Today’s analytics workloads typically require a data warehouse to be available 24 hours a day, 7 days a week. However, there may be times when you need an Amazon Redshift cluster for a short duration of time at frequent (or infrequent) intervals. For example, you may run a periodic ETL job or use a cluster for testing and development and not use it during off-hours or weekends. In these cases, you may want an easy way to keep the data warehouse up and running only part of the time. Previously, you could accomplish this by making a backup, terminating the cluster, and restoring the cluster from the snapshot. The pause and resume actions on Amazon Redshift are a much simpler way to suspend billing and are designed to use if Amazon Redshift is out of operation for hours at a time and on a regularly scheduled basis.
Pausing a cluster suspends compute and retains the underlying data structures and data so you can resume the cluster at a later point with no data loss. You can configure this through the Amazon Redshift console or the use of Amazon Redshift CLIs.
When the cluster is paused, only the cluster’s storage incurs charges. On-demand compute billing is suspended and resumed on a per-second basis. Paused clusters still appear as an entry in the console. You can also automate the pause and resume actions by using a schedule that matches your operational needs.
Using the actions via the Amazon Redshift console
To use the pause and resume actions on the Amazon Redshift console, complete the following steps:
On the Amazon Redshift console, choose Clusters.
Choose your desired cluster.
Choose Actions.
Choose Pause.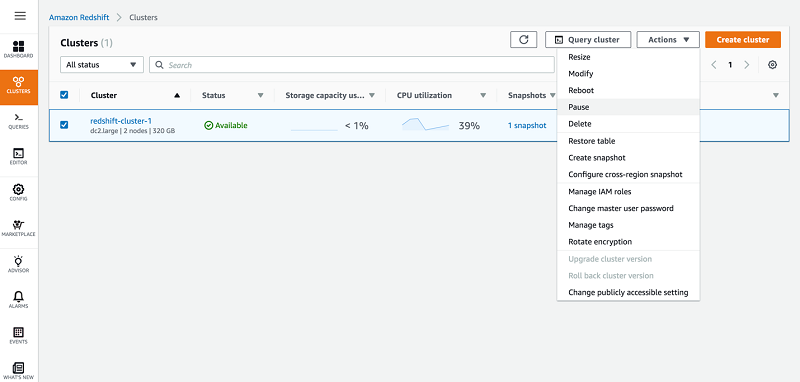
To determine when to pause the cluster, choose from the following three options:
To pause the cluster immediately, select Pause now.
To pause the cluster at a later point, select Pause later.
To pause and resume the cluster according to a set schedule, select Pause and resume on schedule.
For this walkthrough, select Pause now.
Choose Pause now.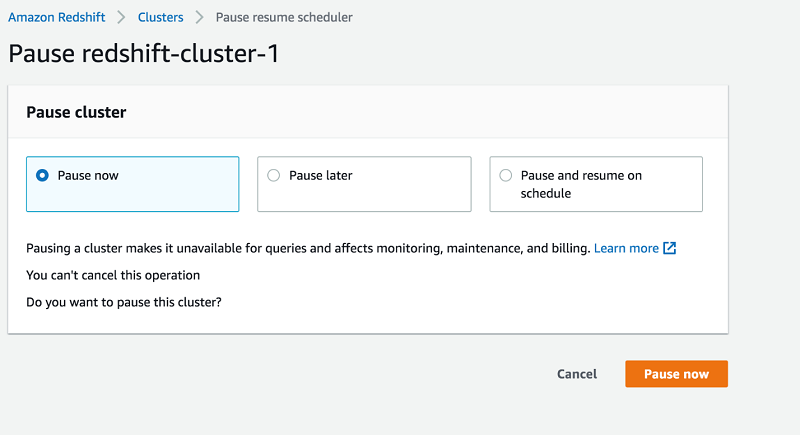
The cluster is now in Modifying status. It can take up to a few minutes for the cluster to change to a Paused state, but the cost accrual for compute resources is suspended immediately.
The following screenshot shows a view of the cluster status.
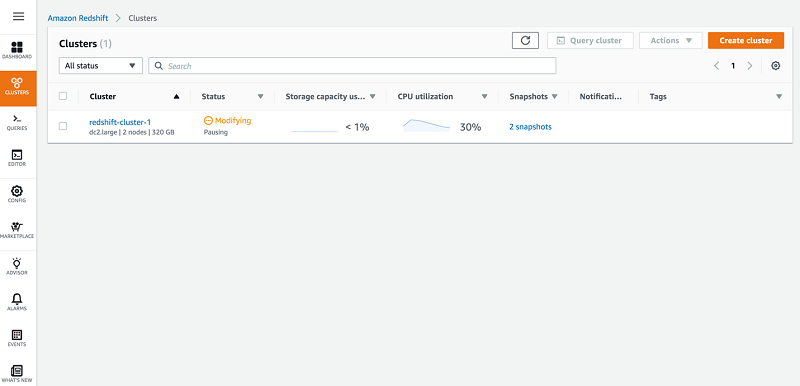
Amazon Redshift processes any outstanding queries before it pauses the cluster. When the cluster is paused, you can still view it on the Amazon Redshift console, and the Resume action is available.
