An error is reported when running Vue project (NPM run DEV)
Errors are reported as follows
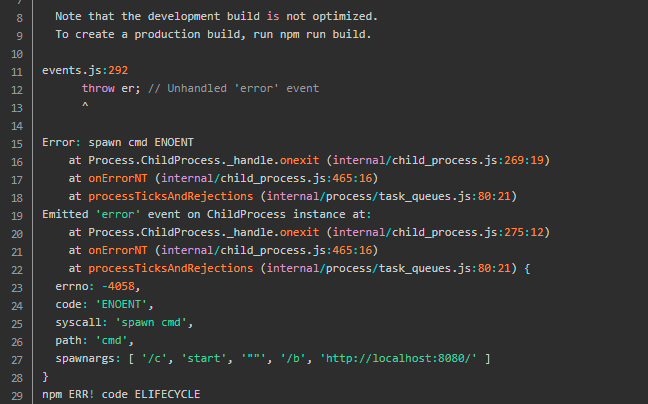
Cause of problem
Missing environment variable for CMD runtime
Solution:
Add C:\windows\system32 to the environment variable path
An error is reported when running Vue project (NPM run DEV)
Errors are reported as follows
Cause of problem
Missing environment variable for CMD runtime
Solution:
Add C:\windows\system32 to the environment variable path
![]()
Then Google checked and found that it was the problem with the version, and then reduced the version from 4.13 2 to 4.12 still can’t
Check Google again to change to version 4.10, or import hamcrest-core-1.3 jar
The official website says:
Includes the Hamcrest classes. The simple all-in-one solution to get started quickly. Starting with version 4.11, Hamcrest is no longer included in this jar.
So the solution is:
1. JUnit reduced version 4.10
2. Import hamcrest-core-1.3 jar
When querying data using springboot + mybati plus, an error occurs springgboot unknown column 'field name' in 'field list'
Baidu hasn’t found a solution for a long time. Finally, it found that there was a problem with the setting of database field name
When the database configuration is correct and automatic map mapping is enabled, an error is still reported.
After checking for a long time, I finally found that there was a problem with the setting of the database field name
For example, the field name of my database is LastName. If the variable name in the JavaBean is LastName, an error will be reported.
Changing the database field name to underline or non hump name successfully solves the problem
Recently, I was writing a search interface service. After writing the interface, I conducted a stress test. However, when testing with a high thread for a long time, the following errors will be reported:
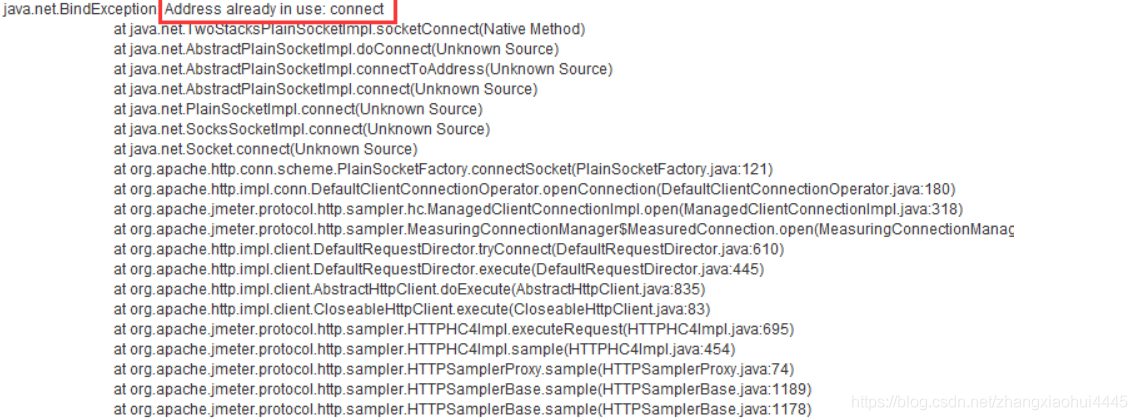
Troubleshooting:
First, check the server log and find that there are no errors.
Then check the nginx data. It is found that the number of requests is inconsistent with the number of requests sent by the test. The server receives less and thinks of losing requests.
Later, after searching the information, it was found that it was the problem of the windows machine,
Reason: Windows provides 1024-5000 ports for TCP/IP links, and it takes four minutes to recycle them, which causes us to fill up the ports when running a large number of requests in a short time, resulting in an error report.
