1. Introduction
Let’s take a look at the phenomenon. You can download the code here first
Let’s briefly introduce the classes inside
package com.iceberg.springboot.web;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
//@ComponentScan("com.iceberg.springboot.biz")
//@ComponentScan("com.iceberg.springboot.manager")
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
Application startup class: I won’t say much about this. The above annotation is the key to this step
package com.iceberg.springboot.web.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.context.event.ApplicationReadyEvent;
import org.springframework.context.ApplicationListener;
import org.springframework.web.bind.annotation.RestController;
@Slf4j
@RestController
public class TestController implements ApplicationListener<ApplicationReadyEvent> {
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
log.warn("--------------------------TestController had loaded-----------------------------");
}
}
Testcontroller: applicationlistener is implemented here. When the spring container is started, this method will be called. Of course, the precondition is that testcontroller must be loaded into the spring container, so we can judge whether this class is loaded by spring through this log
As we all know, @ springbootapplication annotation will automatically scan the subpackages of the same package, so testcontroller will be loaded by spring
Let’s start the app and see the results
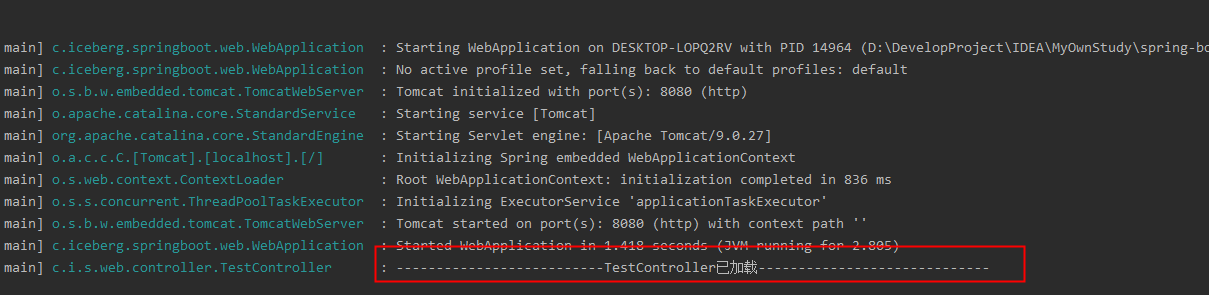
The log can be printed. It’s easy to understand. If it’s not printed, it’s the hell
Then we uncomment one of the @ componentscan and run it again
package com.iceberg.springboot.web;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@ComponentScan("com.iceberg.springboot.biz")
//@ComponentScan("com.iceberg.springboot.manager")
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
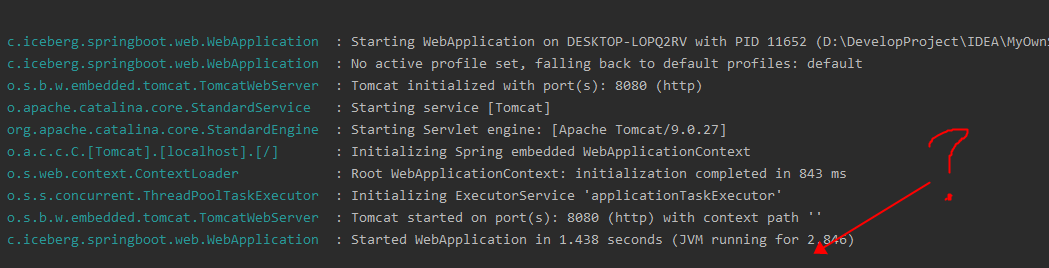
The log is gone! What the fuck???