To resume the cluster, complete the following steps:
On the Amazon Redshift console, choose Clusters.
Choose your desired cluster.
Choose Actions.
Choose Resume.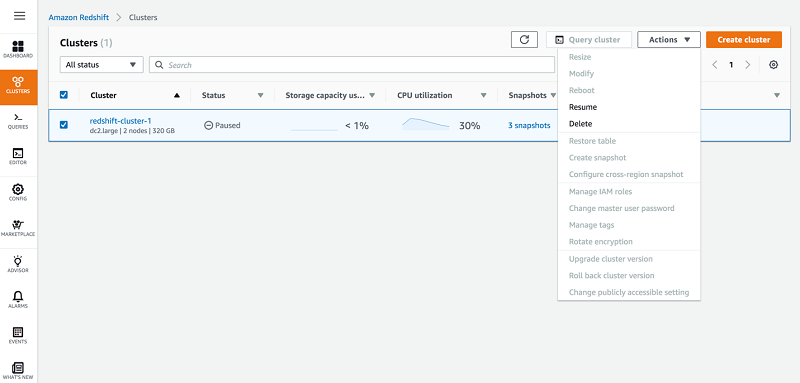
Choose when to resume the cluster. The options are the same as those for the pause action.
For this walkthrough, select Resume now.
Choose Resume now.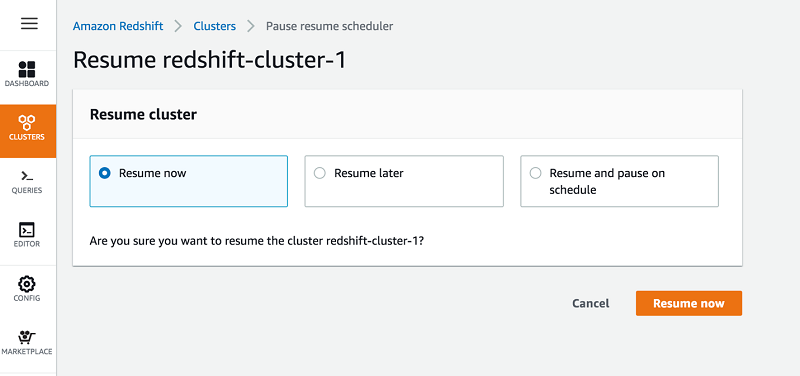
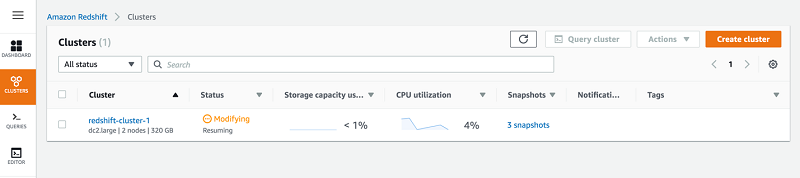
The cluster moves to Modifying status. The time the resume action takes to complete depends on the size of the data and the cluster. It can take 1–30 minutes. Billing only resumes when the cluster is available.
The following screenshot shows the view of the cluster status.
Using the actions via CLI
The following two commands pause and resume the cluster:
Pause-cluster
Resume-cluster
To pause a given cluster, enter the following code:
aws redshift pause-cluster --cluster identifier <insert cluster identifier here>
To resume a paused cluster, enter the following code:
aws redshift resume-cluster --cluster identifier <insert cluster identifier here>
Scheduling pause and resume actions
You can schedule to pause and resume a cluster at specific times of the day and week. For example, this walkthrough pauses a cluster on Friday 8:00 p.m. and resumes it on Monday 7:00 a.m. You can configure this via the Amazon Redshift console or APIs.
Scheduling via the Amazon Redshift console
To schedule to pause and resume a cluster on the Amazon Redshift console, complete the following steps:
On the Amazon Redshift console, choose Clusters.
Choose your desired cluster.
Choose Actions.
Choose Pause.
Select Pause and resume on schedule.
For Schedule name, enter a name for this schedule.
Optionally, for Starts on and Ends on, enter the dates and times to start and end the schedule.
For Pause every and Resume every, choose the time and day to pause and resume.