Solution (operate on the server where JMeter is located):
1. Enter regedit command in CMD to open the registry;
2. In HKEY_LOCAL_Machine\system\currentcontrolset\services\TCPIP\parameters right-click parameters;
3. Add a new DWORD named maxuserport;
4. Double click maxuserport, enter 65534 numerical data, and select decimal base;
5. After completing the above operations, be sure to restart the machine and solve the problem.
No error will be reported for the test results after solution:

Add: I can test normally after modifying the above problems, but the same problem occurs after increasing the number of threads two days. The following configuration will test normally.
After the above three steps, add tcptimedwaitdelay, the value is 30-300, and select decimal.
You still need to restart your computer
When packaging Maven war package project for springboot project in idea, you will be prompted:
Error assembling WAR: webxml attribute is required (or pre-existing WEB-INF/web.xml if executing in update mode)
The reason is that it will find the web XML file, which is deleted by default for springboot projects.
The solution is to add a plug-in in POM to package:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>3.2.0</version>
</plugin>
Once added, you can package.
#include <iostream>
#include <uuid/uuid.h>
#include <time.h>
#include <unistd.h>
#include <fstream>
#include <istream>
#include <ostream>
#include <sstream>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
readFile8();
return 0;
}
void readFile8()
{
FILE *fp=fopen("log2.txt","r");
if(!fp)
{
printf("Create or open log2.txt failed!\n");
}
char *uuidValue=(char*)malloc(40);
size_t len=40;
int num=0;
while((getline(&uuidValue,&len,fp))!=-1)
{
printf("Num=%d,value=%s\n",num++,uuidValue);
}
fclose(fp);
free(uuidValue);
printf("Finished!\n\n");
}
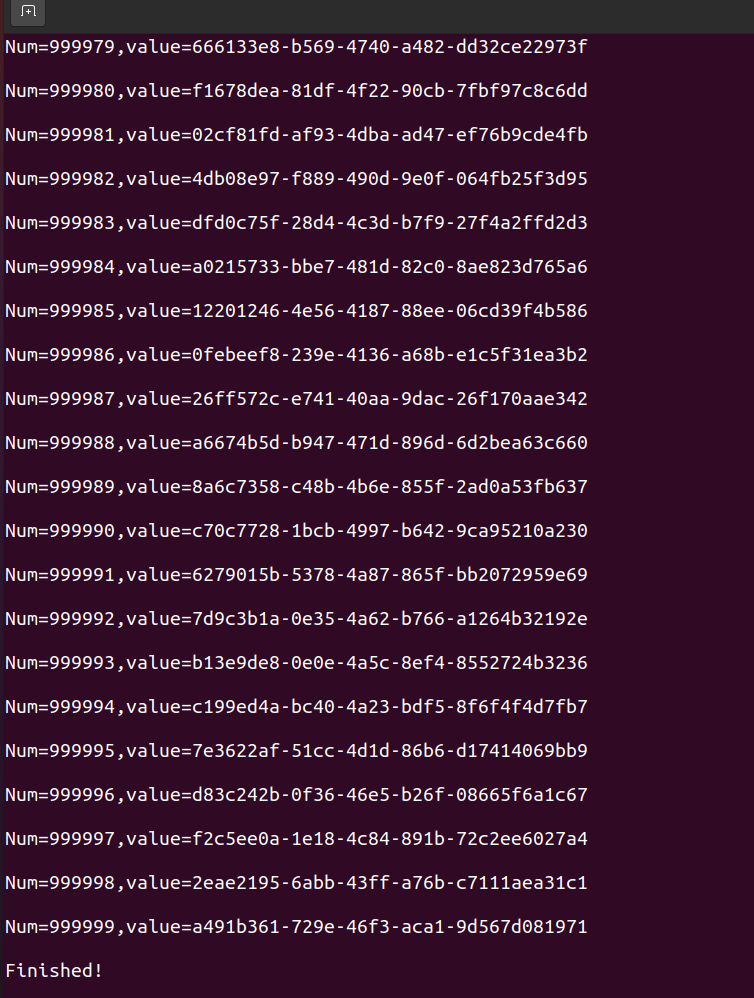
void writeFile7()
The effect as below snapshot.
NetBackup Accelerator backup fails STATUS 84
Problem
The NetBackup Accelerator feature enables the ability for repeated Full backups but with the performance as good as an Incremental backup.
Additionally Accelerator backups with an incremental type schedule can be defined as Incremental backups which will run quicker and not create a full catalog reference in the NetBackup images database. The Accelerator feature relies on the Deduplication storage such as the Media Server Deduplication Pool (MSDP) to have the ability of storing only the data which has changed since the previous Accelerator backup.
