The salve replication thread stops, and an error 1872 is reported when trying to start slave
mysql> system perror 1872
MySQL error code 1872 (ER_SLAVE_RLI_INIT_REPOSITORY): Slave failed to initialize relay log info structure from the repositorySolution process
1. It seems that the warehouse of relay log cannot be found, but the location of relay log is set
mysql> show variables like 'relay%';
+---------------------------+---------------------------------------------------+
| Variable_name | Value |
+---------------------------+---------------------------------------------------+
| relay_log | relay-log |
| relay_log_basename | /datadir/relay-log |
| relay_log_index | /datadir/relay-log.index |
| relay_log_info_file | relay-log.info2. Log related information is also recorded in master.infor, and no exception is found after viewing
3. Reset the replication information
mysql> reset master;
Query OK, 0 rows affected (0.00 sec)
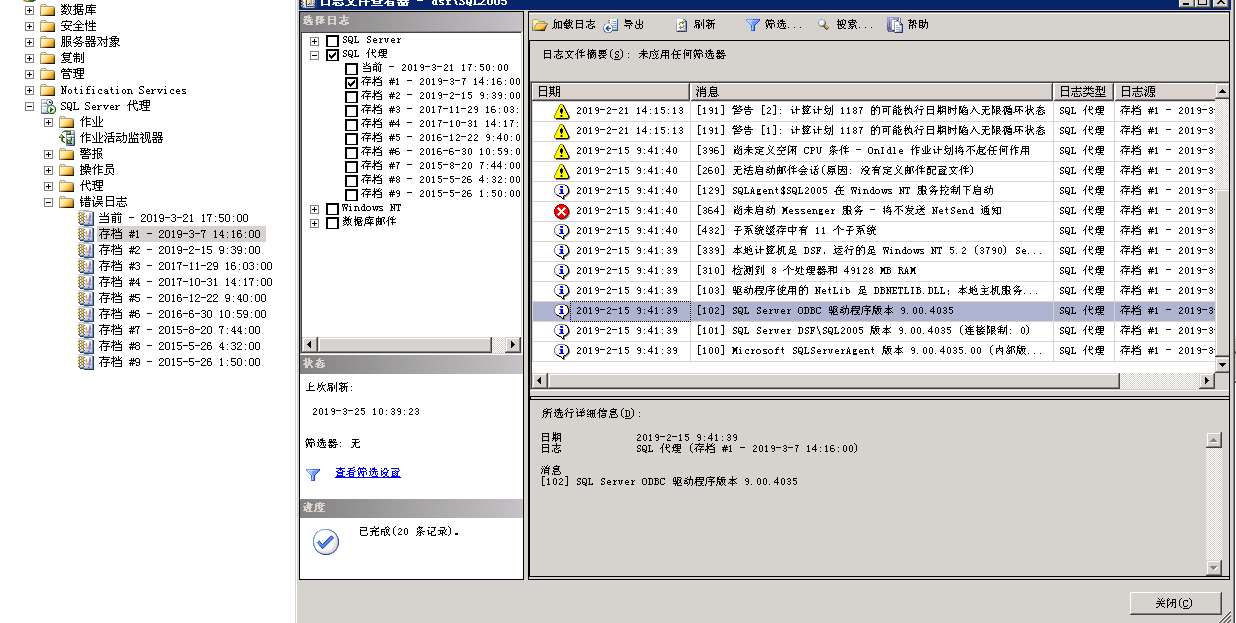
mysql> show slave status\G
**************************\* 1. row ***************************
Slave_IO_State:
Master_Host: *******
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: relay-log.000001
Relay_Log_Pos: 4Note: There is still a copy message
After that, proceed to
set global gtid_purged=’*******’;
change master to …… ;
The error is still reported when starting the slave
4. MySQL DOC description of start slave:
RESET SLAVE does not change any replication connection parameters such as master host, master port, master user, or master password, which are retained in memory. This means that START SLAVE can be issued without requiring a CHANGE MASTER TO statement following RESET SLAVE.
Connection parameters are reset by RESET SLAVE ALL.
5. Use reset slave all to clear all replication information, then reset gtid_purged and master.infor
After start slave, replication is normal