ResourceManger Restart
Resource manager is responsible for resource management and application scheduling, and it is the core component of yard. There may be a single point of failure. ResourceManager restart is a feature that enables RM to make yarn cluster work normally when it restarts, and the failure of RM is not known by users
ResourceManager Restart feature is divided into two phases:
ResourceManager Restart Phase 1 (Non-work-preserving RM restart, since hadoop2.4.0): Enhance RM to persist application/attempt state and other credentials information in a pluggable state-store. RM will reload this information from state-store upon restart and re-kick the previously running applications. Users are not required to re-submit the applications.
ResourceManager Restart Phase 2 (Work-preserving RM restart, since hadoop2.6.0): Focus on re-constructing the running state of ResourceManager by combining the container statuses from NodeManagers and container requests from ApplicationMasters upon restart. The key difference from phase 1 is that previously running applications will not be killed after RM restarts, and so applications won’t lose its work because of RM outage.
ResourceManager High Availability
Before Hadoop 2.4.0, resource manager had the problem of single point failure. Yarn’s ha (high availability) uses the actice/standby structure. At any time, there is only one active RM and one or more standby RMS. In fact, the ResourceManager is backed up so that active RM and standby RM exist in the system
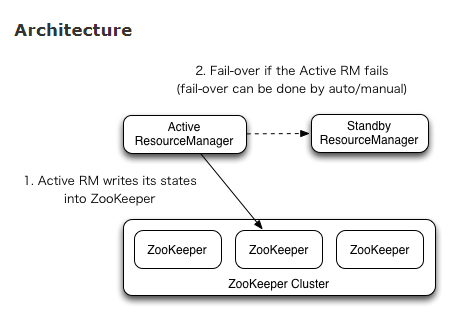
Manual transitions and failover
Enter yarn rmadmin
Automatic failover
When RM fails or no longer responds, a new active RM is elected based on zookeeper’s activestandbyelector (it has been embedded in RM, and there is no need to start a separate zkfc daemon)
Client, ApplicationMaster and NodeManager on RM failover
If there are multiple RMS, the yarn-site.xml file on all nodes needs to list all RMS. Clients, AMS and NMS connect to RMS in round robin mode until an active RM is encountered. If the active RM fails, find the new active RM again in the round robin way
The YARN Timeline Server
Yard solves the storage and retrieval of apps current information and historical information through timeline server . Timelineserver has two responsibilities:
Persisting Application Specific Information
The collection and retrieval of information is related to a specific app or framework. For example, the information of MapReduce framework can include number of map tasks, reduce tasks, counters… Etc. Users can send the special information of APP through the timelineclient included in application master
Or app container
Persisting Generic Information about Completed Applications
Generic information is the information of APP level, such as queue name, user info, etc. The general data is released to the timeline store by yarn’s RM, which is used to display the completed apps of Web UI
NodeManager Restart
Nodemanager restart mechanism can keep the active containers of the node where nodemanager is located. When nm processes the container management request, it stores the necessary states in the local state store. When NMS restarts, first load the state for different subsystems, and then let the subsystems use the loaded state to recover
enabling NM Restart:
(1) Set yarn.nodemanager.recovery.enabled in/conf/yarn-site.xml to true. The default is false
(2) Configure a path to the local file-system directory where the NodeManager can save its run state.
(3) Configure a valid RPC address for the NodeManager.
(4) Auxiliary services.
Similar Posts:
- The key technologies in hadoop-3.0.0 configuration yarn.nodemanager.aux -Services item
- Spark2.x Error: Queue’s AM resource limit exceeded.
- [Solved] Hadoop Error: ERROR: Attempting to operate on yarn resourcemanager as root
- [Solved] Hive export MYSQL Error: Container [pid=3962,containerID=container_1632883011739_0002_01_000002] is running 270113280B beyond the ‘VIRTUAL’ memory limit.
- Yarn configures multi queue capacity scheduler
- Tuning and setting of memory and CPU on yarn cluster
- Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
- [Solved] /bin/bash: /us/rbin/jdk1.8.0/bin/java: No such file or directory
- [Solved] CDH6.3.2 Hive on spark Error: is running beyond physical memory limits
- [Solved] Hadoop runs start-dfs.sh error: attempting to operate on HDFS as root