There are numerous reasons why a backup will fail with STATUS 84 (media write error), however, this technical article addresses one specific problem when the job details state “get frag failed, backup id”.
Error Message
Job Details:
29.jan.2021 02:48:17 - Info ndmpagent (pid=50203) <CLIENTNAME>: DUMP: Fri Jan 29 02:48:18 2021 : We have written 1880787110 KB.
29.jan.2021 02:53:17 - Info ndmpagent (pid=50203) <CLIENTNAME>: DUMP: Fri Jan 29 02:53:18 2021 : We have written 1914286917 KB.
29.jan.2021 02:58:18 - Info ndmpagent (pid=50203) <CLIENTNAME>: DUMP: Fri Jan 29 02:58:18 2021 : We have written 1949038217 KB.
29.jan.2021 03:01:12 - end writing; write time: 6:39:23
29.jan.2021 03:02:43 - Critical bptm (pid=50205) get frag failed, backup id (<CLIENTNAME>_1603821638)
29.jan.2021 03:02:43 - Critical bptm (pid=50205) image write failed: error 227: Not an OST error code
29.jan.2021 03:02:52 - Error bptm (pid=50205) cannot write image to disk, Invalid argument
29.jan.2021 03:02:52 - Info ndmpagent (pid=50203) Received ABORT request from bptm
29.jan.2021 03:02:52 - Error ndmpagent (pid=50203) NDMP backup failed, path = /<VOLUME_NAME>/<SUB_DIRECTORY>/
29.jan.2021 03:02:52 - Error ndmpagent (pid=50203) <CLIENTNAME>: DUMP: Error: Write to socket failed
29.jan.2021 03:02:53 - Error ndmpagent (pid=50203) <CLIENTNAME>: DUMP: Error: DUMP IS ABORTED
29.jan.2021 03:02:53 - Info ndmpagent (pid=50203) <CLIENTNAME>: DUMP: Deleting "/<VOLUME_NAME>/<SUB_DIRECTORY>/../snapshot_for_backup.2518" snapshot.
29.jan.2021 03:02:53 - Error ndmpagent (pid=50203) <CLIENTNAME>: DATA: Operation terminated (for /<VOLUME_NAME>/<SUB_DIRECTORY>/).
29.jan.2021 03:02:54 - Info bptm (pid=50205) EXITING with status 84 <----------
BPTM log – demonstrating the backup ID “<CLIENTNAME>_1603821638” could NOT be located in the MSDP catalog, which is what references the backup images held on the MSDP storage:
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_open_image: entry: 0x9 R, img_basename=<CLIENTNAME>_1603821638_C1_F1
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: acquire_svh: svh:<0x13633d0>, nhandle:<22>
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_image_handle: entry: 2 8 m=(R) (PureDiskVolume) (<CLIENTNAME>_1603821638_C1_F1)
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: acquire_svh: svh:<0x13633d0>, nhandle:<23>
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_image_handle: copy=1, frag=1
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: entry: imh(0x0x5ae0c550) imgdef(0x0x7ffec41c8620)
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: imh->imh_infopath(/svvpmediasrv52#1/2/<CLIENTNAME>/<POLICY_NAME>/<CLIENTNAME>_1603821638_C1_F1.info)
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: imh->imh_imgpath(/svvpmediasrv52#1/2/<CLIENTNAME>/<POLICY_NAME>/<CLIENTNAME>_1603821638_C1_F1.img)
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: imh->imh_hdrpath(/svvpmediasrv52#1/2/<CLIENTNAME>/<POLICY_NAME>/<CLIENTNAME>_1603821638_C1_F1.hdr)
03:02:43.794 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: imh->imh_mappath(/svvpmediasrv52#1/2/<CLIENTNAME>/<POLICY_NAME>/<CLIENTNAME>_1603821638_C1_F1.map)
03:02:43.795 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: image <CLIENTNAME>_1603821638_C1_F1 not found
03:02:43.795 [50205] <2> 41124714:bptm:50205:svvpmediasrv52: [DEBUG] PDSTS: impl_get_imh_image_prop: exit (2060018:file not found)
Cause
Accelerator backups have a dependency on the all previous backups leading back to the last successful Full. If the option of performing Accelerator Incremental backups is used, these backups must be maintained (long enough retention period) going back to the last successful Full, because if any expire or are lost before the next Full is attempted, then a failure will occur.
