![]()
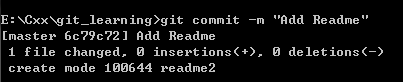
Reason: git commit – M followed by single quotation mark in MS DOS cannot contain spaces
Solution:
Method 1. Remove the space

Method 2. Use double quotation marks
![]()
Reason: git commit – M followed by single quotation mark in MS DOS cannot contain spaces
Solution:
Method 1. Remove the space
Method 2. Use double quotation marks
[root@iZbp1he0bdge2g92l9fjnxZ ~]# systemctl restart zabbix-agent
Error getting authority: Error initializing authority: Error calling StartServiceByName for org.freedesktop.PolicyKit1: Timeout was reached (g-io-error-quark, 24)
Failed to restart zabbix-agent.service: Connection timed out
See system logs and 'systemctl status zabbix-agent.service' for details.When installing the service using centos 7.4 an error was reported.
Error reported when starting zabbix.
Centos using Systemctl reports Error getting authority: Error initializing authority: Error calling StartServiceByName for org.freedesktop.PolicyKit1: Timeout was reached (g-io-error-quark, 24)
Error getting authority: Error initializing authority: Error calling StartServiceByName for org.freedesktop.PolicyKit1: Timeout was reached (g-io-error-quark, 24)Solution:
ps -ef |grep polkit
Reinstall:
pyum reinstall polkit
Restart
reboot
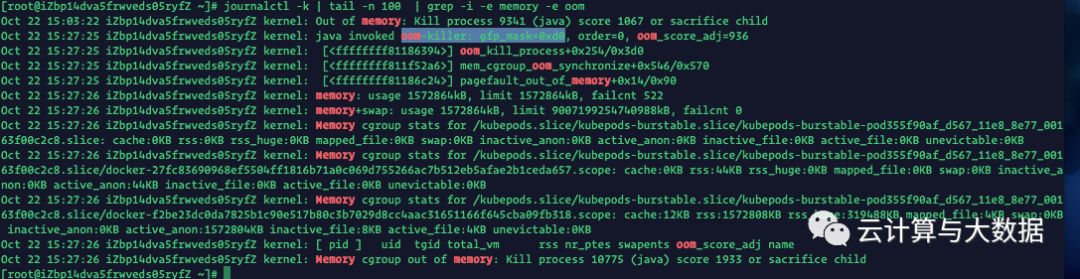
The problem is that the reference triggers the oom, and then the kill signal causes the pod terminal to stop
If a container is no longer running, use the following command to find the status of the container:
docker container ls -aThis article explains possible reasons for the following exit code:
"task: non-zero exit (137)"With exit code 137, you might also notice a status ofShutdownor the following failed message:
Failed 42 hours agoThe"task: non-zero exit (137)"message is effectively the result of akill -9(128 + 9). This can be due to a couple possibilities (seen most often with Java applications):
The container received adocker stop, and the application didn’t gracefully handleSIGTERM(kill -15) — whenever aSIGTERMhas been issued, the docker daemon waits 10 seconds then issue aSIGKILL(kill -9) to guarantee the shutdown. To test whether your containerized application correctly handlesSIGTERM, simply issue adocker stopagainst the container ID and check to see whether you get the"task: non-zero exit (137)". This is not something to test in a production environment, as you can expect at least a brief interruption of service. Best practices would be to test in a development or test Docker environment.
The application hit an OOM (out of memory) condition. With regards to OOM condition handling, review the node’s kernel logs to validate whether this occurred. This would require knowing which node the failed container was running on, or proceed with checking all nodes. Run something like this on your node(s) to help you identify whether you’ve had a container hit an OOM condition:
journalctl -k | grep -i -e memory -e oomAnother option would be to inspect the (failed) container:
docker inspect <container ID>Review the application’s memory requirements and ensure that the container it’s running in has sufficient memory. Conversely, set a limit on the container’s memory to ensure that wherever it runs, it does not consume memory to the detriment of the node.
If the application is Java-based, you may want to review the maximum memory configuration settings.
docker runcommand line options
Specify hard limits on memory available to containers (-m, –memory)
The main reason for this error is that the hard disk fails to pass the test. Here are two ways to avoid this problem:
Modify grub
This method is quite popular on the Internet. Post it directly:
When entering the Startup menu of Ubuntu, select * Ubuntu with the cursor, and press the e key on the keyboard to enter the startup item editing mode
Use the cursor to locate the position as shown in the figure below, change RO to RW, and press F10 to guide the system according to the modified parameters
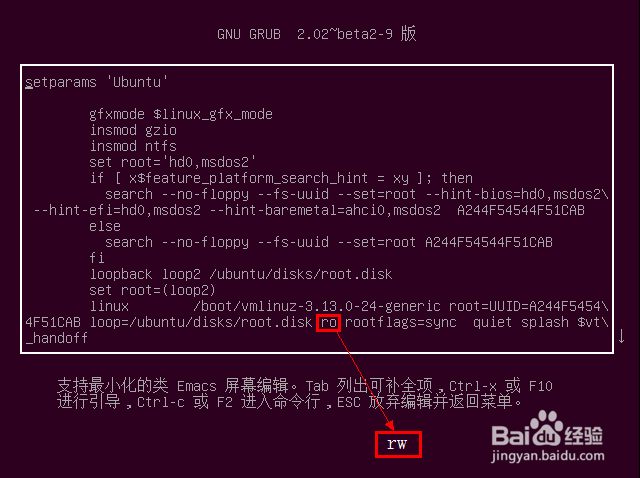
Enter sudo GEDIT/etc/grub.d/10_ Enter after lupin:
Enter the user password and press enter to call the text editor to open the boot item configuration file, and replace ro ${args} with RW ${args}
Save the file, then sudo update grub updates grub, and restart
Disable hard disk detection
The first method may lead to similar problems in the future. The most fundamental method is to prohibit Ubuntu from checking the hard disk when it starts. So how to prohibit it
Modify the/etc/fstab file, change the last digit 1/2 of the corresponding line of each mount item to 0, and then save it
# < file system> < mount point> < type> < options> < dump> < pass>
#/was on /dev/sda1 during installation
UUID=80c83157-8cfd-46e8-be12-993d5fcb6c20/ ext4 defaults 0 0
# /boot was on /dev/sda6 during installation
UUID=04197eeb-babf-4568-8686-cf4a31751827 /boot ext4 defaults 0 0
# /opt was on /dev/sda5 during installation
UUID=8685f4ea-3b2e-4bce-a729-a7a0629925f1 /opt ext4 defaults 0 0
# swap was on /dev/sda7 during installation
UUID=90de3311-1664-4532-8677-fa1f665af82a none swap sw 0 0
~
Environment: centos7.6 oracle19c
To install an Oracle 19C server on Linux, I have not touched the Linux command for a long time. I have almost forgotten about it. After experiencing the problem of no permission (I have permission to view the file attributes, and finally reset the MKDIR path), xdpyinfo and so on, when I finally entered the graphical interface, I had a crash problem
Graphical installation, in the pre check after the install step to report the error dialog box: figure no error, the content is as follows
makefile ‘/oracle/product/10.2.0/db_ 1/rdbms/lib/ins_ Target ‘libasmclntsh19.ohso libasmperl19.ohso client’ of RDBMS. MK ‘_ Error in sharedlib ‘. Please refer to ‘/ TMP/installactions2021-02-04_ 03-36-27PM/installActions2021-02-04_ 03-36-27PM.log’
Then I went to check the error file and found the following:
/usr/bin/ld:/u01/app/oracle/product/19.2.0/db_ 1/lib//libclntsh.so: file format not recognized; treating as linker script
/usr/bin/ld:/u01/app/oracle/product/19.2.0/db_ 1/lib//libclntsh.so:1: syntax error
lib// libclntsh.so How can there be two libclntsh.so//
Baidu first, as like as two peas, someone and I have the same problem, the same mistake. Please click the link to set up 1 according to his method. There’s only one environment. His method 2 doesn’t work
Take a look at the actual error. Go to lib and find the libclntsh.so file. It exists, and it’s under lib /. How can there be one more /?View the. Bash of Oracle users_ profile,ORACLE_ HOME,LIB_ Path and other configuration items, no problem, no more writing after lib/
Bing international, there are some foreigners who have encountered this problem in Oracle support. Can we solve this problem?I’m glad to go in and disappointed to come out. The answer is to support the account. It’s a real pit
Let’s take a look at the online installation tutorials (some of the tutorials are pitiful, there are obvious errors, copy and paste if you don’t write them well…), check one by one, I suddenly find a problem, in the tutorial, unzip command is used to unzip, and I unzip the 19C zip package under windows, and then copy the unzip content to CentOS machine with winscp, sure enough, I put the zip package on CentOS, unzip it, and then install it. Finally, this shit problem is gone… Who would have thought
Summary: in the future, things in Linux must be decompressed on Linux
DNT@DESKTOP-PTACRF6 MINGW64 ~/Windows10 (master)
$ git clone [email protected]:dunitian/IPToPosition.git
fatal: could not create work tree dir’IPToPosition’: No such file or directory

Look at the path of the execution directory==>~/Windows10 (master)
Switch to the root directory: cd ~
Enter the command again and it’s ok
DNT@DESKTOP-PTACRF6 MINGW64 ~
$ git clone [email protected]:dunitian/IPToPosition.git
Cloning into’IPToPosition’…
Warning: Permanently added the RSA host key for IP address ‘192.30.252.130’ to the list of known hosts.
warning: You appear to have cloned an empty repository.
Checking connectivity… done.

Install the python-devlibrary according to the Python version used .
sudo apt-get install python-dev # for python2.x installs
sudo apt-get install python3-dev # for python3.x installs
For example, in the case of using Python 3.6, pass:
sudo apt-get install python3.6-dev
Install python-dev.
hu@hu-VirtualBox:/home/newdisk/telnet-scanner$ sudo pip install MySQL-python
[sudo] hu password:
The directory ‘/home/hu/.cache/pip/http’ or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo’s -H flag.
The directory ‘/home/hu/.cache/pip’ or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo’s -H flag.
Collecting MySQL-python
Downloading https://files.pythonhosted.org/packages/a5/e9/51b544da85a36a68debe7a7091f068d802fc515a3a202652828c73453cad/MySQL-python-1.2.5.zip (108kB)
100% |████████████████████████████████| 112kB 655kB/s
Complete output from command python setup.py egg_info:
sh: 1: mysql_config: not found
Traceback (most recent call last):
File “<string>”, line 1, in <module>
File “/tmp/pip-build-9enuqi/MySQL-python/setup.py”, line 17, in <module>
metadata, options = get_config()
File “/tmp/pip-build-9enuqi/MySQL-python/setup_posix.py”, line 43, in get_config
libs = mysql_config(“libs_r”)
File “/tmp/pip-build-9enuqi/MySQL-python/setup_posix.py”, line 25, in mysql_config
raise EnvironmentError(“%s not found” % (mysql_config.path,))
EnvironmentError: mysql_config not found
—————————————-
Command “python setup.py egg_info” failed with error code 1 in /tmp/pip-build-9enuqi/MySQL-python/
You are using pip version 8.1.1, however version 18.0 is available.
You should consider upgrading via the ‘pip install –upgrade pip’ command.
It shows that mysql should not be installed, because mysql-python is a plugin for mysql, so you need to install mysql to cover this bug
Perform the following operation.
sudo apt-get install mysql-server
sudo apt-get install libmysqlclient-dev
You need to install the second one because you need the corresponding library to use mysql properly.
After re-executing the install command
sudo pip install MySQL-python
It shows success.
Note: The above environment is Ubuntu 16.04LTS version, for reference only.
Alibaba Cloud has launched the centos8 system. The 8 series is relatively new. By default, the system does not install GIT. If you want to install Yum install git, you can directly report an error of “error: failed to synchronize cache for repo ‘EPEL modular'”, and the extended source reports an error. Baidu has no solution at all, so you can only solve it by yourself
The solution is simple:
Scheme 1: directly delete/etc/yum. Repos. D (backup first)
The file at the beginning of EPEL in the directory
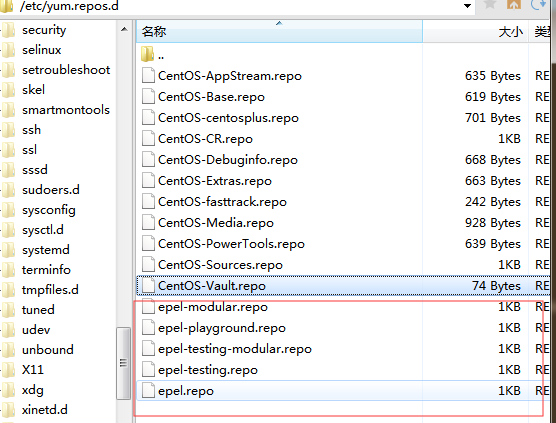
is OK
Scheme 2:
Yum succeeded, but the prompt program does not exist and cannot be installed
Don’t delete the files in/etc/yum. Repos. D
Editor
vi /etc/resolv.conf
Plus
nameserver 114.114.114.114
Save
Execute Yum again successfully
Alibaba cloud recently launched centos8, but the default DNS can’t resolve the domain name of the extension library
**Serious problem: the system sometimes gets stuck and has no response at all * *
look at the kernel log, and the error message is as follows:
kernel BUG at /build/linux-7LGLH_/linux-4.10.0/include/linux/swapops.h:129
It seems that it has something to do with swap.17.04 uses swap file by default, not swap partition
information found: https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1674838
* * solution (effect to be observed): * *
Modify fstab and use swap partition instead
Update (May 10, 2017): swap partition is invalid. Looking at the kernel log, it seems that a deadlock has occurred, with the words of Intel API.
the solution given is
sudo vi /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash intel_idle.max_cstate=1"
sudo update-grub
sudo reboot
For the following problems, check the failed items in the startup log through journalctl – B
NVIDIA driver problem:
nvidia-375, tested driver is installed, but there are a lot of failures in the startup log:
[Failed] Failed to start NVIDIA Persistence Daemon. See 'systemctl status nvidia-persistenced.service' for details.
nvidia-persistenced.service: Failed at step EXEC spawning /usr/bin/nvidia-persistenced: No such file
nvidia-persistenced[12507]: Failed to open libnvidia-cfg.so.1: libnvidia-cfg.so.1: cannot open shared object file: No such file
The files are not found (installation package problem?). Using NVIDIA SMI to view the status also prompts that libnvidia ml cannot be found. So
manual solution:
sudo ln -s /usr/lib/nvidia-375/libnvidia-ml.so.1 /usr/lib/
sudo ln -s /usr/lib/nvidia-375/libnvidia-cfg.so.1 /usr/lib/
sudo ln -s /usr/lib/nvidia-375/bin/nvidia-persistenced /usr/bin
error message: could not parse desktop file orca autostart.desktop or it reference
* * reason: * * Orca was uninstalled because it was not necessary to read on the screen
solution:
sudo rm /usr/share/gdm/greeter/autostart/orca-autostart.desktop
error message: spice-vdagent[1434]: Cannot access vdagent virtio channel /dev/virtio-ports/com.redhat.spice
**Cause:** Desktop machine, not virtual machine
Solution.
sudo vim /usr/share/gdm/greeter/autostart/spice-vdagent.desktop
Add: X-GNOME-Autostart-enabled=fals