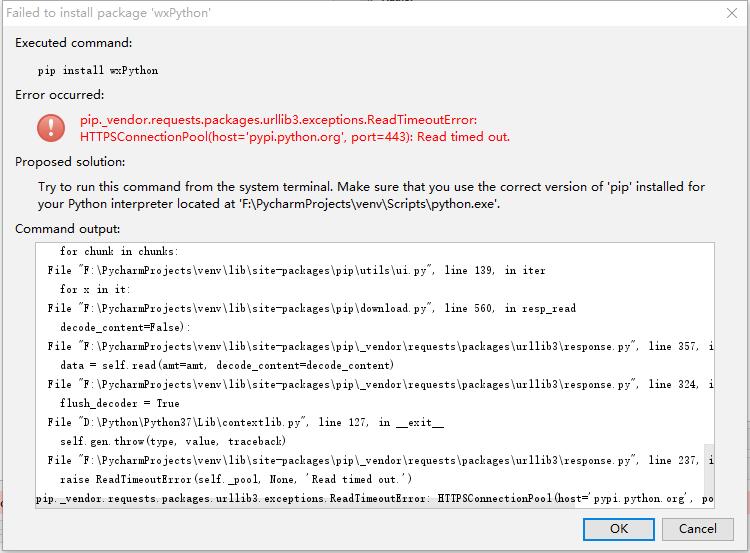
The objects handled by the functools module are all other functions, and any callable object can be regarded as a function for this module
1. functools.cmp_ to_ Key (func)
because Python 3 does not support comparison function, CMP_ to_ Key is to convert the old-fashioned comparison function into key function and use it together with functions that can accept key function, such as sorted, list. Sort, min, Max, heapq. Nlargest, itertools. Groupby, etc
examples:
from functools import cmp_to_key
def compare(x1, x2):
return x1 - x2
a = [2, 3, 1]
print(sorted(a, key=cmp_to_key(compare)))
a.sort(key=cmp_to_key(compare))
print(a)
Output:
[1, 2, 3]
[1, 2, 3]
2. @functools.lru_ cache(maxsize=128, typed=False)
lru_ Cache can be used as a decorator to cache the time-consuming results of function calculation to save time
because the dictionary is used for caching, the keyword parameters and location parameters of the function must be hashable
if maxsize = none, LRU function is disabled, and the cache can grow unlimited
when maxsize is the power of 2, LRU has the best performance
If typed is set to true, different types of function parameters, such as f (3) and f (3.0), will be cached separately, and will be regarded as different calls with different results
cache_ The info() function can be used to measure the validity of the cache and optimize the maxsize parameter. This function returns a named tuple of hits, misses, maxsize, and currsize
examples:
from functools import lru_cache
@lru_cache(maxsize=32)
def get_pep(num):
resource = "http://www.python.org/dev/peps/pep-%04d/" % num
try:
with urllib.request.urlopen(resource) as s:
return s.read()
except urllib.error.HTTPError:
return "Not Found"
for n in 8, 290, 308, 320, 8, 218, 320, 279, 289, 320, 9991:
pep = get_pep(n)
print(n, len(pep))
print(get_pep.cache_info())
@lru_cache(maxsize=None)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n - 2)
print([fib(n) for n in range(16)])
print(fib.cache_info())
3. @functools.total_ Ordering
specifies a class that has one or more comparison sorting methods defined, and the class modifier provides the rest of the methods
this class must have been defined__ lt__(), __ le__(), __ gt__(), __ ge__() And defines__ eq__()
from functools import total_ordering
@total_ordering
class Student:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
@staticmethod
def _is_valid_operand(other):
return hasattr(other, "last_name") and hasattr(other, "first_name")
def __eq__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return ((self.last_name.lower(), self.first_name.lower()) ==
(other.last_name.lower(), other.first_name.lower()))
def __lt__(self, other):
if not self._is_valid_operand(other):
return NotImplemented
return ((self.last_name.lower(), self.first_name.lower()) <
(other.last_name.lower(), other.first_name.lower()))
a = Student(first_name="tom", last_name="hancs")
b = Student(first_name="tom", last_name="hancs")
print(a == b)
print(a <= b)
print(a >= b)
If you don’t use total_ To decorate a decorator, use & lt= Or & gt= Error will be reported:
Traceback (most recent call last):
File "D:/LearnProject/performance/functools_test.py", line 33, in <module>
print(a <= b)
TypeError: '<=' not supported between instances of 'Student' and 'Student'
4. Functools. Partial (func, * args, * * keywords)
