We discussed the relationship between Python scope and legb last time
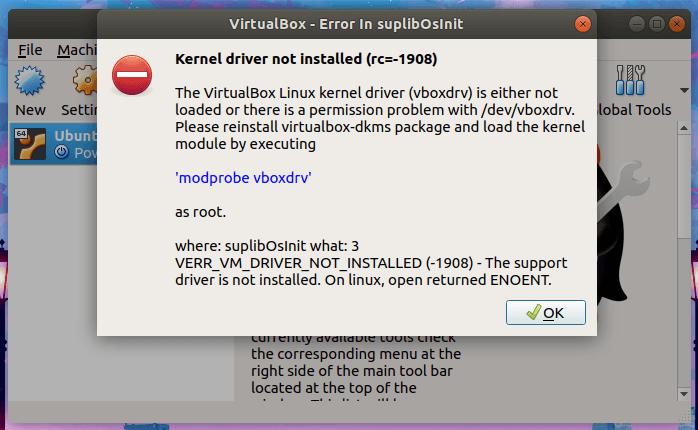
Next, we will discuss the error reporting we often encounter: referenced before assignment
Simple code:
# coding: utf8
a = 3
def f():
print a
a = 4
print a
f()
print '---------------------loop--------------------'
a = 3
def f():
a += 4
print a
f()
No matter the first code or the second code, the following information can be obtained:
UnboundLocalError: local variable 'a' referenced before assignment
Oh ~ no, why did you report an error!! Should be able to get from the global variable ah
In fact, this phenomenon is easy to explain, because although the code execution is sequential, the scope judgment is not. Python uses static scope instead of dynamic scope. In other words, you only need to see from the code body which scope the variable needs to be quoted from
As a result, no matter in the first or second paragraph, python has found the constraint statement for symbol a in the internal scope of the function, so it will not be found from global. However, because the code execution is sequential, the constraint can only be established when the assignment statement is executed. Before that, symbol a can be found in the namespace, but it is undefined
The code a + = 4 seems to be in line with the above, but the reason is that although the code is executed from top to bottom and from left to right, for assignment statements, it is not from left to right, but from right to left
a += 4 ===> A = a + 4 (conversion)
After the above transformation, we can see it more clearly. First, execute a + 4, and then execute the assignment. OK, when executing a + 4, look for a, and find that it can be found in the namespace, but it is not defined, so it will automatically report an error and exit
This problem can be avoided by using global to declare variables in the code, because the global declaration will force Python to search the global namespace, regardless of the legb principle. However, it will also modify the value of global variables. Be careful~