Install the framework according to the tutorial on the official website of Darknet. According to your own conditions (NVIDIA graphics card driver has been installed, cuda9.0 cudnn7.1), modify GPU = 1 cudnn = 1 opencv = 1 in the makefile file, then make again, and then download yolov3 After weights, then use the test command provided on the web page to test.
darknet: ./src/cuda.c:36: check_error: Assertion `0' failed.
The result is an error: memory overflow.CUDA Error: out of memory
darknet: ./src/cuda.c:36: check_error: Assertion `0′ failed.
abort (core dumped) 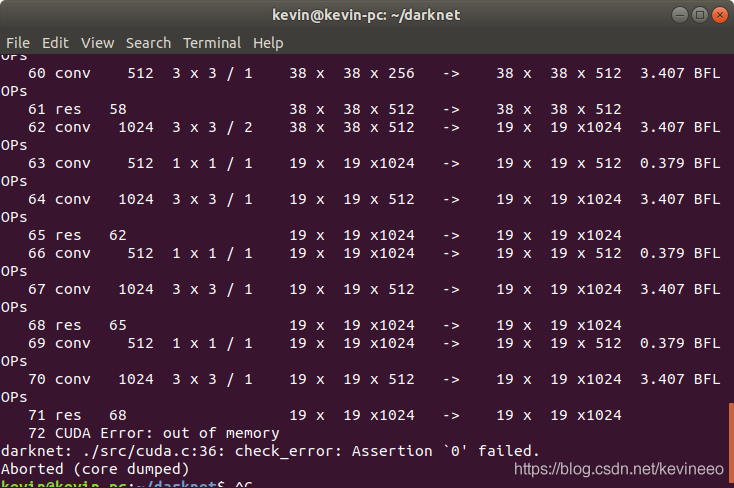 then modify yolov3.0 in the CFG folder Cfg file, original yolov3 The cfg file starts with:
then modify yolov3.0 in the CFG folder Cfg file, original yolov3 The cfg file starts with:
[net] # Testing #batch=1 #subdivisions=1 # Training batch=64 subdivisions=16
Amend to read:
[net] # Testing batch=1 subdivisions=1 # Training #batch=64 #subdivisions=16
Batch can greatly reduce the amount of memory. If there is still insufficient memory in the above way, there are only two solutions, either use a smaller model or change yolov3.0 in the CFG directory The height and width values of CFG lines 8 and 9 are changed to 416 in width and height, and the test will be OK. Modified Yolo.cfg file: 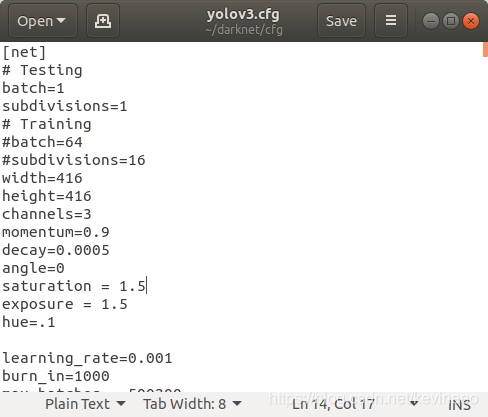
no problem if you test again. 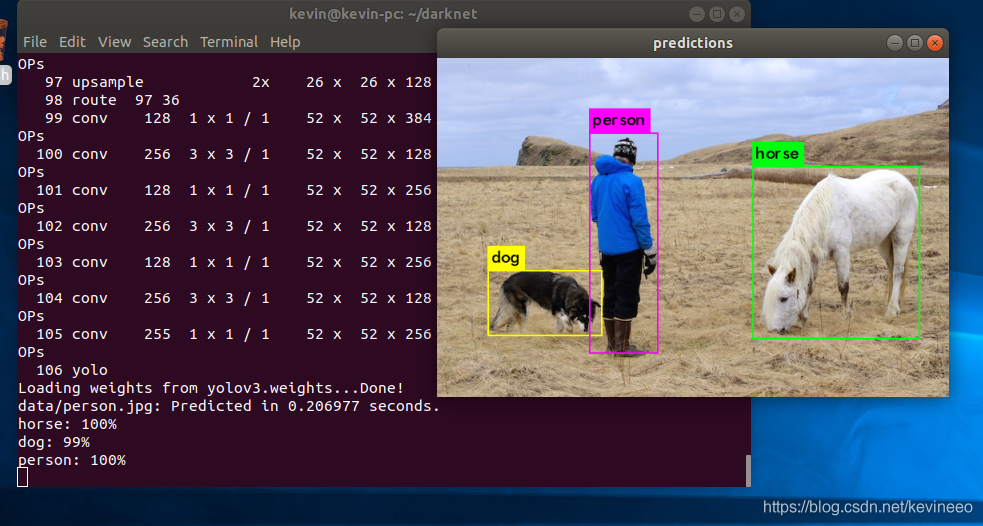
Similar Posts:
- [Solved] c# yolo cuDNN Error: CUDNN_STATUS_BAD_PARAM
- The solution of CUDA error: out of memory in yolo3 training
- [Solved] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
- Runtimeerror: CUDA error: out of memory [How to Solve]
- Ffmpeg scaling — the solution of “width / height not divisible by 2”
- ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory [Solved]
- [Solved] Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
- [Solved] Pytorch load pre-training model Error: modulenotfounderror: no module named ‘models’
- ImportError: DLL load failed: The specified module could not be found
- [Solved] Failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED