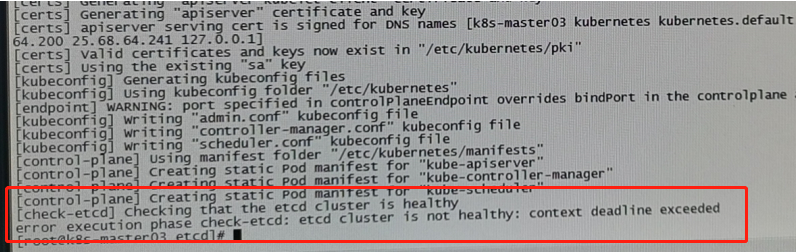
Zookeeper is based on the simplified version of Zab of Paxos, etcd is based on raft algorithm, and consumer is also based on raft algorithm. Etcd and consumer, as rising stars, did not abandon themselves because they already had zookeeper, but adopted a more direct raft algorithm.
The number one goal of raft algorithm is to be easy to understand, which can be seen from the title of the paper. Of course, raft enhances comprehensibility, which is no less than Paxos in terms of performance, reliability and availability.
Raft more understandable than Paxos and also provides a better foundation for building practical systems
in order to achieve the goal of being easy to understand, raft has made a lot of efforts, the most important of which are two things:
problem decomposition
State simplification
problem decomposition is to divide the complex problem of “node consistency in replication set” into several subproblems that can be explained, understood and solved independently. In raft, subproblems include leader selection, log replication, safety and membership changes. The better understanding of state simplification is to make some restrictions on the algorithm, reduce the number of States to be considered, and make the algorithm clearer and less uncertain (for example, to ensure that the newly elected leader will contain all the commented log entries)
Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machines. A leader can fail or become disconnected from the other servers, in which case a new leader is elected.
the above quotation highly summarizes the working principle of raft protocol: raft will select the leader first, and the leader is fully responsible for the management of replicated log. The leader is responsible for accepting all client update requests, copying them to the follower node, and executing them when “safe”. If the leader fails, followers will re elect a new leader.
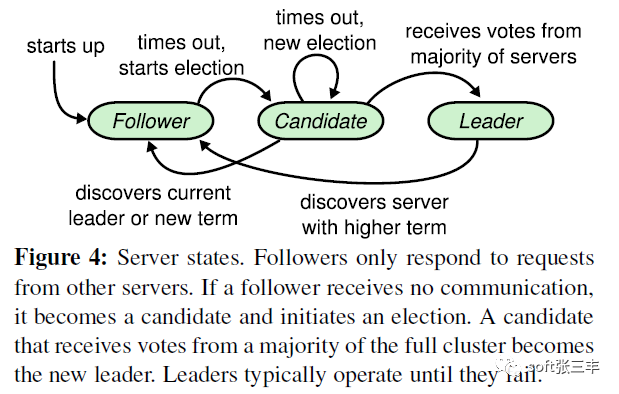
this involves two new subproblems of raft: Leader Selection and log replication
leader election
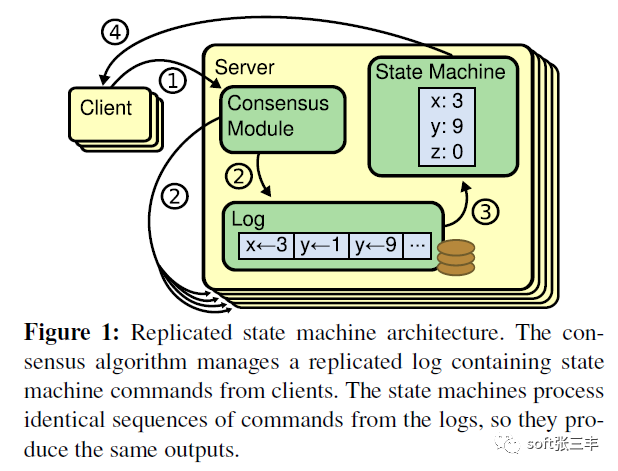
log replication
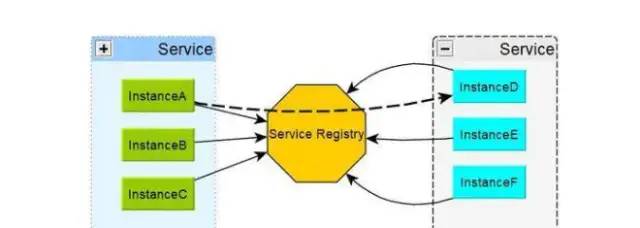
Here is a comparison of the following features of service discovery products that are often used. First of all, let’s look at the following conclusions:
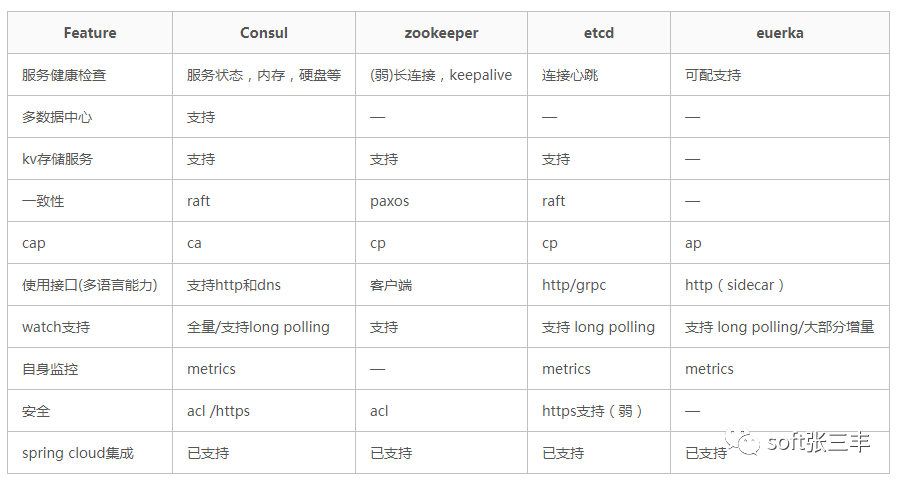
Health check of service
Euraka needs to explicitly configure health check support when it is used; zookeeper and etcd are not healthy when they lose the connection with the service process, while consult is more detailed, such as whether the memory has been used by 90% and whether the file system is running out of space.