partial() is used to freeze function parameters or one of the key parts, and generate a new function object that simplifies the parameter passing in<
example:
from functools import partial
basetwo = partial(int, base=2)
print(basetwo('111'))
5. Functools. Partialmethod (func, * args, * * keywords)
function is similar to partial, usage is as follows:
from functools import partialmethod
class Cell(object):
def __init__(self):
self._alive = False
@property
def alive(self):
return self._alive
def set_state(self, state):
self._alive = bool(state)
set_alive = partialmethod(set_state, True)
set_dead = partialmethod(set_state, False)
c = Cell()
print(c.alive)
c.set_alive()
print(c.alive)
6. Reduce (function, iterative [, initializer])
cumulate the functions of two parameters from left to right to sequence items, such as reduce (lambda x, Y: x + y, [1, 2, 3, 4, 5]), which is equivalent to calculating (((1 + 2) + 3) + 4) + 5)
from functools import reduce
print(reduce(lambda x, y: x+y, range(0, 10)))
7. @ functools. Singledispatch
when a function needs to determine the output content according to the type of the input variable, the usual way is to use a large number of if/elif/else to solve the problem inside the function
this will make the code bulky, difficult to maintain, and not easy to expand
from functools import singledispatch
@singledispatch
def func(arg, verbose=False):
if verbose:
print("Let me just say,", end=" ")
print(arg)
@func.register(int)
def _(arg, verbose=False):
if verbose:
print("Strength in numbers, eh?", end=" ")
print(arg)
@func.register(list)
def _(arg, verbose=False):
if verbose:
print("Enumerate this:")
for i, elem in enumerate(arg):
print(i, elem)
def nothing(arg, verbose=False):
print("Nothing.")
func.register(type(None), nothing)
@func.register(float)
def fun_num(arg, verbose=False):
if verbose:
print("Half of your number:", end=" ")
print(arg/2)
func("Hello, world.")
func("test.", verbose=True)
func(42, verbose=True)
func(["spam", "spam", "eggs", "spam"], verbose=True)
func(None)
func(1.23)
# Check which implementation the generic function will choose for a given type
print(func.dispatch(float))
print(func.dispatch(dict))
# Access to all registered implementations
print(func.registry.keys())
print(func.registry[float])
8. functools.update_ wrapper(wrapper, wrapped, assigned=WRAPPER_ ASSIGNMENTS, updated=WRAPPER_ Updates)
used to update the__ name__,__ doc__ To make it look like a decorated function
from functools import update_wrapper
def wrap(func):
def call_it(*args, **kwargs):
"""call it"""
return func(*args, **kwargs)
return call_it
@wrap
def hello():
"""say hello"""
print("hello world")
def wrap2(func):
def call_it2(*args, **kwargs):
"""call it2"""
return func(*args, **kwargs)
return update_wrapper(call_it2, func)
@wrap2
def hello2():
"""say hello2"""
print("hello world2")
print(hello.__name__)
print(hello.__doc__)
print(hello2.__name__)
print(hello2.__doc__)
9. @functools.wraps(wrapped, assigned=WRAPPER_ ASSIGNMENTS, updated=WRAPPER_ Updates)
decorators that use wraps can retain the properties of the decorated function
from functools import wraps
def my_decorator(f):
@wraps(f)
def wrapper(*args, **kwargs):
print("Calling decorated function")
return f(*args, **kwargs)
return wrapper
@my_decorator
def example():
"""Example Docstring"""
print("Called example function")
example()
print(example.__name__)
print(example.__doc__)
The examples in this article come from Python official documents and the Internet