Don’t panic. Let’s open the second comment to see the result
package com.iceberg.springboot.web;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@ComponentScan("com.iceberg.springboot.biz")
@ComponentScan("com.iceberg.springboot.manager")
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}
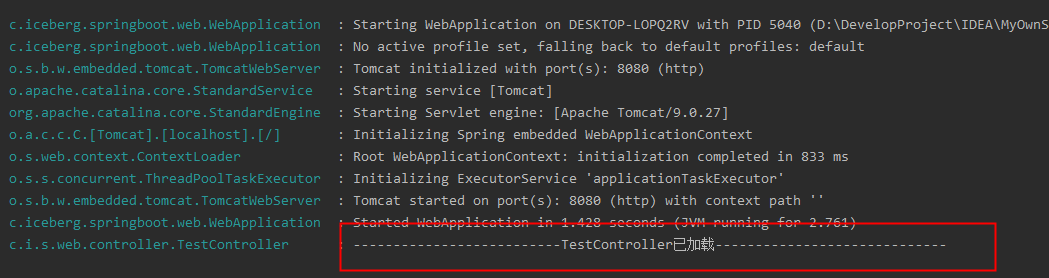
The log appears again
I don’t know what’s your mood, but my mood is probably the same as that of the two expression packs above. I even suspected that spring had a bug, but in the end I found out the cause of the problem. As for whether it was a bug or not… You can judge for yourself
2、 Analysis of spring boot startup process
The complete process analysis can be seen here. We only analyze the parts used here, and directly look at reading @ componentscans
//ConfigurationClassParser.java
//Line 258
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass) throws IOException {
//Omit part of the code
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
//Omit part of the code
}
//AnnotationConfigUtils.java
//line 288
static Set<AnnotationAttributes> attributesForRepeatable(AnnotationMetadata metadata,
Class<?> containerClass, Class<?> annotationClass) {
return attributesForRepeatable(metadata, containerClass.getName(), annotationClass.getName());
}
//AnnotationConfigUtils.java
//Line 295
//containerClassName:org.springframework.context.annotation.ComponentScans
//annotationClassName:org.springframework.context.annotation.ComponentScan
static Set<AnnotationAttributes> attributesForRepeatable(
AnnotationMetadata metadata, String containerClassName, String annotationClassName) {
Set<AnnotationAttributes> result = new LinkedHashSet<>();
//find @ComponentScan
addAttributesIfNotNull(result, metadata.getAnnotationAttributes(annotationClassName, false));
//find @ComponentScans
Map<String, Object> container = metadata.getAnnotationAttributes(containerClassName, false);
if (container != null && container.containsKey("value")) {
for (Map<String, Object> containedAttributes : (Map<String, Object>[]) container.get("value")) {
addAttributesIfNotNull(result, containedAttributes);
}
}
//Combine results
return Collections.unmodifiableSet(result);
}
The upper part is the code of the overall process, and the problem part is the lower part. Let’s look at these two methods one by one
metadata.getAnnotationAttributes(annotationClassName, false))
metadata.getAnnotationAttributes(containerClassName, false)
Let’s look at the logic of metadata. Getannotationattributes (annotationclassname, false))
I’ve omitted the middle process. Anyway, if you go all the way down, you’ll get to the bottom
//AnnotatedElementUtils.java
//line 903
//element:class com.iceberg.springboot.web.WebApplication
//annotationName:org.springframework.context.annotation.ComponentScan
private static <T> T searchWithGetSemantics(AnnotatedElement element,
Set<Class<?extends Annotation>> annotationTypes, @Nullable String annotationName,
@Nullable Class<?extends Annotation> containerType, Processor<T> processor,
Set<AnnotatedElement> visited, int metaDepth) {
if (visited.add(element)) {
try {
//Get all annotations on the WebApplication class
// This will fetch @SpringBootApplication and the unannotated @ComponentScan
List<Annotation> declaredAnnotations = Arrays.asList(AnnotationUtils.getDeclaredAnnotations(element));
T result = searchWithGetSemanticsInAnnotations(element, declaredAnnotations,
annotationTypes, annotationName, containerType, processor, visited, metaDepth);
if (result != null) {
return result;
}
//Omit part of the code
}
catch (Throwable ex) {
AnnotationUtils.handleIntrospectionFailure(element, ex);
}
}
return null;
}
The code at the top of
gets all the annotations on the application startup class, and then calls the searchWithGetSemanticsInAnnotations method to make the actual judgement. Here are three cases
Only @ springbootapplication annotation exists
There is @ springbootapplication and a @ componentscan annotation
There are @ springbootapplication and multiple @ componentscan annotations
Let’s analyze them one by one
(1) Only @ springbootapplication annotation exists
//AnnotatedElementUtils.java
//line 967
private static <T> T searchWithGetSemanticsInAnnotations(@Nullable AnnotatedElement element,
List<Annotation> annotations, Set<Class<?extends Annotation>> annotationTypes,
@Nullable String annotationName, @Nullable Class<?extends Annotation> containerType,
Processor<T> processor, Set<AnnotatedElement> visited, int metaDepth) {
//The first for loop serves to detect the presence of the @ComponentScan annotation
//Obviously there is no such annotation in the first case, so the code for the first loop is directly omitted
//Omit part of the code
//The second loop recursively looks for the presence of the @ComponentScan and @ComponentScans annotations in the annotation
