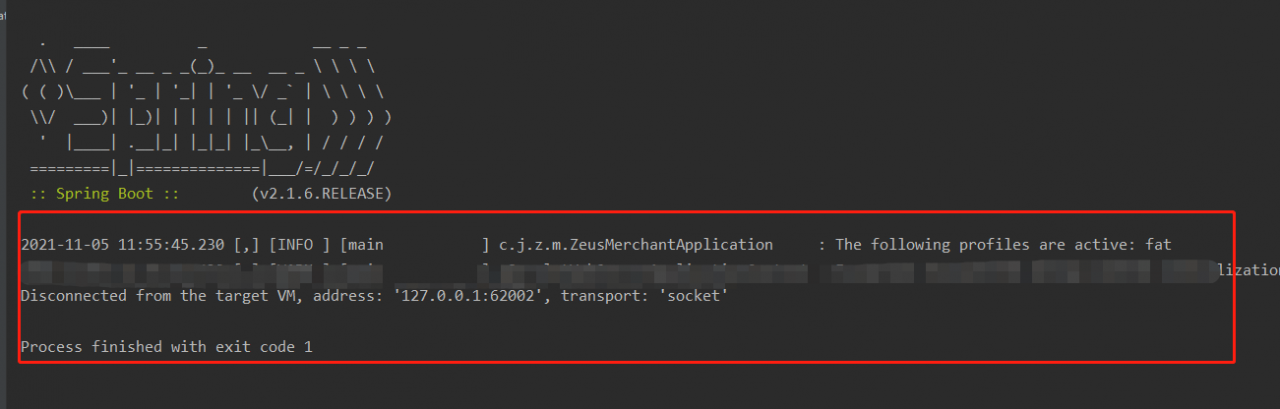
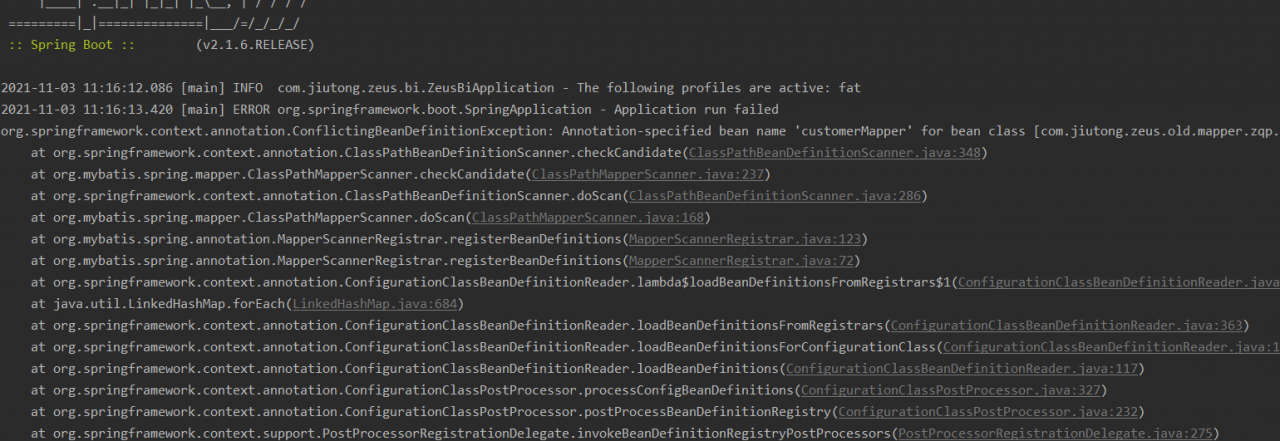
After kubectl delete ns XXXX, the namespace is always in the terminating state.
