Today, I debugged the application on CentOS 7 system and found that Chinese is a pile of random codes. Then I checked the data and solved it successfully. I hereby record it.
1. Execute the locale command to view the preview environment of the current system
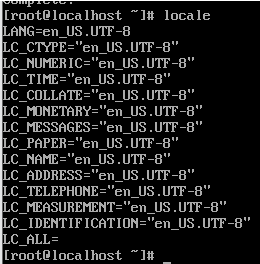
It can be seen that my language environment is not Chinese, but ASCII.
2. Execute locale – a | grep zh_ Cn * check whether the current system has a Chinese language pack
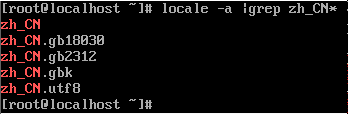
If the above content is displayed, the Chinese package has been installed. If not, execute Yum install kde-l10n-chinese
3. Execute VI/etc/locale.conf, as shown below
LANG=”en_ US.UTF-8″
Change “en-us.utf-8” to “zh”_ CN.UTF-8”
4. Execute source/etc/locale.conf
5. Execute locale to view the results
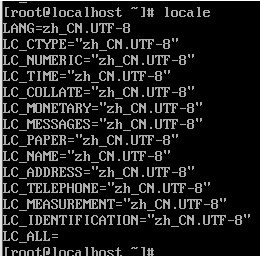
As shown in the above figure, the modification is successful
————————————————
References:
https://blog.csdn.net/jisu30miao1225/article/details/80519368
Similar Posts:
- [Solved] SSH Remote execute Python 3 error: Unicode encodeerror: ‘ASCII’ codec
- PLSQL error message frame garbled code
- [Linux error highlights] IBus input method of Ubuntu system cannot be switched to Pinyin
- Oracle Error: ORA-01843: not a valid month [Solved]
- [Django] python manage.py syncdb Unknown command: ‘syncdb’
- Creating react webpack project through yeoman
- Solve the problem of MySQL error reporting and lack of libaio. So. 1
- [Solved] svn:Error output could not be translated from the native locale to UTF-8
- [Solved] Ubuntu 18.04 installation vscode configuration and error reporting
- The database could not be exclusively locked to perform the operation (SQL Server 5030 error solution)