Choose Schedule recurring pause and resume.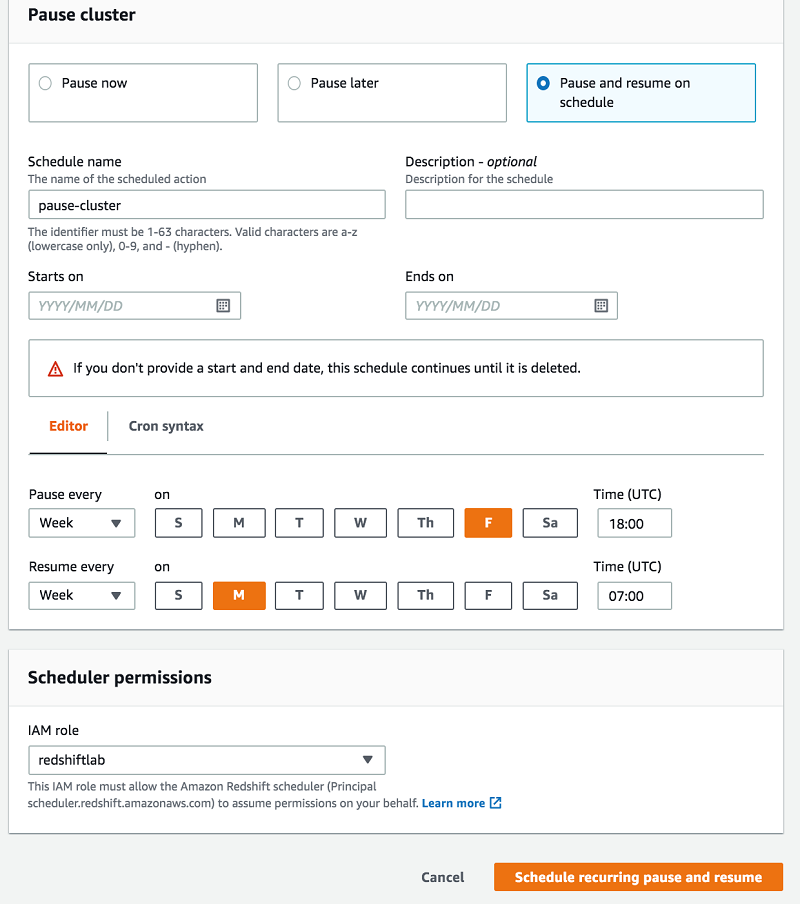
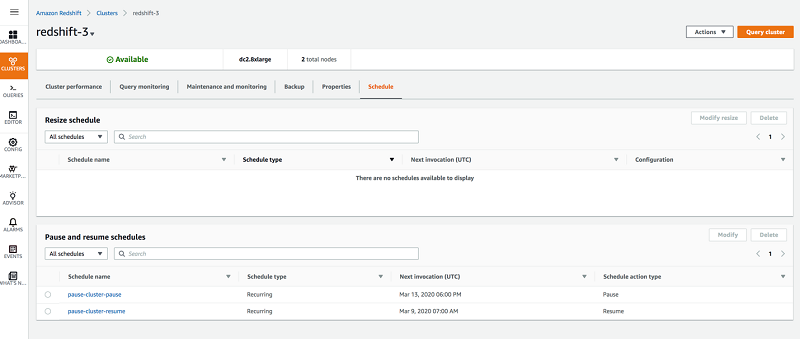
You can review existing pause and resume schedules on the Schedules tab. See the following screenshot.
Scheduling via CLI
The following CLI commands allow you to create, modify, and delete scheduled pause and resume tasks.
To create a scheduled action to occur one time, enter the following code:
aws redshift create-scheduled-action --scheduled-action-name test-resume --schedule "at(2020-02-21T02:00:00)" --target-action "{\"ResumeCluster\":{\"ClusterIdentifier\":\"redshift-cluster-1\"}}" --iam-role arn:aws:iam::<Account ID>:role/<Redshift Role>To create a recurring scheduled action, enter the following code:
aws redshift create-scheduled-action --scheduled-action-name "scheduled-pause-repetitive" --target-action "{\"PauseCluster\":{\"ClusterIdentifier\":\"redshift-cluster-1\"}}" --schedule "cron(30 20 * * ?*)" --iam-role "arn:aws:iam::<Account ID>:role/<Redshift Role>"The preceding code example pauses a cluster daily at 10:30 p.m.
To modify an existing scheduled action, enter the following code:
aws redshift modify-scheduled-action --scheduled-action-name "scheduled-pause-repetitive" --schedule "cron(30 * * * ?*)"The preceding code example modifies the scheduled-pause-repetitive schedule to run every hour at 30 minutes past the hour.
To delete a scheduled action, enter the following code:
aws redshift delete-scheduled-action --scheduled-action-name "scheduled-pause-repetitive"Summary
The pause and resume actions on Amazon Redshift allow you to easily pause and resume clusters that may not be in operation all the time. Flexible on-demand pricing and per-second billing gives you greater control of costs for clusters. You can run your data warehouse at the lowest cost possible without having to purchase a fixed amount of resources up-front. Amazon Redshift continues to raise the bar for data warehouse users by continually adding more enhancements like pause and resume to empower you to do more with your data at a lower cost.
Similar Posts:
- Aurora PostgreSQL Disaster Recovery solutions using Amazon Aurora Global Database
- At 00:00 every day, MySQL regularly pops up a taskeng.exe
- JS Uncaught TypeError: Cannot read property ‘toLowerCase’ of undefined
- [Solved] Redis Cluster: (error) CLUSTERDOWN The cluster is down
- [Solved] The Tomcat connector configured to listen on port 80 failed to start. The port may already be in use or the connector may be misconfigured.
- [Three Method] Multiple actions were found that match the request in Web Api
- Hive Error: Error while compiling statement: FAILED: ParseException line 1:7 Failed to recognize
- [Solved] cookie loss when uploading components using the elementui framework El upload
- error LNK2019: unresolved external symbol _WinMain@16 referenced in function ___tmainCRTStartup