Individual articles are original or translated unless reprinted
Individual articles are welcome to be reprinted in various forms, but those over 18 years old are requested to indicate the source of the article, respect my labor and your intelligence
Link to this article: http://www.cnblogs.com/fbwfbi/p/4509622.html
N hasn’t started blogging for a long time. I always feel that I need to remember something casually. I’ve lost some things, technologies and tools. I’d better record every bit of them
In windows, PIP is used to install some third-party libraries of Python. Many of them use C to write some extensions and need to use VC + + compiler to compile and install (or use MinGW, generally not recommended). Otherwise, it will appear “ unable to find vcfarsall. Bat “. For example, python 2.7 needs to use VS2008 C + + compiler, while python3 to python3.4 (python3.5 will use vs2015) will use VS2010 to compile. However, anyone who has ever installed vs, a huge and bloated IDE, knows that it comes with a lot of Microsoft plug-ins that you don’t know whether they are useful or not. They occupy a lot of space on C disk and start slowly, although the interface function of IDE is barely passable. If the computer configuration is general, this thing will make n cards, generally do not do related development, there is no need to install the entire vs. For Python 2.7, Microsoft has a conscience. It directly launched Microsoft Visual C + + compiler for Python 2.7, which can be downloaded and installed directly. Then, in the start menu – “all programs”, find the corresponding directory, and according to your platform and python Version (select x86 or x64), click the corresponding command prompt to run. In this CMD window, you can enter the set command to check the environment variables. It is found that the parameters include =, path =, lib =, and libpath = have been set, so you can enter them directly
pip install numpy
You can install and compile the corresponding third-party modules and libraries. Sometimes the compilation process is long and you need to wait patiently
But for Python 3, it’s not so convenient. Because my Python 3.4 is 64 bit, it’s obviously impossible to use VS2010 express directly, because it only has x86 version by default, not 64 bit. Refer to a question and answer in stack overflow
Python PIP has issues with path for MS Visual Studio 2010 Express for 64-bit install on Windows 7
According to the above suggestions, I get the corresponding solution on this machine. First install VS2010 express, then install windows SDK 7.1, and finally install a 64 bit compiler patch
Microsoft SDK 7.1 (Windows 7)
VC-Compiler-KB2519277
PS: before installing SDK 7.1, please uninstall VC redistribute 2010 related component packages (including x86 and x64), otherwise an error will be reported
After completing the above steps, the basic MSVC compilation environment (including x64) has been configured. However, if you compile a project in the future, such as building a Qt5 project, the following errors will appear:
c:\program files (x86)\microsoft visual studio 10.0\vc\include\intrin.h(26):fatal error C1083: Cannot open include file: ‘ammintrin.h’: No such file or directory
At this time, you can download the corresponding ammintrin. H from the Internet, and put it in the directory of C:// program files (x86) \ \ Microsoft Visual Studio 10.0 \ \ VC \ \ include \, which can be downloaded from the following Baidu Library:
ammintrin. H header file, which is required after installing kb2519277 patch in Windows SDK 7.1
After installation, in the start menu, find “windows SDK 7.1 command prompt”, click Run, and set the corresponding compilation environment through setenv in the shell, as shown in the following figure:
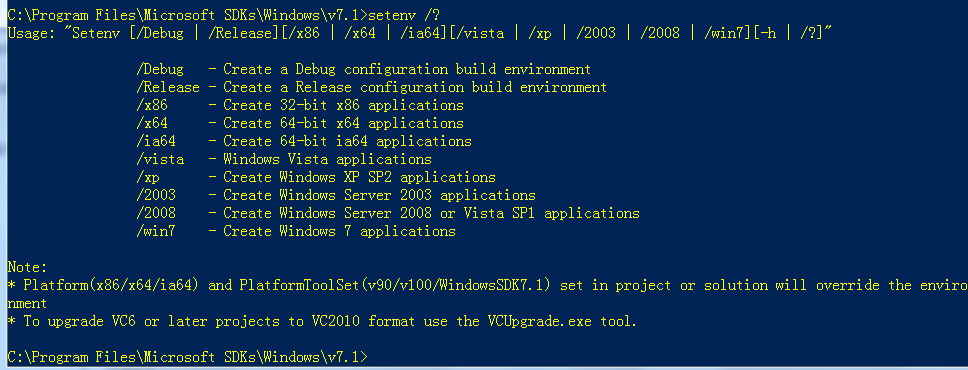
After setting “setenv/x64”, you can install the corresponding package in the 64 bit compiling environment
At this point, you may need to mention that after setting up the environment, you can install numpy in Python 2.7 and python 3.4 respectively. You find that py2 is OK, but PY3 fails to install and compile link (you have tested it in the virtual machine before, but PY3 installation is OK). Why?Please compare the following two pictures:
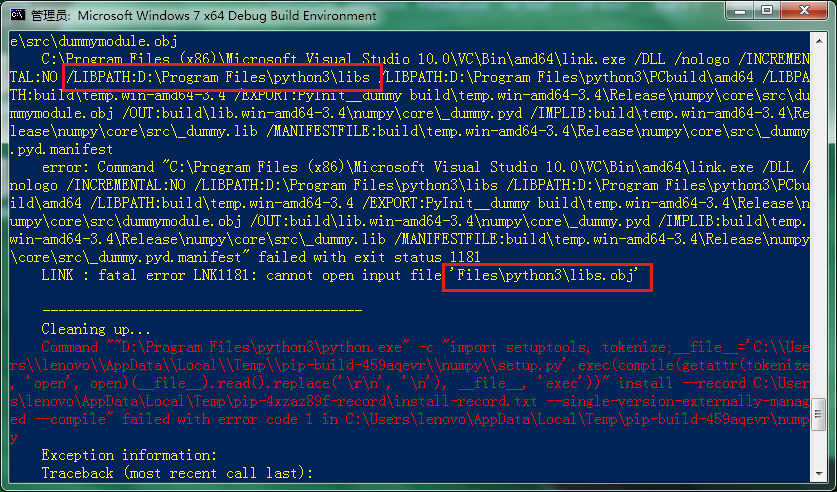
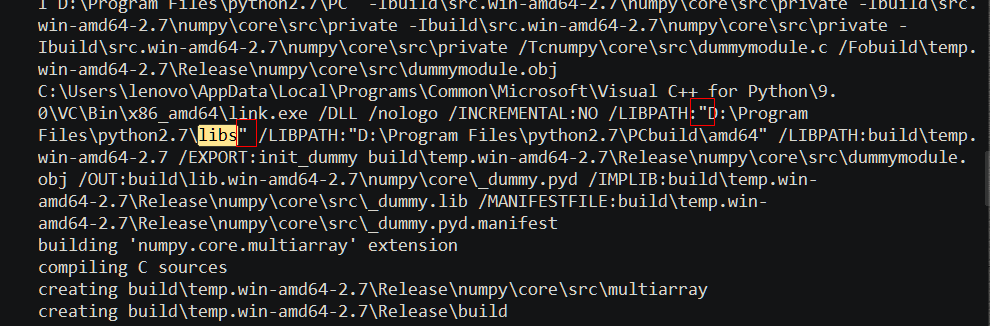
Obviously, when py2 is installed, libpath under the link command line uses “” to cause it. Therefore, the path with spaces will not partition the parameters. PY3 is not so detailed. I don’t know whether it is the fault of PIP and setuptools calling the CMD command or the bug in distutils. Anyway, the installation path of PY3 can’t have spaces. So I adjusted the installation path of python3, that is, there is no space, and the compilation is successful
Of course, this is just a VC + + compilation environment. For a numerical calculation library like SciPy, you need a FORTRAN compiler to install it. Obviously, the compilation and installation under windows is far less convenient than that under Linux (except that the package name is not easy to remember and the package dependence is troublesome). GCC and gfortran are ready-made, and apt get is also ready-made. Therefore, if you develop and test under windows, you can directly use a large number of compiled and packaged windows wheel installation packages provided by the University of California, Irvine (UCI), which contain numpy, SciPy, Matplotlib and other module libraries for numerical analysis and scientific calculation, and all of them are MKL versions. Download the corresponding version and directly use “PIP install XXX. WHL” to complete the installation. The WHL file is just like a zip file. You can also use the compression software to unpack it and put it in the corresponding lib/site packages directory. Of course, you can also use the python customized environment version Anaconda , which has directly integrated the above packages, including the easy-to-use repl tool like IPython and CONDA package management