0. Preface
In the ipython environment, matlotlib library is needed. When running the .py file, the following error is displayed:
No module named _tkinter, please install the python-tk package.
The configuration environment is ubuntu16.04. The purpose of this article is to solve the above problems.
1. Tkinter problem description
According to ordinary thinking, the reason for the above error may be that the python environment lacks tk packages from time to time, so enter the command: sudo apt-get install python-tk
But it also prompted an error: tcl8.6.8, tk8.6.8 not found.
Google it, tcl is the abbreviation of “Tool Command Language”, and its object-oriented language is otcl. Tk is an extension of Tcl “graphic toolbox”, which provides various standard GUI interface items to facilitate the rapid development of advanced applications.
2. Install tcl and tk
Follow the instructions in 1 to download tcl and tk: http://www.tcl.tk/software/tcltk/download.html . The latest version at this time is 8.6.8.
(1) Install tcl, execute the following commands in sequence:
tar -zvxf tar -xzvf tcl8.6.8-src.tar.gz
cd tcl8.6.1/unix
./configure
make
sudo install make
(2) Follow the law and install tk8.6.8:
tar -xzvf tk8.6.8-src.tar.gz
cd tk8.6.8/unix
./configure
make
sudo install make
But an error is prompted when the make command is executed: there is no file or directory for X11/Xlib., see the figure below.
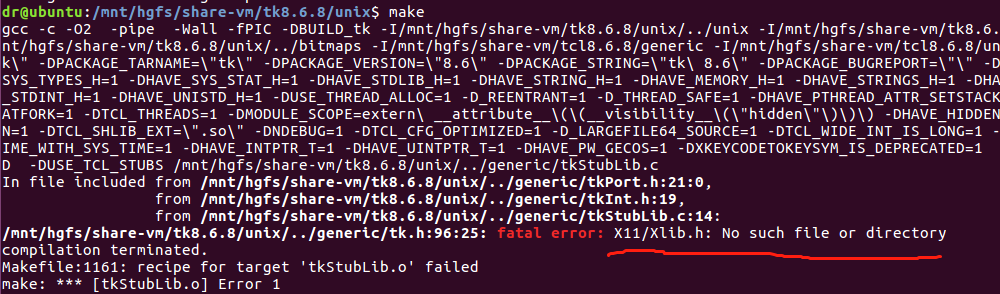
3. Search for the X11/Xlib.h file
According to the prompt in the above figure, the X11/Xlib.h file is missing, so execute the command:
sudo apt-get install libx11-dev
The following prompt appears:

The prompt message is: The package libx11-dev may be missing.
4. Replace the source (source)
According to the picture, search for libx11-dev and see if there is this libx11-dev package in the system:
apt-cache search Xlib
But the Xlib file cannot be found at all:
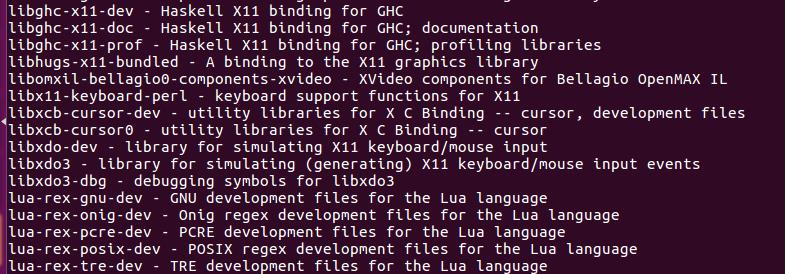
Dramatically discovered that the source of Jack Ma’s house does not have the libx11-dev package at all! ! ! So change the source of Tsinghua University. Please find the specific method of changing the source on the Internet. I will not go into details here.
5. Find the package of libx11-dev
After changing the source, use the command again: apt-cache search Xlib
Finally found libx11-dev.
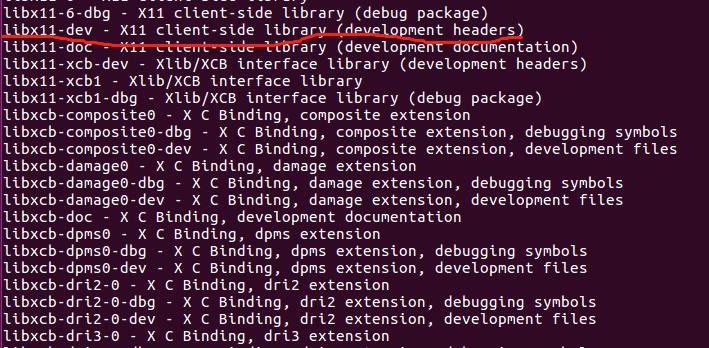
6. Reinstall tk8.6.8
After taking such a big circle, go back to the problem of installing tk8.6.8 in 2 and reinstall tk8.6.8:
tar -xzvf tk8.6.8-src.tar.gz
cd tk8.6.8/unix
./configure
make
sudo install make
7. Finally install Tkinter
Install the Tkinter package again: sudo apt-get install python-tk
This time there is finally no error prompt.
Run the following .py file in the Ipython environment
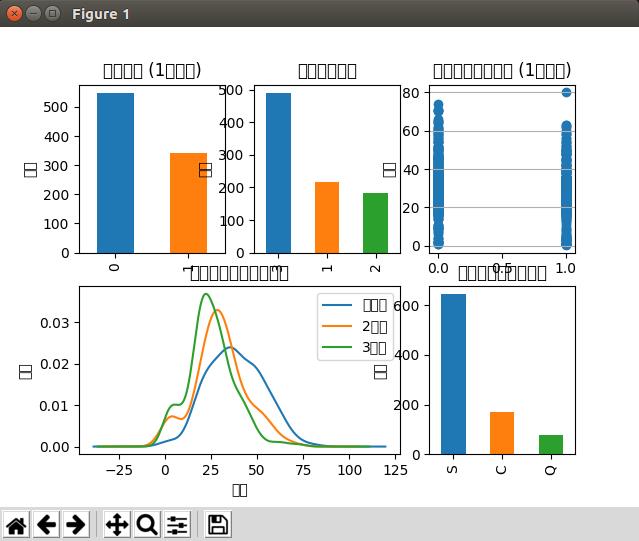
Matplotlib and Tkinter were successfully imported.
Okay, the problem is finally solved!