//This is where you find the @ComponentScan in @SpringBootApplication and return it
//If you want to go deeper into how it works, you can look at the code yourself
for (Annotation annotation : annotations) {
Class<?extends Annotation> currentAnnotationType = annotation.annotationType();
if (!AnnotationUtils.hasPlainJavaAnnotationsOnly(currentAnnotationType)) {
T result = searchWithGetSemantics(currentAnnotationType, annotationTypes,
annotationName, containerType, processor, visited, metaDepth + 1);
if (result != null) {
processor.postProcess(element, annotation, result);
if (processor.aggregates() && metaDepth == 0) {
processor.getAggregatedResults().add(result);
}
else {
return result;
}
}
}
}
}
(2) There is @ springbootapplication and a @ componentscan annotation
//AnnotatedElementUtils.java
//line 967
private static <T> T searchWithGetSemanticsInAnnotations(@Nullable AnnotatedElement element,
List<Annotation> annotations, Set<Class<?extends Annotation>> annotationTypes,
@Nullable String annotationName, @Nullable Class<?extends Annotation> containerType,
Processor<T> processor, Set<AnnotatedElement> visited, int metaDepth) {
for (Annotation annotation : annotations) {
Class<?extends Annotation> currentAnnotationType = annotation.annotationType();
if (!AnnotationUtils.isInJavaLangAnnotationPackage(currentAnnotationType)) {
//Determine if the annotation is a @ComponentScan annotation
if (annotationTypes.contains(currentAnnotationType) ||
currentAnnotationType.getName().equals(annotationName) ||
processor.alwaysProcesses()) {
T result = processor.process(element, annotation, metaDepth);
if (result ! = null) {
//we don't know what the function of this judgment is
//If you know, please tell us.
//but the judgment here is false, so the result will be returned directly
if (processor.aggregates() && metaDepth == 0) {
processor.getAggregatedResults().add(result);
}
else {
return result;
}
}
}
//Omit part of the code
}
}
//Omit the second loop
}
You can see that when there is a @ componentscan annotation, it will directly return this annotation, and will not parse the configuration in @ springbootapplication, so testcontroller is not loaded into the spring container
(3) There are @ springbootapplication and multiple @ componentscan annotations
If one @ componentscan annotation can override the corresponding configuration in @ springbootapplication, why can multiple @ componentscan annotations be used again
Haha, let’s first explain that the source code we analyzed before is under the spring core package, so even if you don’t use spring boot, its logic is the same. Then we usually use multiple @ componentscan without any problems
Here we will introduce a new annotation – @ repeatable. Let’s take a look at the code of @ componentscan
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
}
You can see that there is a @ repeatable annotation on the top. This is a new annotation added in jdk8. When there are multiple @ componentscan annotations, they will be converted into an array as the value of @ componentscans
So the third case is @ springbootapplication and a @ componentscans annotation. Note that there is s in this case, so the package scan in @ springbootapplication will still take effect
@The parsing logic of componentscans annotation is in the metadata. Getannotationattributes (containerclassname, false) method. The specific logic will not be analyzed. After all, we have found the root of the problem
3、 Summary
Then we summarize the reasons for the three phenomena
(1) Only @ springbootapplication can print the log normally
@Springbootapplication will scan the same package and sub package by default, so testcontroller will be scanned and the log will be printed
(2) There is @ springbootapplication and a @ componentscan annotation, and the log is not printed
@The componentscan annotation will be processed first and then returned so that the configuration in @ springbootapplication does not take effect
(3) There are @ springbootapplication and multiple @ componentscan annotations, and the log is printed normally
Multiple @ componentscan annotations will be integrated into one @ componentscan annotation, which will not affect the correct reading of the configuration in @ springbootapplication
Solution:
Use @ componentscan annotation instead of using @ componentscan annotation directly
This is the most perfect solution, which will not affect the configuration of springboot itself. You can also customize your own configuration at will
@SpringBootApplication
@ComponentScans({
@ComponentScan("com.iceberg.springboot.biz"),
@ComponentScan("com.iceberg.springboot.manager")
})
public class WebApplication {
public static void main(String[] args) {
SpringApplication.run(WebApplication.class, args);
}
}