1、 Problem background
1. How to fix “cannot read JPEG2000 Image: Java advanced imaging (Jai) image I/O tools are not installed”
I’m building a java project to get images from PDF using pdfbox. Because I’m using Tika app for other functions, I decided to use the pdfbox in tika-app-1.20.jar.
I have tried to include jai-imageio-core-1.3.1.jar because Tika app is bundled with this jar. I tried using Tika app jar alone.
The code that throws the error:
PDXObject object=resources.getXObject(cosName);
Bad log trace:
org.apache.pdfbox.filter.MissingImageReaderException: Cannot read JPEG2000 image:
Java Advanced Imaging (JAI) Image I/O Tools are not installed
at org.apache.pdfbox.filter.Filter.findImageReader(Filter.java:163)
at org.apache.pdfbox.filter.JPXFilter.readJPX(JPXFilter.java:115)
at org.apache.pdfbox.filter.JPXFilter.decode(JPXFilter.java:64)
at org.apache.pdfbox.cos.COSInputStream.create(COSInputStream.java:77)
at org.apache.pdfbox.cos.COSStream.createInputStream(COSStream.java:175)
at org.apache.pdfbox.cos.COSStream.createInputStream(COSStream.java:163)
at org.apache.pdfbox.pdmodel.common.PDStream.createInputStream(PDStream.java:236)
at org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject.<init>(PDImageXObject.java:140)
at org.apache.pdfbox.pdmodel.graphics.PDXObject.createXObject(PDXObject.java:70)
at org.apache.pdfbox.pdmodel.PDResources.getXObject(PDResources.java:426)
But I’m sure I have the Jai imageio kernel in Tika, which is invisible when I run the code.
Solution:
1. It happens that it requires an additional jar known as jai-imageio-jpeg 2000 to support jp2k images.
2. In fact, I found this error by chance, but it is mentioned in the pdfbox document here. You need to add the following dependencies to pom.xml:
<dependency>
<groupId>com.github.jai-imageio</groupId>
<artifactId>jai-imageio-core</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>com.github.jai-imageio</groupId>
<artifactId>jai-imageio-jpeg2000</artifactId>
<version>1.3.0</version>
</dependency>
<!-- Optional for you ; just to avoid the same error with JBIG2 images -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jbig2-imageio</artifactId>
<version>3.0.3</version>
</dependency>
To avoid the same error in JBIG2 images, you can add the following dependency.
If you are using gradle, add dependencies like this:
dependencies {
implementation 'com.github.jai-imageio:jai-imageio-core:1.4.0'
implementation 'com.github.jai-imageio:jai-imageio-jpeg2000:1.3.0'
// Optional for you ; just to avoid the same error with JBIG2 images
implementation 'org.apache.pdfbox:jbig2-imageio:3.0.3'
}
2、 Project instance scenario
1. Problem scenario:
In the project, there is a bug in the document conversion – PDF to picture function (using pdfbox2.0.2). Many picture elements in the original PDF file disappear after being converted into pictures. This is not bad. Check the log and find a large number of errors:
ERROR o.a.p.contentstream.PDFStreamEngine eight hundred and ninety – Cannot read JPEG2000 image: Java Advanced Imaging (JAI) Image I/O Tools are not installed
This means that there is a lack of I/O tools to read JPEG2000 images. The problem should be here.
2. Cause of the problem: the scanned image that may be included in the PDF file is a picture in JPEG2000 format, so the pdfbox needs the support of Jai in the conversion process.
3. Solution: add related dependencies
Overseas stackoverflow: https://stackoverflow.com/questions/42169154/pdfbox1-8-12-convert-pdf-to-white-page-image , the last humble little reply gave inspiration and added dependence
4. Comparison:
Before adding dependency – picture missing

After adding dependency – picture display

3、 Introduction to JPEG and JPEG2000
1. Background:
The full name of JPEG is joint photographic experts group. It is a committee engaged in the formulation of still image compression standards under the international standards organization (ISO). It has formulated the first set of national standard still image compression standard: ISO 10918-1, which is commonly known as JPEG. Due to the excellent quality of JPEG, it has achieved great success in just a few years. At present, 80% of the images on the website adopt JPEG compression standard.
However, with the rapid development of multimedia applications, the traditional JPEG compression technology can not meet the requirements of people for multimedia image data. Therefore, JPEG 2000, a new generation of still image compression technology with higher compression rate and more new functions, was born. The official name of JPEG 2000 is “ISO 15444”, which is also formulated by JPEG organization.
2. Basic concepts
JPEG 2000 is an image compression standard based on wavelet transform, which is created and maintained by the Joint Photographic Experts Group. JPEG 2000 is generally considered as the next generation image compression standard to replace JPEG (based on discrete cosine transform) in the future. The extension name of JPEG 2000 file is usually. JP2, and the MIME type is image/JP2.
JPEG2000 has a higher compression ratio and will not produce the block blur artifacts generated by the original JPEG standard based on discrete cosine transform.
JPEG2000 supports both lossy compression and lossless compression.
In addition, JPEG2000 also supports more complex progressive display and download.
Because JPEG2000 can still have a good compression rate under lossless compression, JPEG2000 has been widely used in the analysis and processing of medical images with high image quality requirements.
3. JPEG2000 principle
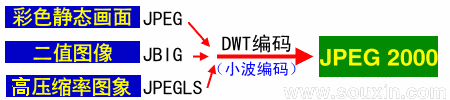
The biggest difference between JPEG 2000 and traditional JPEG is that it abandons the block coding method based on discrete cosine transform, and adopts the multi analysis coding method based on wavelet transform.
The main purpose of wavelet transform is to extract the frequency components of the image. Refer to the following figure for a simple schematic diagram.
4. JPEG2000 benefits
(1) As an upgraded version of JPEG, JPEG 2000 aims at high compression (low bit rate), and its compression rate is about 30% higher than JPEG
(2) JPEG2000 supports both lossy and lossless compression, while JPEG can only support lossy compression. Therefore, it is suitable for saving important pictures
(3) JPEG2000 can realize progressive transmission, which is an extremely important feature of JPEG2000. This is our understanding of GIF
The “fade out” characteristic of format image. It first transmits the outline of the image, and then gradually transmits the data to continuously improve the image quality, so that the image can be displayed from hazy to clear, instead of JPEG
Same, displayed slowly from top to bottom
(4) JPEG2000 supports the so-called “region of interest” feature. You can arbitrarily specify the compression quality of the region of interest on the image, and you can also select the specified part to decompress first. In this way, we can easily highlight the key points.
5. JPEG2000 copyright and patent issues
JPEG2000 has copyright and patent risks. This may be one of the reasons why JPEG2000 technology has not been widely used at present.
JPEG2000 standard itself has no licensing fee. However, because a large number of algorithms in the core part of coding are patented, it is generally considered that it is unlikely to avoid these patent fees to develop a commercial encoder free of licensing fee.