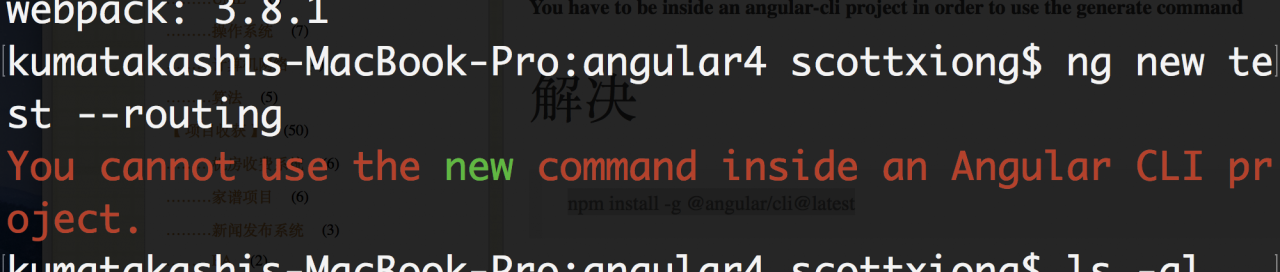
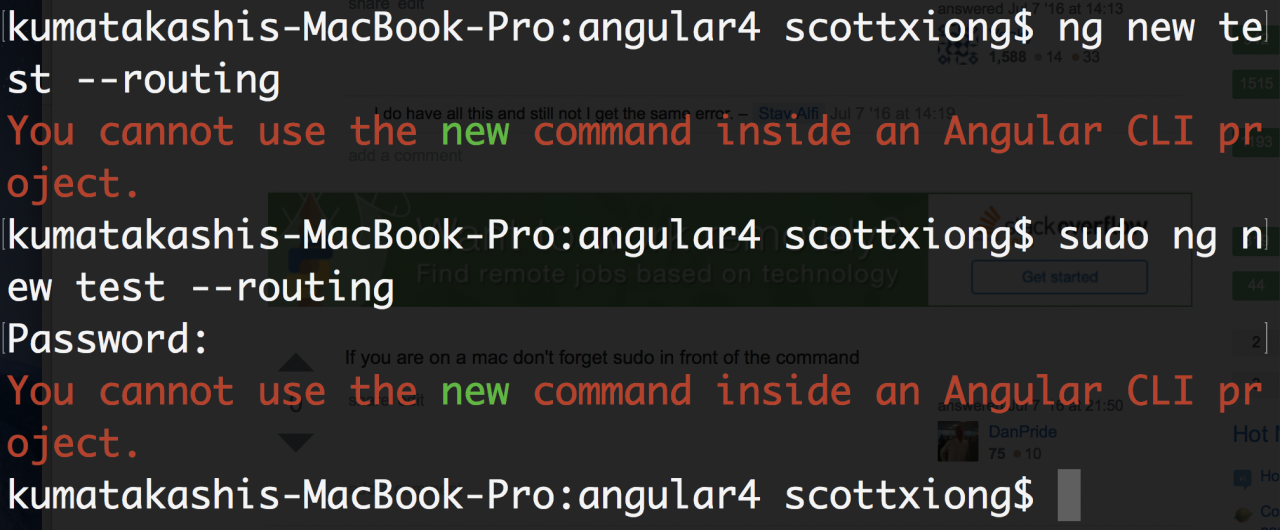
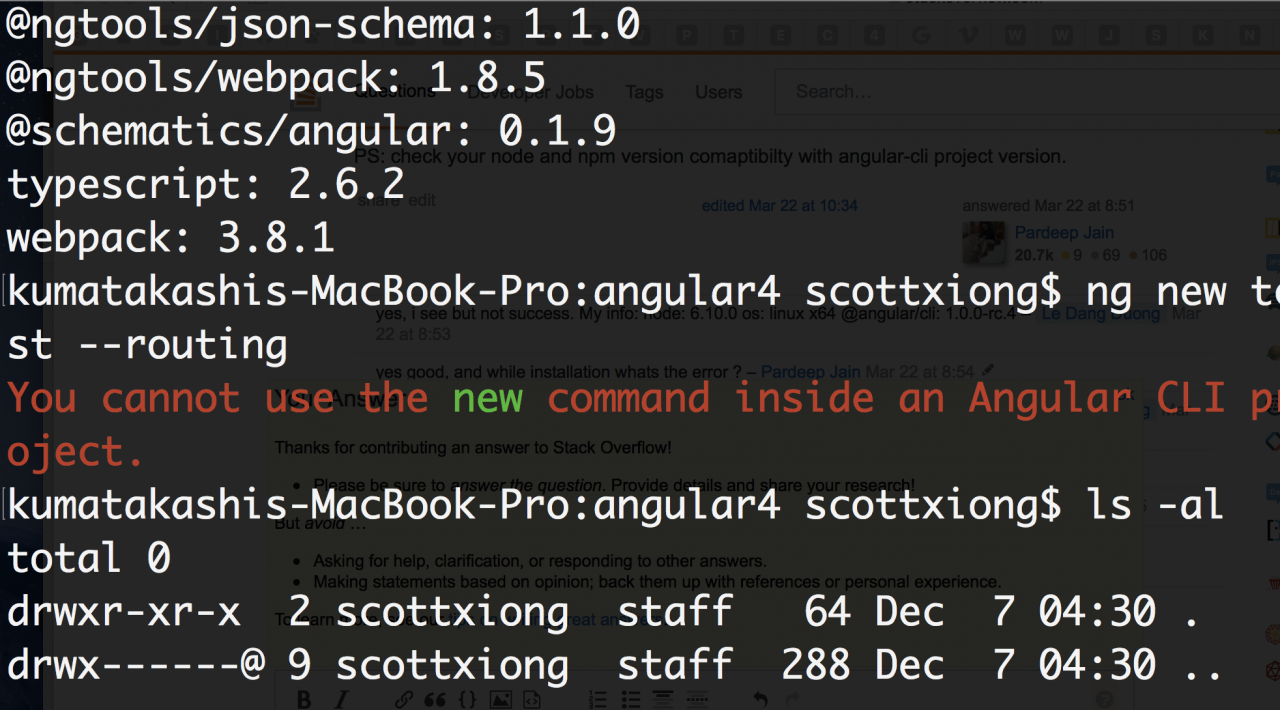
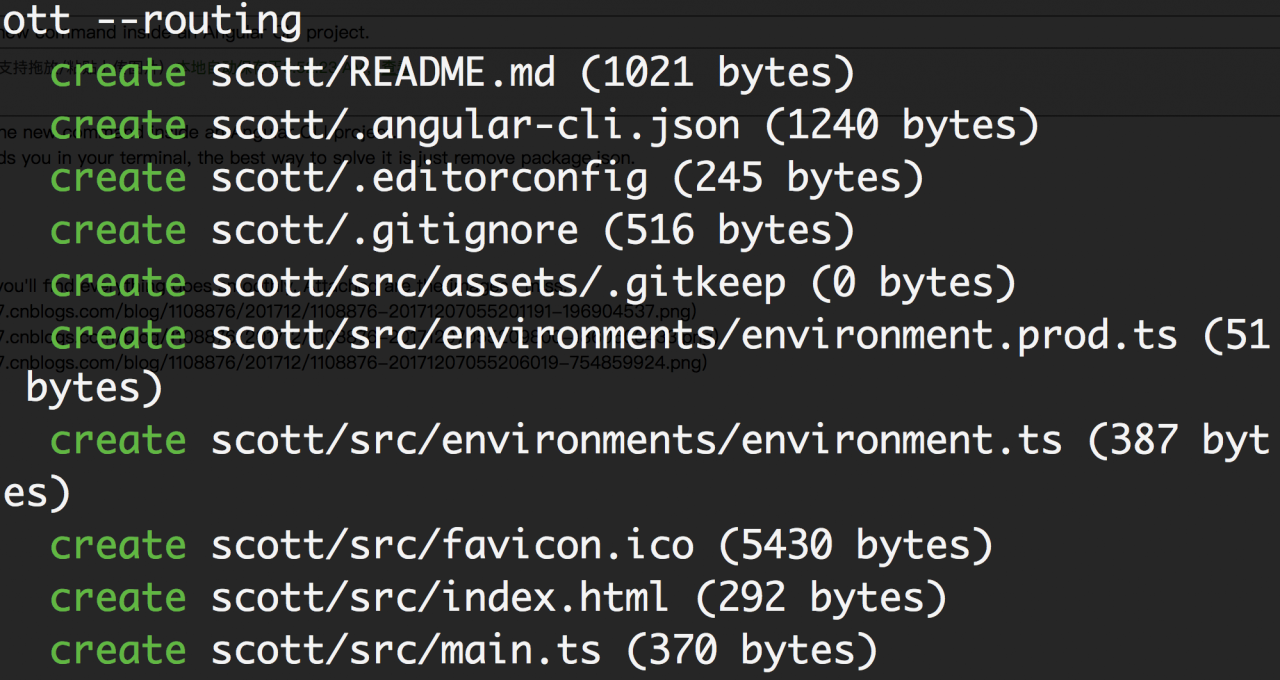
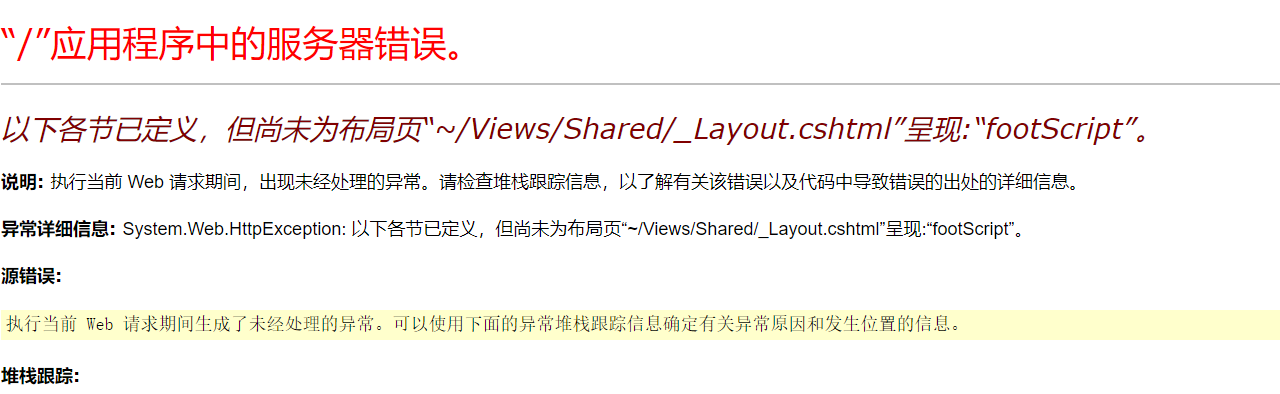
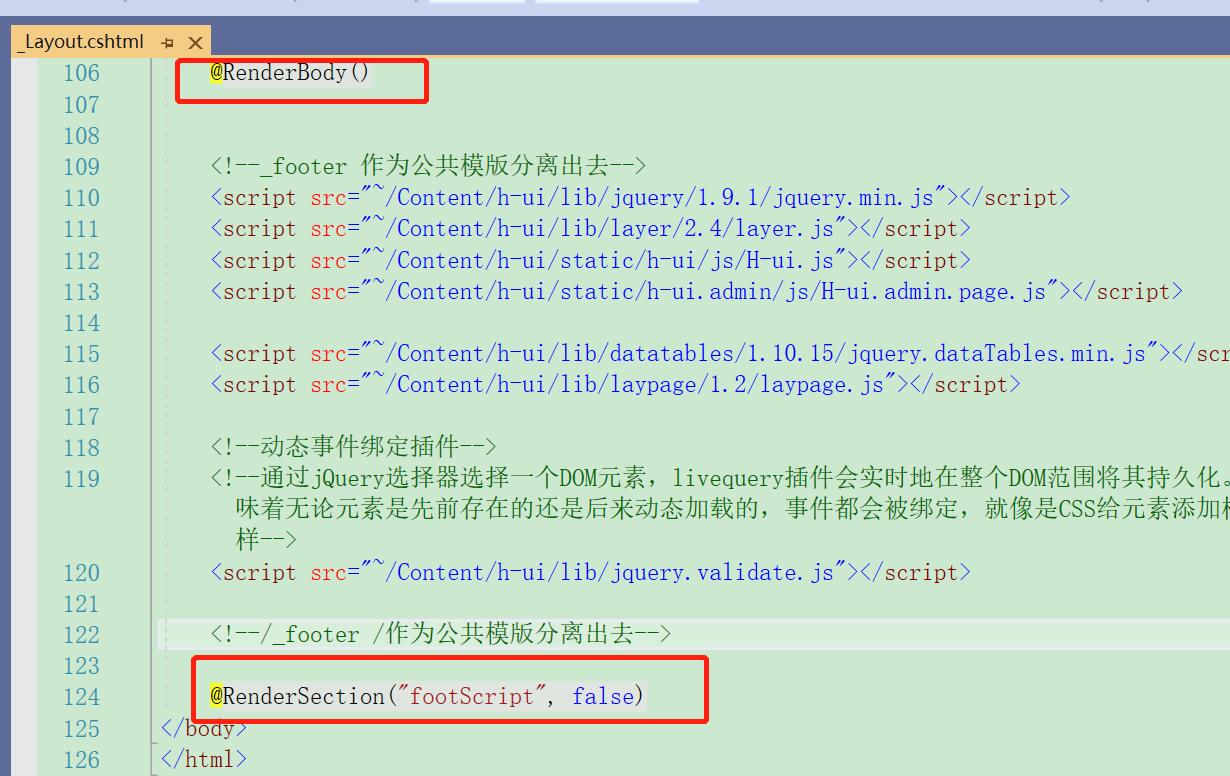
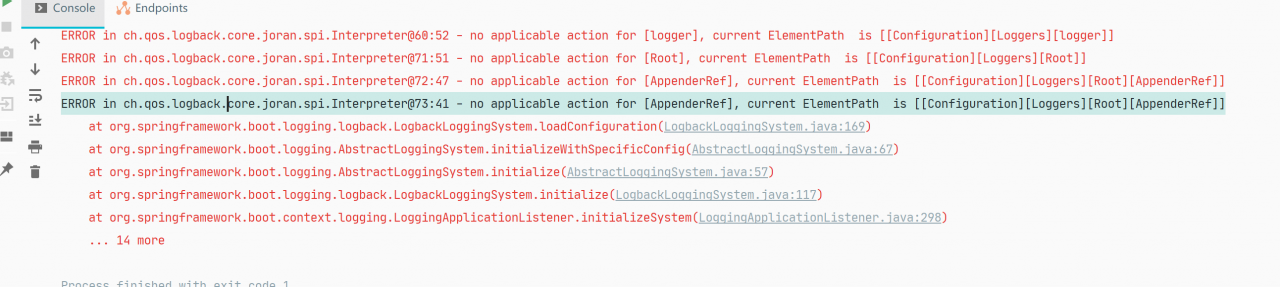
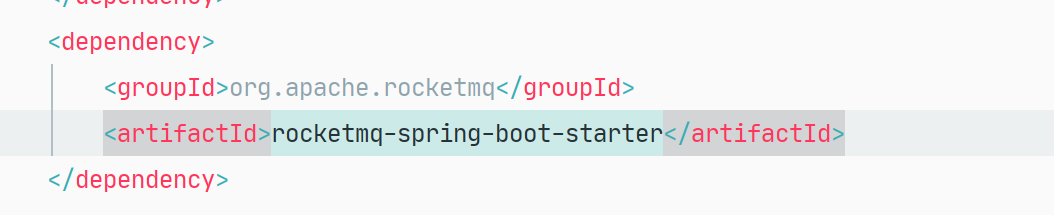
Error Messages:
Access to XMLHttpRequest at ‘http://www.localtest.com/api/api/v1/job/getPositionList’ from origin ‘http://localhost:8080’ has been blocked by CORS policy: Request header field os-version is not allowed by Access-Control-Allow-Headers in preflight response.
Original request interface
http://www.localtest.com/api/api/v1/job/getPositionList
Solution:
Configure cross-domain in the manifest.json file, the method is similar to devServer in vue.config.js

"h5" : {
"devServer" : {
"disableHostCheck" : true, // Enable you to use your own domain name
"proxy": {
"/api": {
"target": "http://www.localtest.com",
"changeOrigin" : true,
"secure" : false,
"pathRewrite": { //api in the matching request path will be replaced with https: // www.test.com
// Example: /api/api/user => https://www.localtest.com/api/user
"^/api": ""
}
}
}
}
}
in addition
baseUrl = process.env.NODE_ENV === 'development' ?'/api' : 'https://www.localtest.com' Then the url requested by uni.request should be like this: baseUrl + '/user/info' then The request address seen by the browser should be http: http://localhost:8080/user/info