If any *previous* Incremental backup going back to the last successful Full is missing from the catalog and/or storage, then the next Accelerator (Full or Incremental) backup will fail. The details for the previous backups are held in the track logs and the NetBackup images, which have the reference of the one previous backup image, therefore, if the chain is broken the failures will occur.
Solution
The solution is to perform a new baseline Full backup for the specific client/policy. This can be achieved by running an Accelerator Forced Rescan backup, however, to really start over, it is recommended to *remove* the existing track logs and then perform the Full Accelerator backup.
Track log locations:
Master server (NDMP Accelerator backups):
UNIX: /usr/openv/netbackup/db/track
Windows: install_path\NetBackup\db\track\
Media server(NDMP Accelerator backups):
UNIX: /usr/openv/netbackup/track
Windows: install_path\NetBackup\track\
Client (Accelerator backups which are NOT NDMP):
UNIX: /usr/openv/netbackup/track
Windows: install_path\Veritas\NetBackup\track\
Note: Under these directories, there will be a number of directories created that correspond to the master server name, storage server name, policy name, client name, and backup selections, therefore, only remove track logs related to the specific Accelerator backup needing attention.
Edit the in the user directory (usually Disk C) gradle/gradle.Properties file, comment out the proxy address and interface
My directory is C:\users\solida1y\gradle\gradle.properties
#systemProp.https.proxyHost=127.0.0.1
#systemProp.https.proxyPort=1080
Problem Description: a control file is generated from the primary database to the standby database for recovery. The primary database is a set of Rac environment, but the generation to the file system fails
SQL> alter database create standby controlfile as '/home/oracle/racdg1.ctl';
ORA-00245: control file backup failed; target is likely on a local file system
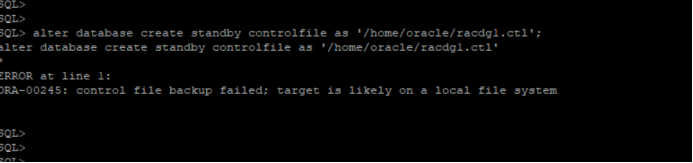
To view the RMAN settings of the main library, you can see that the snapshot control file is set on the file system
RMAN> show all;
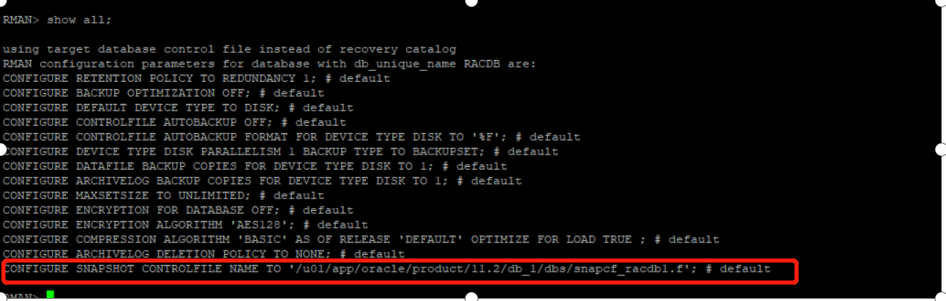

Adjust snapshot backup policy
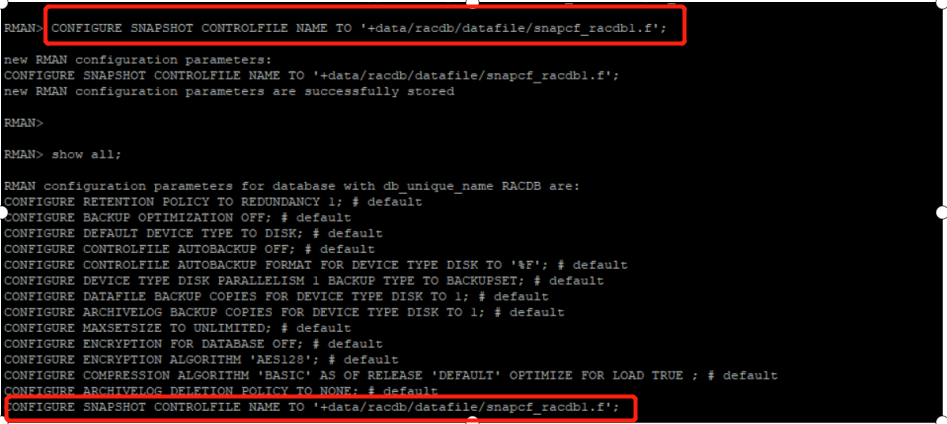
Regenerate standby successfully