Multi data center support
Consul completes the synchronization across data centers through Wan’s gossip protocol, and other products need additional development work
KV storage service
In addition to Eureka, several other products can support K-V storage services externally, so we will talk about the important reasons why these products pursue high consistency later. And providing storage services can also be better transformed into dynamic configuration services.
The choice of cap theory in product design
Eureka’s typical AP is more suitable for service discovery in distributed scenarios. Service discovery scenarios have higher availability priority and consistency is not particularly fatal. Secondly, CA type scenario consul can also provide high availability and ensure consistency of K-V store service. Zookeeper and etcd are CP types, which sacrifice availability and have little advantage in service discovery scenarios
Multilingual capability and access protocol for external services
Zookeeper’s cross language support is weak, and other models support http11 to provide access. Euraka generally provides access support for multilingual clients through sidecar. Etcd also provides grpc support. In addition to the standard rest Service API, consul also provides DNS support.
Watch support (clients observe changes in service providers)
Zookeeper supports server-side push changes, and Eureka 2.0 (under development) also plans to support it. Eureka 1, consul and etcd all realize change perception through long polling
Monitoring of self cluster
In addition to zookeeper, other models support metrics by default. Operators can collect and alarm these metrics information to achieve the purpose of monitoring
Safety
Consul and zookeeper support ACL, and consul and etcd support secure channel HTTPS
Integration of spring cloud
At present, there are corresponding boot starters, which provide integration capabilities.
In general, the functions of consul and the support of spring cloud for its integration are relatively perfect, and the complexity of operation and maintenance is relatively simple (there is no detailed discussion). The design of Eureka is more in line with the scene, but it needs continuous improvement.
Etcd and zookeeper provide very similar capabilities, and their positions in the software ecosystem are almost the same, and they can replace each other.
They are universal consistent meta information storage
Both provide a watch mechanism for change notification and distribution
They are also used by distributed systems as shared information storage
In addition to the differences in implementation details, language, consistency and protocol, the biggest difference lies in the surrounding ecosystem.
Zookeeper is written in Java under Apache and provides RPC interface. It was first hatched from Hadoop project and widely used in distributed system (Hadoop, Solr, Kafka, mesos, etc.).
Etcd is an open source product of coreos company, which is relatively new. With its easy-to-use rest interface and active community, etcd has captured a group of users and has been used in some new clusters (such as kubernetes).
Although V3 is changed to binary RPC interface for performance, its usability is better than zookeeper.
While the goal of consul is more specific. Etcd and zookeeper provide distributed consistent storage capacity. Specific business scenarios need to be implemented by users themselves, such as service discovery and configuration change.
Consul aims at service discovery and configuration change, with kV storage.
In the software ecology, the more abstract the components are, the wider the scope of application is, but there must be some shortcomings in meeting the requirements of specific business scenarios.
——————-Message middleware rabbitmq
Message middleware rabbitmq (01)
Message middleware rabbitmq (02)
0
Message middleware rabbitmq (03)
0
Message middleware rabbitmq (04)
0
Message middleware rabbitmq (05)
Message middleware rabbitmq (06)
0
Message middleware rabbitmq (07)
———————- cloud computing————————————-
Cloud computing (1) — docker’s past and present life
Cloud computing (2) — Architecture
Cloud computing (3) — container applications
Cloud computing (4) — lamp
Cloud computing (5) — dockerfile
cloud computing (6) — harbor
Add wechat to the wechat communication group of wechat service, and note that wechat service enters the group for communication

pay attention to official account soft Zhang Sanfeng

this article is shared by WeChat official account – soft Zhang Sanfeng (aguzhangsanfeng).
In case of infringement, please contact [email protected] Delete.
This article participates in the “OSC source creation program”. You are welcome to join and share.