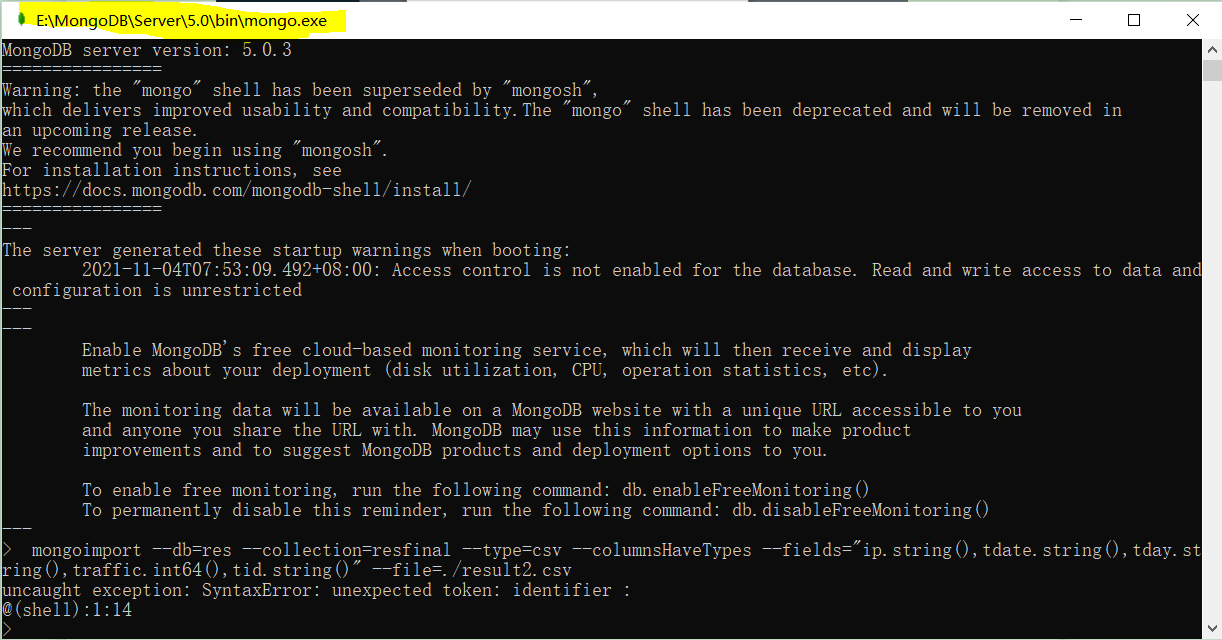
Use: kubectl delete ns monitoring — grace period = 0 – force cannot be deleted
Error message:
warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
Error from server (Conflict): Operation cannot be fulfilled on namespaces ” monitoring “: The system is ensuring all content is removed from this namespace. Upon completion, this namespace will automatically be purged by the system.
Solution:
1. Export namespace information
kubectl get namespace monitoring -o json > monitoring.json
2. Delete the contents under spec in JSON file
The purpose of this step is to clear the content and overwrite the original ns with the ns of the empty content, so as to ensure that the NS content to be deleted is empty and the deletion command cannot be blocked
3. Overlay the empty namespace into the k8s cluster through the API server interface
curl -k -H “Content-Type: application/json” -X PUT –data-binary @monitoring.json http://127.0.0.1:8081/api/v1/namespaces/monitoring/finalize
4. For clusters without authentication, you can perform steps 1-3. For those with authentication, you need to use Kube proxy to proxy:
Open k8s two windows of the master node,
Execute kubectl proxy in one window
Execute in another window: curl – K – H “content type: application/JSON” – x put — data binary @ monitoring.json http://127.0.0.1:8081/api/v1/namespaces/monitoring/finalize
There was no error in the G + + compilation process, and the EXE file was successfully generated. However, when running the EXE file, an error will be reported as soon as it runs.
Solutions: (libstdc++-6.dll)
In the MinGW/bin directory you downloaded, there is a file called libstdc + + – 6.dll. Find it and right-click to copy it
Underdrive C, find the system folder (you can enter the name of the folder to find it, that is, the “search…” box in the upper right corner of the file system), paste a copy into it, you need administrator permission, and click OK
Underdrive C, find the syswow64 folder (64-bit computer), paste a copy into it, and you need administrator permission. Click OK
Some error reports do not display error information
Not directly displayed, suddenly interrupted.
If the parent public resource is referenced, the error message will be displayed when the project is added again. After deletion, the error message will still be displayed
Colleagues make errors when importing data, and simply record them.
1. An error occurs when impdp imports data. The error information is as follows:
ORA-39014: One or more workers have prematurely exited.
ORA-39029: worker 7 with process name “DW0M” prematurely terminated
Ora-31684: object type procedure: “ADM”. AAAAA “already exists from the error message, it can be seen that the parallel imported process (worker 7) exited due to an error. The reason for the error is ora-31684: object type procedure:” ADM “. AAAAA” already exists. Under normal circumstances, if it is a clean environment, it is impossible to report an error such as object already exists when importing data.
2. The import script is as follows:
DIRECTORY=dpdir
LOGFILE=impdp_ adm_ 20211101.log
cluster=n
dumpfile=expdp_ adm_% U.dmp
parallel=8
JOB_ NAME=impdp_ ADM there are no special parameters in the import script, but parallelism is enabled, that is, the parallel parameter is used. The above ora-31684: object type procedure: “ADM”. AAAAA “already exists error. It is suspected that the parallel process of impdp has repeatedly done the same thing.
