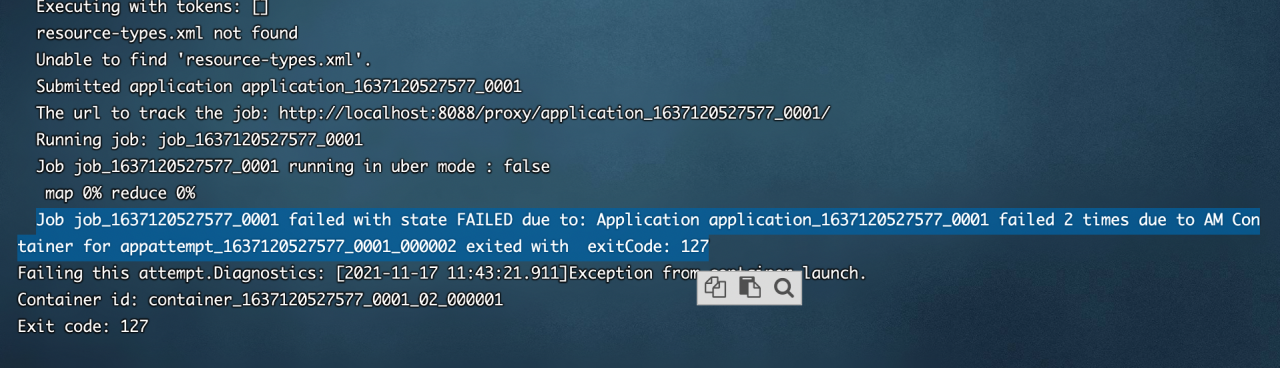
nginx: [error] CreateFile() “D:\nginx-1.20.1/logs/nginx.pid“ failed (2: The system cannot find the
After downloading and decompressing nginx, double-click nginx Exe post access http://127.0.0.1/ , the welcome interface can appear
However, when the nginx service is closed on the command line (nginx – s quit), an error is reported: nginx: [error] createfile() “D: \ nginx-1.20.1/logs/nginx. PID” failed
According to the error message, nginx cannot be found in the logs file under the nginx installation directory PID file, check the corresponding file and find that there is no such file
Solution:
force the nginx process to close in the task manager,
Then restart with the start nginx command on the command line,
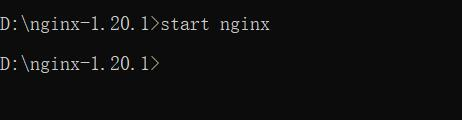
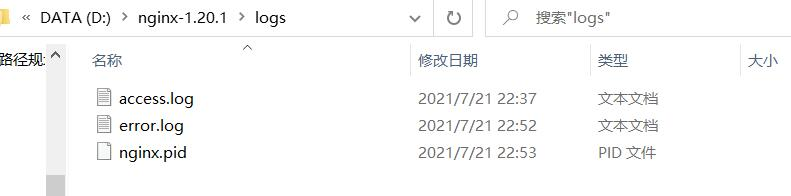
Now I find that nginx.com appears in the logs file under the nginx installation directory PID file,
Then use the command nginx – s quit to close the nginx process normally,
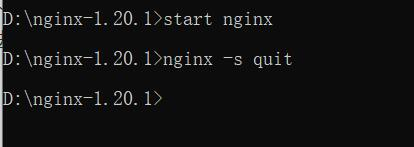
Cannot access at this time http://127.0.0.1/ , nginx was successfully closed
Cause analysis:
to kill the previous nginx process when nginx is started or restarted, you need to go through nginx PID to find the original process, and nginx PID stores the original process ID. Without the process ID, the system cannot find the original nginx process and cannot shut down naturally
After the test, either double-click nginx If nginx is started by exe or CMD command, nginx will be automatically configured under the logs file PID files can be closed normally. I don’t know why I can’t do it the first time