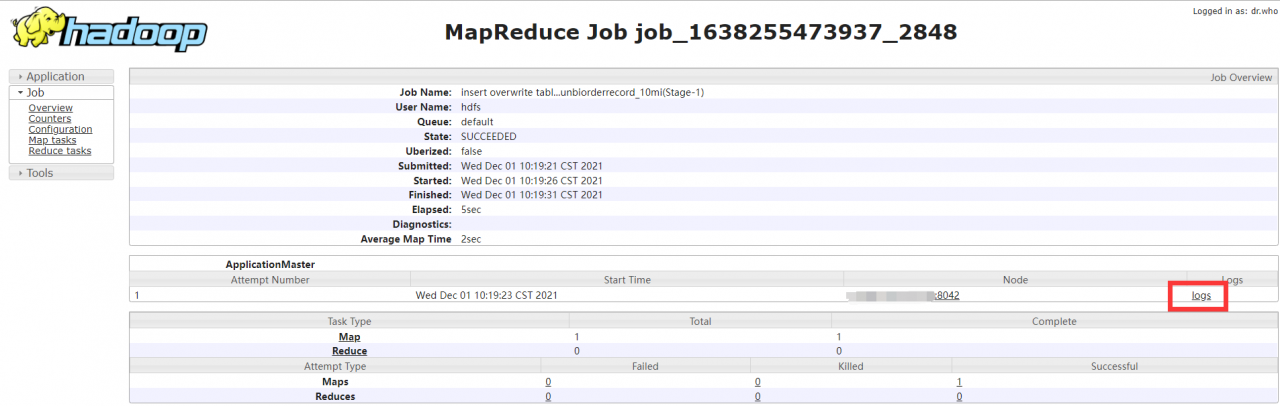
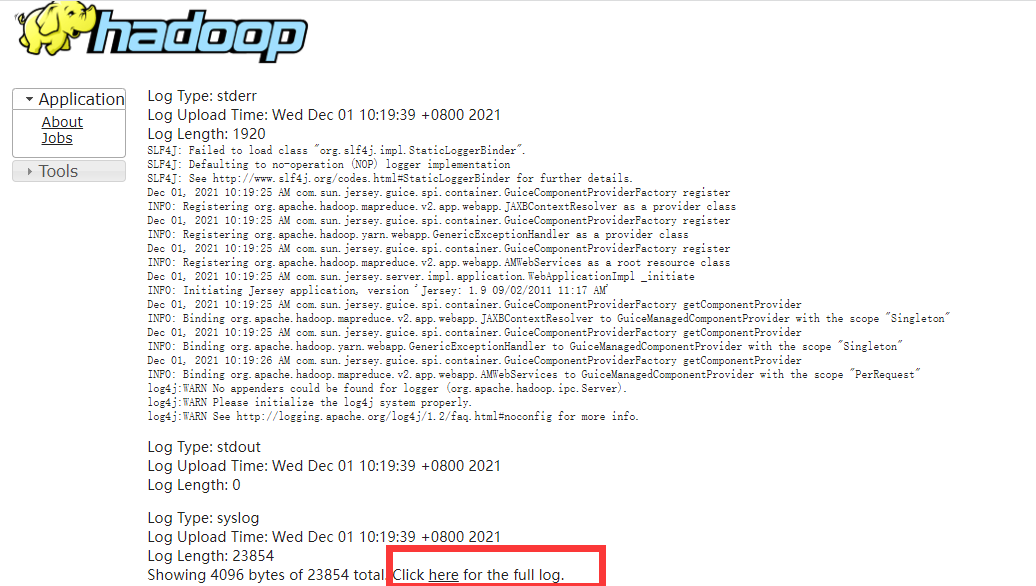
2: View through the yarn command (the user should be consistent with the user submitting the task)
2.1: yarn application – List – appstates all
2.2: yarn logs -applicationId application_1638255473937_0568
3: Directly view the log of the HDFS path (stored in the HDFS directory, not in the user-defined log directory of CentOS system)
3.1: check the yarn-site.xml file and confirm the log configuration directory.
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data1/hadoop27/logs</value>
</property>
3.2: view log file information
[hdfs@centos hadoop]$ hdfs dfs -ls /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568
Found 1 items
-rw-r----- 2 hdfs hdfs 66188 2021-11-30 20:24 /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568/centos.pp1.db_46654
3.3: view log details
3.3.1: yarn logs -applicationId application_1638255473937_0568 (same as 2)
3.3.2: HDFS DFS – Cat/data1/Hadoop 27/logs/HDFS/logs/application_1638255473937_0568/centos.pp1.db_46654 ## view through – Cat
3.3.3: HDFS DFS – Cat/data1/Hadoop 27/logs/HDFS/logs/application_1638255473937_0568/centos.pp1.db_46654 > tmp.log ## save the contents to tmp.log of the current directory through – cat.
3.3.4: HDFS DFS – get/data1/hadoop27/logs/HDFS/logs/application_1638255473937_0568/centos.pp1.db_46654 ## download the HDFS file to the current directory through get, and then view it.
2: HDFS operation command:
1.1: check the number of folders and files in the specified directory of HDFS.
[hdfs@centos hadoop]$ hadoop fs -count /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
1 1048576 3253261451467 /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
The first value of 1 indicates that there is 1 folder under this directory
The second value 1048576 indicates that there is a file in this directory
The third value 3253261451467 represents the total size of all files in the directory.
Similar Posts:
- [Solved] Exception in thread “main“ java.net.ConnectException: Call From
- [Solved] Call to localhost/127.0.0.1:9000 failed on connection exception:java.net.ConnectException
- Hive appears to refuse connection ConnectionRefused Solution
- Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
- IDEA Run mapreduce error: PATH Set Error [How to Solve]
- The key technologies in hadoop-3.0.0 configuration yarn.nodemanager.aux -Services item
- [Solved] hadoop Configuration Modify Error: hive.ql.metadata.HiveException
- [Solved] Hbase Exception: java.io.EOFException: Premature EOF: no length prefix available
- This server is in the failed servers list: localhost/127.0.0.1:16000 (Error starting hbase api call)
- [Solved] hadoop:hdfs.DFSClient: Exception in createBlockOutputStream