3. Ask colleagues to remove the parallel parameter during impdp. After a period of time, feedback that the import is successful. This indicates that this problem is caused by the parallel parameter.
4. Search MOS and find the document: errors ora-39014 ora-39029 ora-31672 on datapump import (DOC ID 464082.1), which mentions:
The parallelism (specified with parameter PARALLEL) should be less than or equal to the number of dump files in the dump file set. If there are not enough dump files, the performance will not be optimal because multiple threads of execution will be trying to access the same dump file.
In this case, parallel = 8 is used when exporting the source library, and the parallel specified when importing the target library is also 8, but an error is reported. Even if the parallel is changed to 4, an error is also reported, indicating that it is not involved in this document.
5. There are many bugs about ora-39014 or ora-39029 in the expdp or impdp times on MOS, but there are few bugs covering version 19.12. Only bug30477767 – ora-02095 and worker crashes during import when using parallel parameter (DOC ID 30477767.8) can be found. We can’t see the details of this bug on MOS, and we can’t finally confirm it.
6. Finally, colleagues can only remove the parallel parameter during impdp as the workaround of this case.
I trained a model with GPU. I want to make an error when loading the test locally (only CPU):
raise RuntimeError('Attempting to deserialize object on a CUDA '
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.
According to the prompt, add to torch. Load() map_ Location = torch. Device ('cpu ') parameter
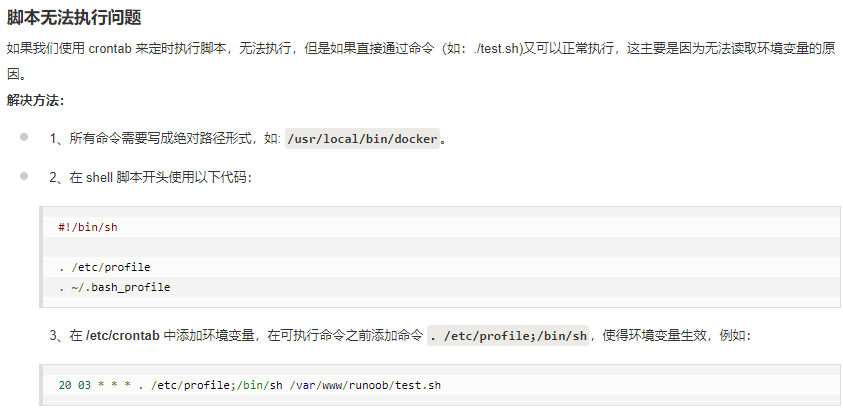
We can execute the script directly, but using cron has no effect. If you check the log (/ var/log/cron), an error will be reported by orphan (no passwd entry)
Reason: environment variable
Solution
1. All commands need to be written in absolute path form, such as:/usr/local/bin/docker.
2. Use the following code at the beginning of the shell script:
#!/bin/sh
. /etc/profile
. ~/.bash_profile
3. Add environment variables in/etc/crontab, and add the command./etc/profile before the executable command/ Bin/sh to make the environment variable effective, for example:
When using the mybatis plus plug-in to interact the springboot project with the MySQL database, the list & lt; object> The type is directly put into the database through the user-defined converter, and the display is successful. However, in the add operation of the list, the unsupported operationexception is returned,
Specific reasons:
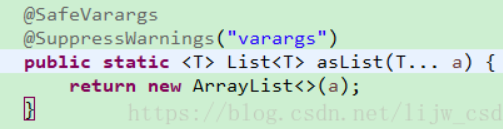
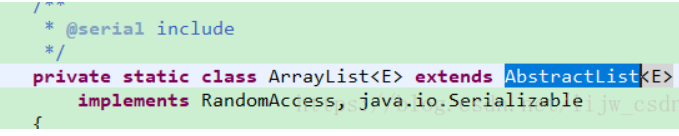
The ArrayList in the source code of arrays.aslist in the figure above is not our commonly used ArrayList. Our commonly used ArrayList is java.util.arraylist, while the new in the figure above is java.util.arrays.arraylist, which is an internal class under the arrays class. Its class declaration is as follows:
It can be seen that both it and java.util.arraylist inherit from the abstractlist abstract class, but it does not implement the add method and remove method. When we call the add method, it actually calls the add method of the parent abstractlist.
Add calls the add method with two parameters.
Then you will see throw new unsupported operationexception();
Solution:
To solve the above problem, just put the list into Java. Util. ArrayList, list & lt; Integer> Lists = new ArrayList (list), and then you can use lists to do various operations. Programmers should be careful and look at the source code